























































In our first benchmark, we showed that JSL Vision OCR is the #1 grounded OCR model overall, beating every closed-source frontier system on the FUNSD dataset.
This post answers a different question: plain-text OCR.
Many enterprise workflows don’t need bounding boxes. Search indexing, clinical summarization, RAG pipelines, compliance audits, downstream LLM reasoning, all they need is clean, human-readable text in natural reading order.
So how does JSL Vision ( jsl_vision), our 30B-class flagship OCR model, compare to GPT-5.2, Claude 4.5, Gemini 2.5, Grok-4, and the rest of the frontier?
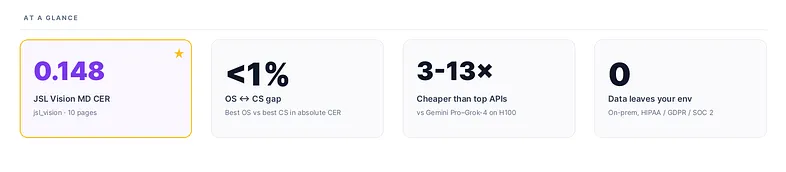
Short answer: it wins. And the gap between the best self-hosted VLM and the best closed-source API is less than 1% absolute CER. On plain-text OCR, accuracy alone is no longer a reason to send your documents to a third-party cloud.
What “markdown OCR” looks like
Input on the left, JSL Vision’s reading-order text output on the right:

No bounding boxes, no JSON fields, no layout metadata, just clean text in the order a human would read it. That’s the unit of work for RAG, search indexing, and clinical summarization.
No bounding boxes, no JSON fields, no layout metadata, just clean text in the order a human would read it. That’s the unit of work for RAG, search indexing, and clinical summarization.
What we measured
- Dataset: FUNSD training pages, 50 pages for closed-source models, 10 pages for open-source VLMs (GPU-constrained, see methodology)
- Metric: character-level CER via jiwer.cer() on full-page text
- Ground truth: word-level FUNSD annotations reassembled into line-level reading order (top-left → bottom-right), lowercased, whitespace-normalized
- Predictions: preprocessed identically (strip markdown tables, collapse whitespace, lowercase) before scoring
Who leads the field

jsl_vision wins outright at 0.148 CER. Grok-4 and Gemini 2.5 Pro are close behind (0.155 and 0.167). The fact that the top-3 spread is < 0.02 absolute CER is itself the headline: OCR has converged.
How all 16 models compare
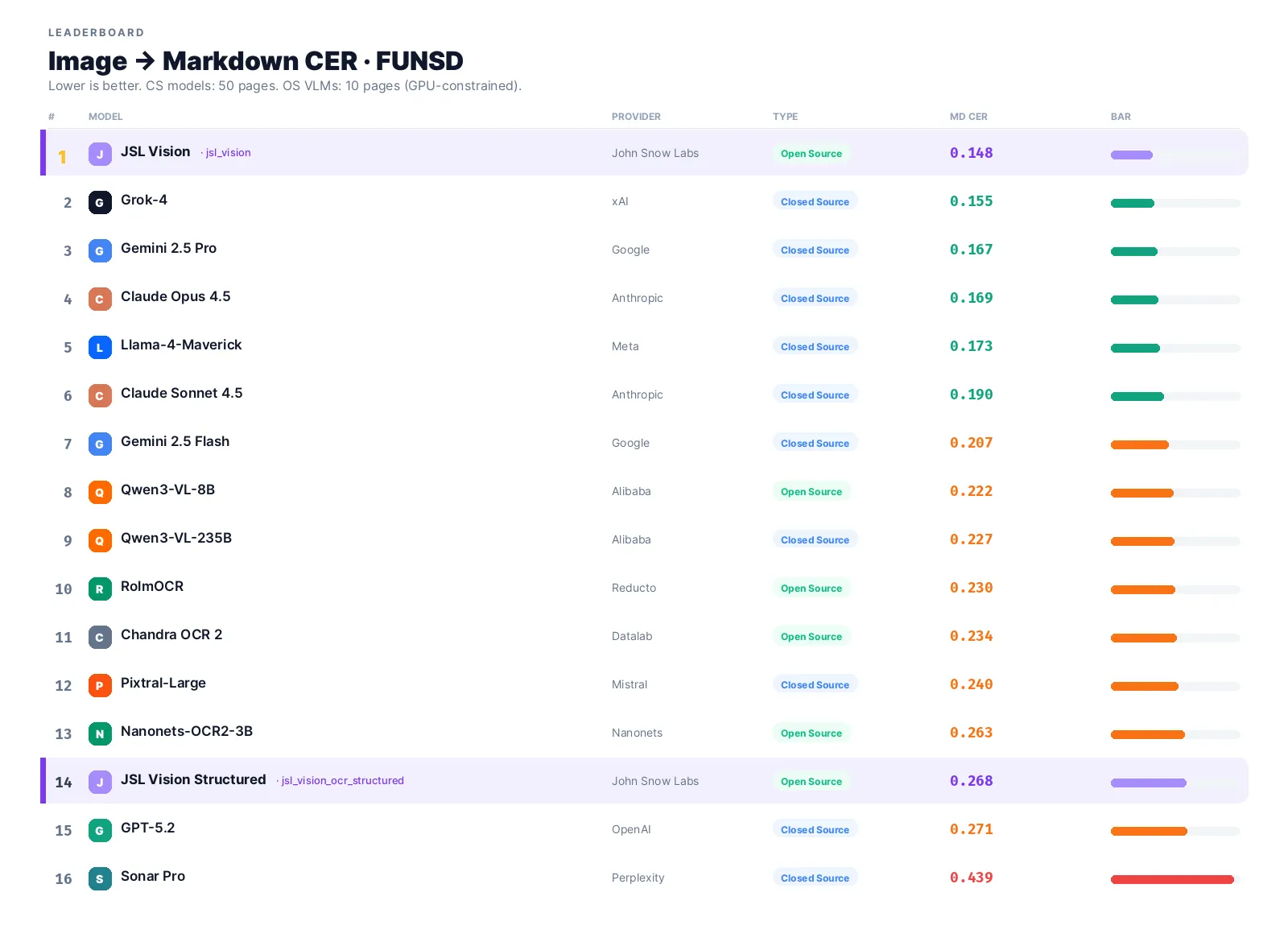
The self-hosted ↔ cloud gap has effectively closed. JSL Vision (0.148 CER) outperforms the best closed-source API (Grok-4, 0.155) by 4.5% relative, running entirely on your own hardware.
Even setting JSL Vision aside, open-source VLMs now produce OCR quality that’s practically indistinguishable from GPT-5.2, Claude, or Gemini on plain-text tasks. For clinical summarization, search indexing, and RAG pipelines, there’s no accuracy reason left to send documents to a closed-source API.
The data breaks down in a few ways that matter:
GPT-5.2 underperforms on OCR. It landed at 0.271 CER, last of 16 in the leaderboard. This mirrors what we saw in the BBox benchmark (GPT-5.2 scored 0.588 on grounded OCR, essentially random). GPT-5.2 is a capable general-purpose model, but not competitive as a dedicated OCR engine.
Grok-4 is a surprising standout. On flat text, Grok-4 (0.155) ranks #2 overall. This is very different from its BBox performance (0.582, near the bottom). The takeaway: Grok-4 reads well but can’t ground what it reads. If you need spatial coordinates, don’t use it.
Smaller open-source models are competitive. Qwen3-VL-8B (8B parameters, 0.222 CER) outperforms the 235B closed-source Qwen3-VL-235B (0.227) and GPT-5.2 (0.271). A well-tuned sub-10B model can match frontier APIs on OCR.
Cost vs accuracy: where the real gap shows up
If accuracy is a wash, the real comparison is cost. Plotting CER against cost per 1,000 documents:
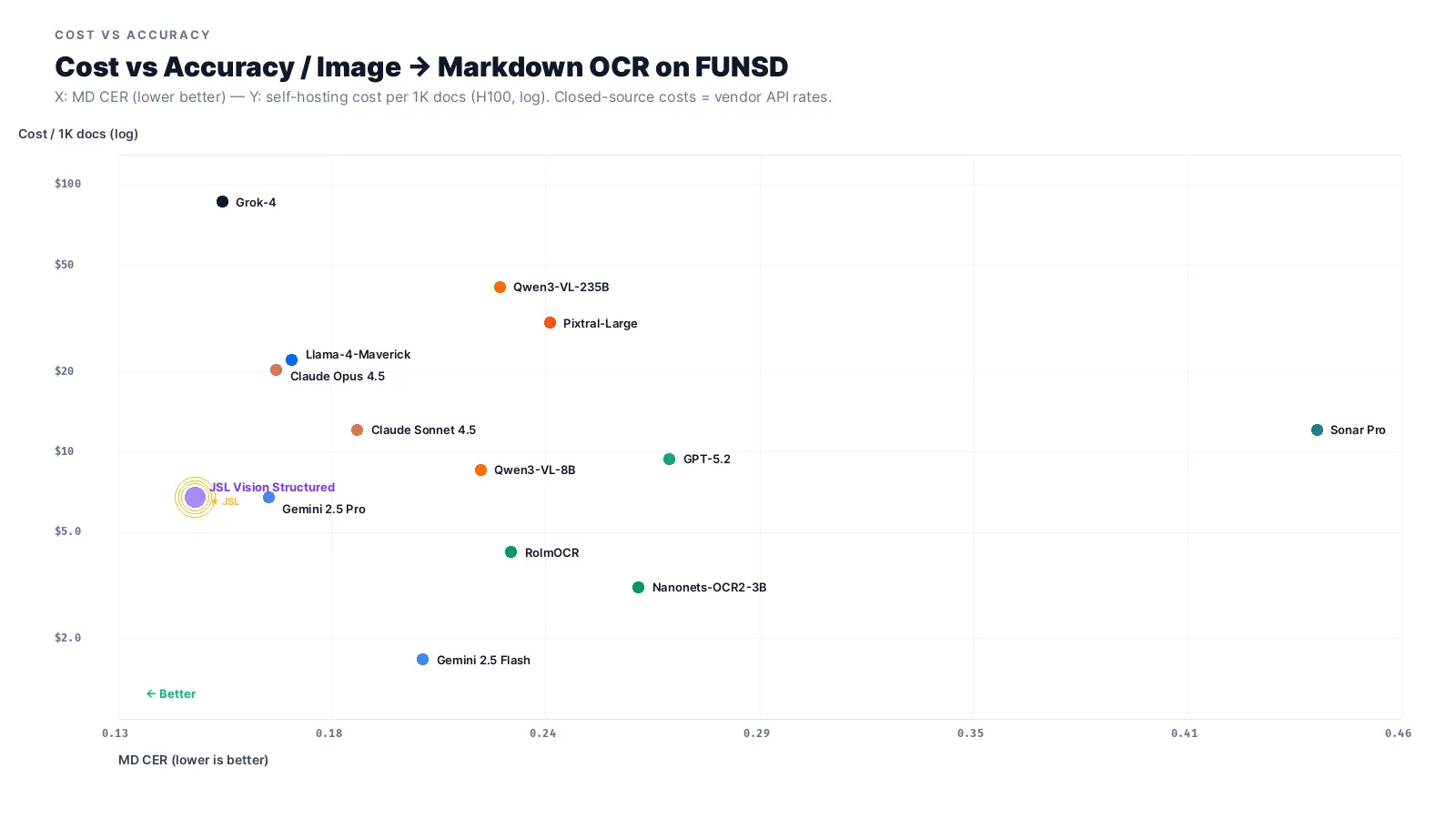
JSL Vision wins outright on accuracy. For the 30B flagship: $6.76 per 1K docs on H100 (9.7 seconds per page). For the 1B jsl_vision_ocr: $0.56 per 1K docs on T4. Gemini 2.5 Pro costs roughly $6.75 per 1K on this task with worse accuracy and no on-prem option. Grok-4 runs $86.70 per 1K. Llama-4-Maverick is similarly competitive on flat text, but its 400B MoE architecture requires 4× H100s to self-host, making it ~3× more expensive than JSL Vision at production scale. As we’ll see in the JSON-Schema benchmark, it also falls apart on structured extraction tasks.
Document processing speed
For batch ingest and interactive workflows, time-to-result matters as much as accuracy:
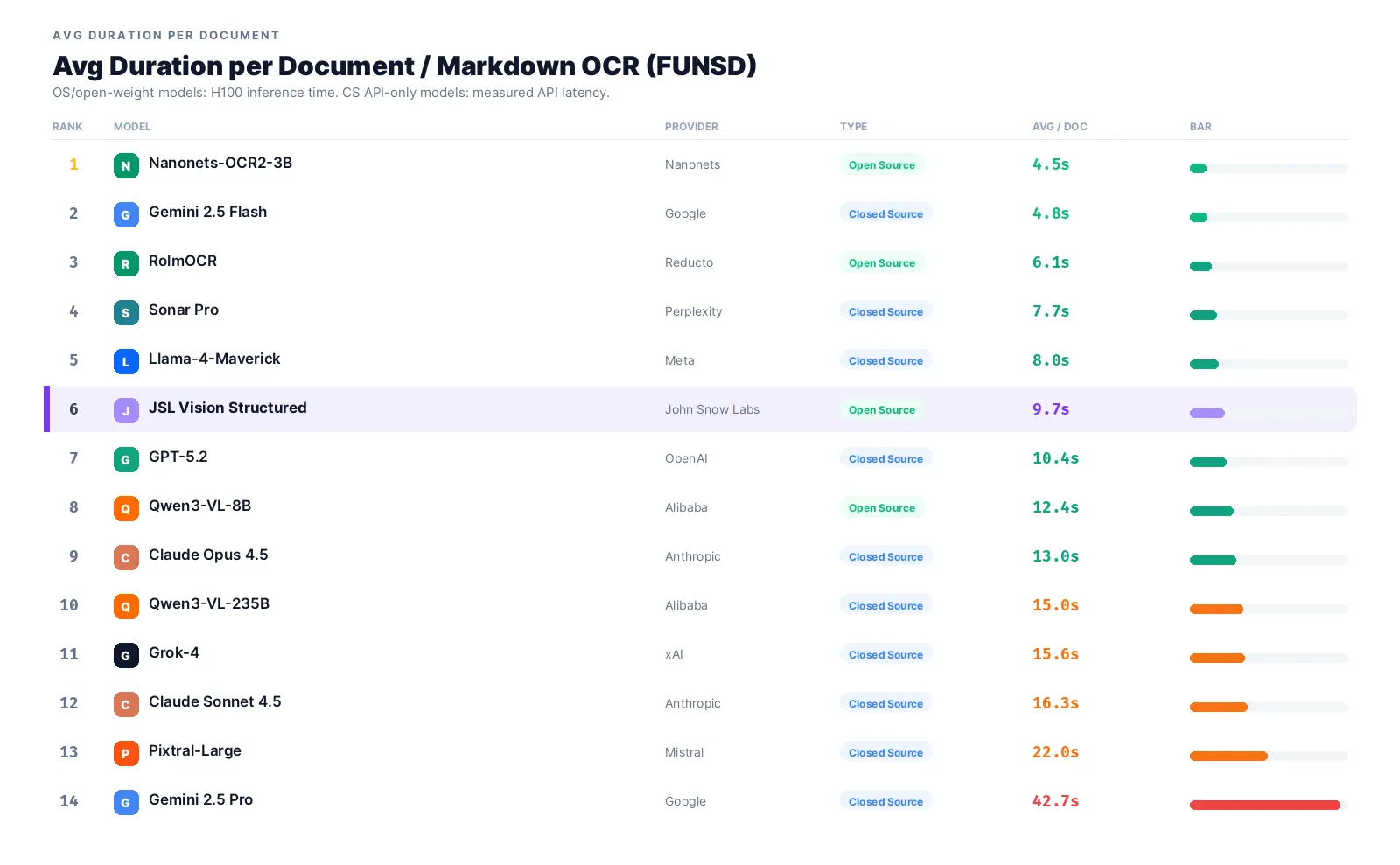
JSL Vision at 9.7 seconds per page is mid-pack. Some closed-source models are faster on flat text (Llama at 3.2s, Gemini Flash at 4.8s) but lose on accuracy or break on schema-following. For pure-OCR latency, the 0.4B jsl_vision_ocr model runs at 1.8s per page (see Article 1).
A single H100 at $2.50/hour processes pages at a tiny fraction of frontier-API cost, and that’s before accounting for the operational cost of sending your documents to a third-party service: data-processing agreements, audit trails, latency tails, and the occasional 3 AM page when someone else’s API goes down.
GPU vs CPU: does the hardware gap matter?
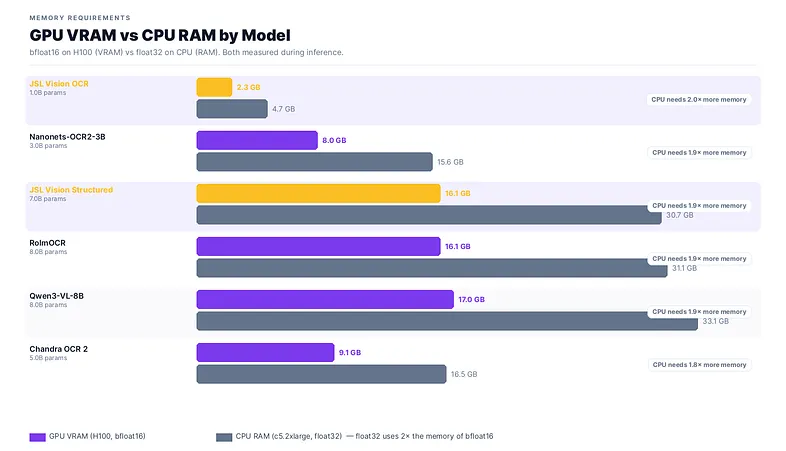
Not every deployment has a GPU. We ran all major OS OCR models on both an NVIDIA H100 and a standard CPU instance (c5.2xlarge, 8 vCPUs) using HF transformers at float32. Same 5 FUNSD pages, same prompts.
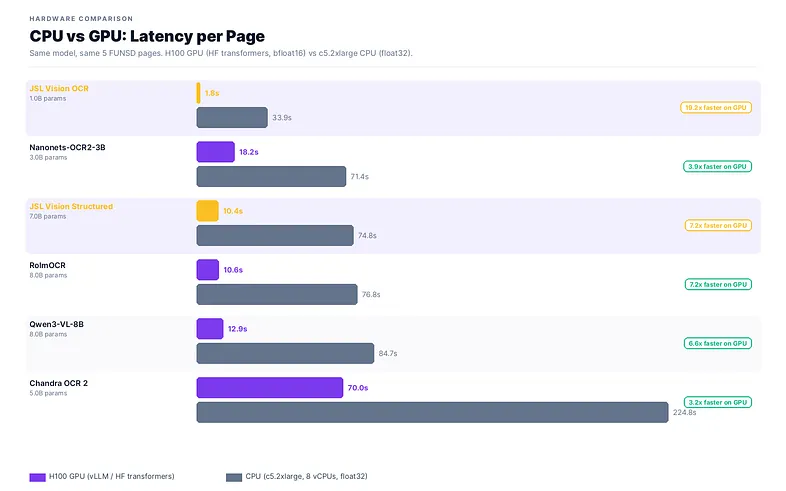
GPU delivers 2–7× faster throughput per page across model sizes. The advantage grows with parameter count; 7–8B models peak at 7.2×.
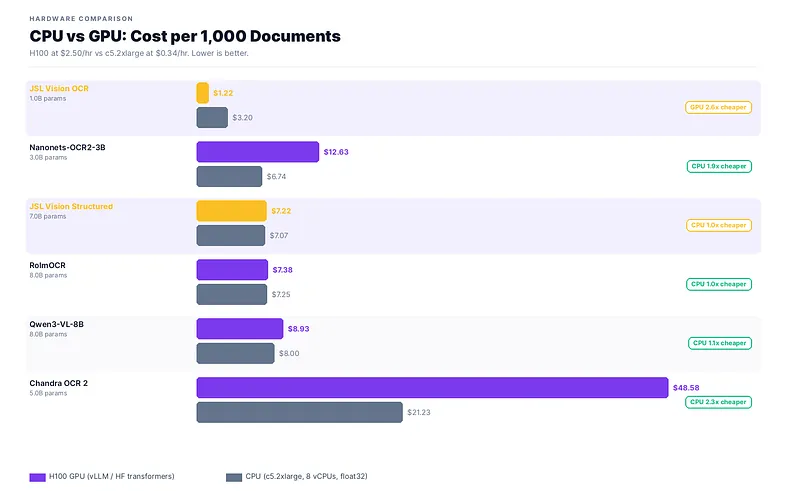
CPU is cheaper per document for every model in the benchmark. CPU compute at $0.34/hr is ~7× cheaper than H100 at $2.50/hr, and even a 7× slower CPU page still comes out ahead on cost. At 7–8B, GPU and CPU land within 2% of each other per document. The latency advantage of GPU is real; the cost advantage of CPU is marginal. JSL Vision OCR via vLLM at $1.22/1K docs beats every CPU option on both speed and cost simultaneously.
Built for regulated industries
JSL Vision runs on your own hardware: Docker or Amazon SageMaker, from a single T4 (1B model) to an H100 (30B model), no minimum cluster size. HIPAA, GDPR, and SOC 2 compliance follow from the architecture since there’s no API call, no data egress, and no data-sharing agreement to negotiate with a vendor. Outputs are deterministic: the same document produces the same output every run, every deployment, every environment. Input can be any image-convertible format: PDF, PNG, JPG.
How we ran the benchmark
- Dataset: FUNSD. Reading order via line-level reassembly of word-level FUNSD annotations.
- Metric:
jiwer.cer(gt, pred)at the corpus level, after consistent preprocessing (lowercase, strip markdown separators, collapse whitespace). - Closed-source models: OpenRouter
temperature=0,max_tokens=8192. - Open-source models: vLLM v0.17.1, H100, f16 precision.
- Sample sizes: Closed-source at 50 pages (cheap via API). Open-source VLMs at 10 pages, extending to 50 requires GPU time we’ll publish in a follow-up. OS numbers are directionally stable.
- Outliers: Ministral-14B produced a 34× length-explosion gen-loop on one page (63 k chars vs 1.8 k GT) that inflated its corpus CER to 1.63 with median page CER of 0.28. It is omitted from the leaderboard; the gen-loop behavior is real and worth knowing about for production deployments.
What’s next
This is the second of a three-part series:
- Grounded (BBox) OCR on FUNSD
- Image → Markdown OCR on FUNSD, you are here
- Schema-Constrained JSON OCR on OmniOCR
The accuracy gap between self-hosted and cloud APIs on plain OCR has closed. If your pipeline is still routing documents to a third-party API for flat-text extraction, you’re paying for API risk, data agreements, and latency uncertainty. Not accuracy.
Replacing a third-party OCR API or standing up a document ingestion pipeline? Schedule a demo to see JSL Vision running on your own data.




