






















































In assigning ICD10-CM codes, Spark NLP for Healthcare achieved a 76% success rate, while GPT-3.5 and GPT-4 had overall accuracies of 26% and 36% respectively.
Introduction
In the healthcare industry, accurate entity resolution is crucial for various purposes, including medical research, data analysis, and billing. One widely used terminology in clinical settings and hospitals is ICD10-CM (International Classification of Diseases, Tenth Revision, Clinical Modification). ICD10-CM is a system of diagnostic codes that helps classify diseases, medical conditions, and procedures, enabling standardized communication across healthcare providers and systems.
The ICD10-CM terminology comprises over 70,000 codes that represent various diseases, medical conditions, and procedures. Accurate entity resolution, or the process of mapping clinical entities to the correct ICD10-CM codes, is vital in clinical settings and hospitals for several reasons. First, it ensures that patients receive proper care based on their diagnoses. Second, it facilitates accurate billing and reimbursement processes. Lastly, it helps in aggregating and analyzing healthcare data for research, policy assessments, and quality improvement initiatives. However, the sheer number of codes and the complexity of medical language make it challenging to assign the right ICD10-CM code consistently.
However, finding the right ICD10-CM code for a specific medical condition or problem can be challenging, as the same disease or condition can be described in different ways or have various interpretations. In this blog post, we will compare Spark NLP for Healthcare and ChatGPT in their ability to extract ICD10-CM codes from clinical notes.
A key trend shaping the current landscape is the integration of multimodal medical data into NLP systems. Beyond text, hospitals are increasingly combining structured notes with imaging reports, lab results, and even genomic data. This holistic approach improves the precision of entity resolution and diagnostic coding, reducing ambiguity when similar conditions are described in different forms. Recent pilots have shown that combining NLP pipelines with imaging annotations improves accuracy in oncology coding and accelerates clinical trial recruitment.
Another important development is the rise of continual learning in healthcare NLP. Instead of relying on static models, new approaches allow systems like Spark NLP to adapt dynamically as new medical terms, treatment guidelines, and emerging diseases appear. For example, entity resolution pipelines have begun incorporating adaptive retraining strategies that update ICD mappings when new clinical variants are observed. This evolution ensures that models remain aligned with the latest medical standards without requiring complete retraining from scratch.
Finally, there has been a strong push toward explainable NLP models in healthcare. While accuracy remains critical, healthcare providers and regulators demand transparent reasoning for each assigned code. Advances in model interpretability now allow clinicians to trace why a particular ICD10-CM code was chosen, increasing trust in automated systems. Hospitals that adopted interpretable NLP solutions in 2025 reported not only higher coding accuracy but also improved physician acceptance, as clinicians could validate the AI’s logic against their own expertise.
Entity Resolution in Spark NLP for Healthcare
In Spark NLP for Healthcare, the process of mapping entities to medical terminologies, or entity resolution, begins with Named Entity Recognition (NER). The first step is to extract the clinical entities relevant to the specific terminology we need. For instance, if we are looking for ICD-10 codes, we need to extract medical conditions such as diseases, symptoms, and disorders; while for RxNorm codes, we need to extract drug entities. Once we have extracted the necessary entities, we feed these entity chunks to the Sentence BERT (SBERT) stage, which generates embeddings for each entity. These embeddings are then fed into the entity resolution stage, which utilizes a pre-trained model to return the closest terminology code based on similarity measures between the embeddings and the codes within the medical terminology database. This process ensures accurate and efficient mapping of clinical entities to their corresponding medical terminology codes, facilitating various healthcare-related tasks and analyses.
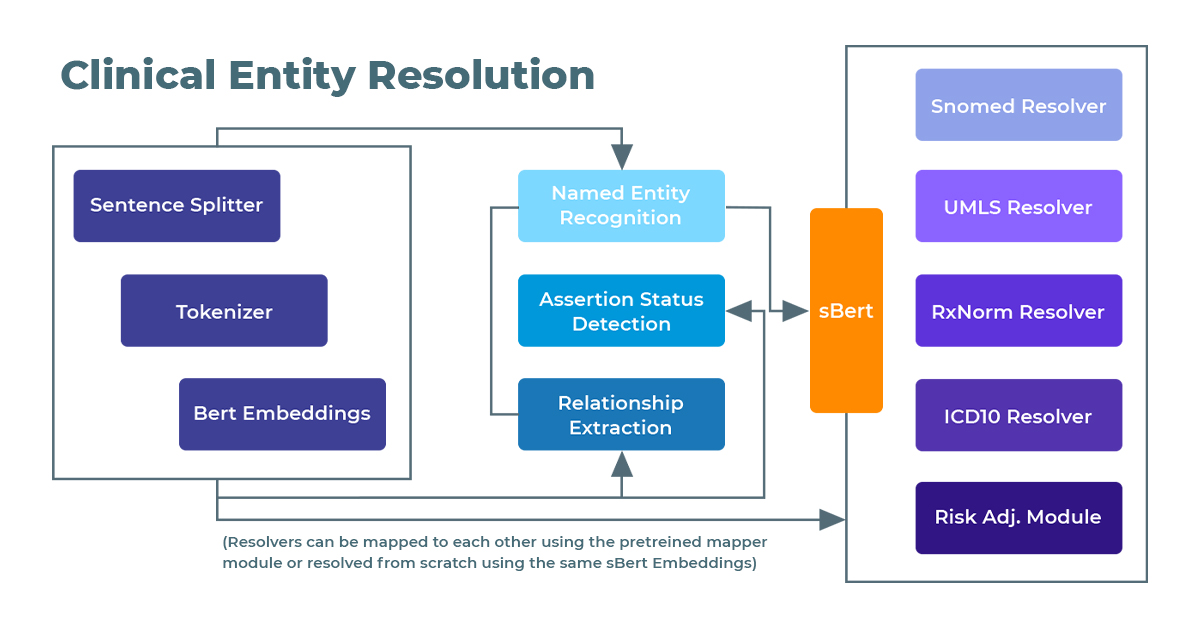
A sample pipeline for entity resolution in Spark Healthcare NLP
Healthcare natural language processing by John Snow Labs already comes with more than 50 pretrained ner models covering nearly almost all the medical terminologies including ICD10, RxNorm, Snomed, UMLS, CPT-4, NDC, HPO, and so on.
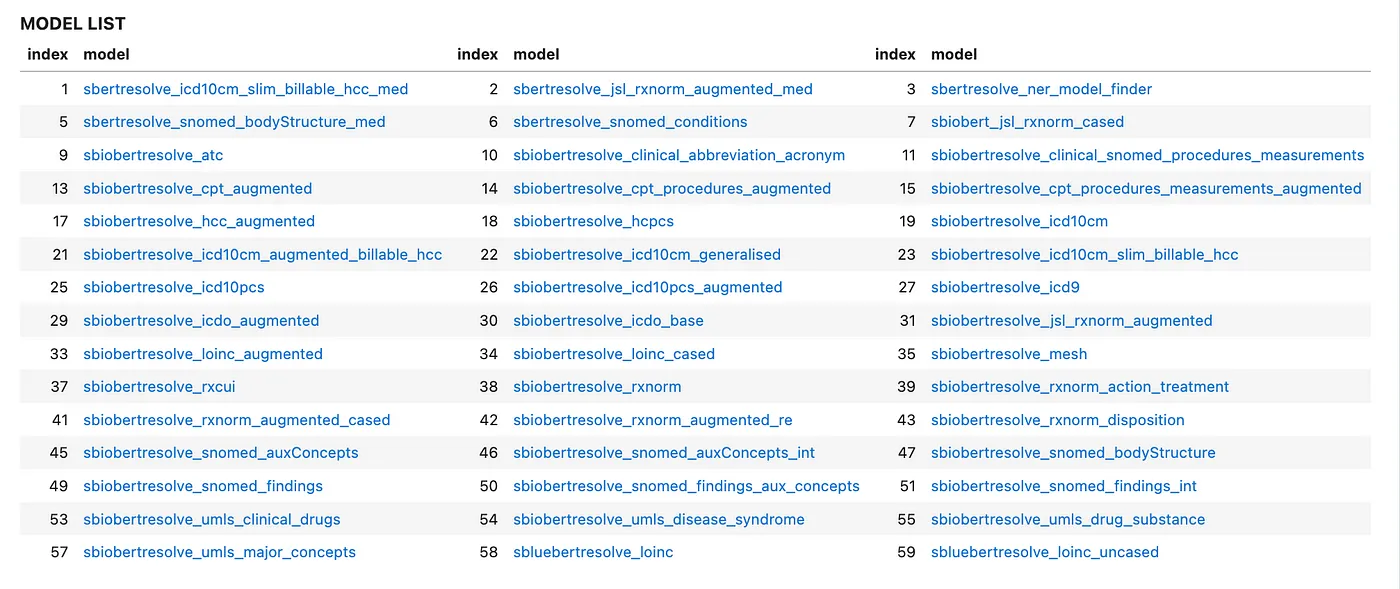
Pretrained entity resolution models in Spark NLP for Healthcare
In the following table, you will see the results returned by Spark NLP’s ICD-10 resolver when provided with a specific text. As demonstrated, all medical conditions are accurately detected, and the appropriate ICD-10 code is assigned to each of them based on the context in which they appear.
“A 28-year-old female with a history of gestational diabetes mellitus diagnosed eight years‘ prior to presentation and subsequent type two diabetes mellitus, associated with an acute hepatitis, and obesity.”
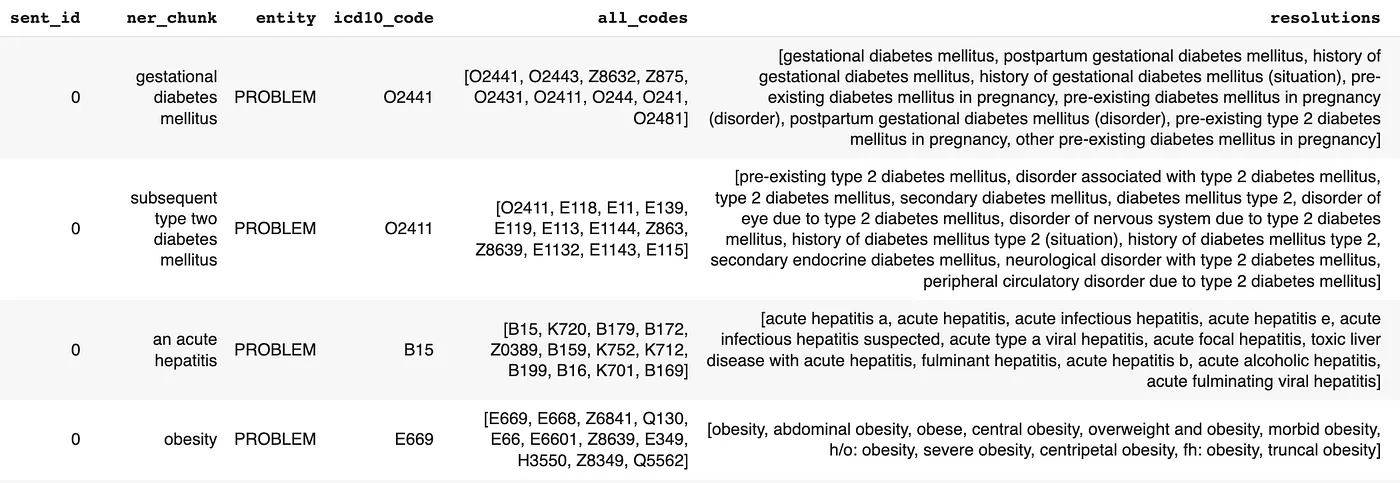
Sample output from ICD10-CM entity resolution pipeline
Comparison of Spark NLP for Healthcare and ChatGPT
ChatGPT has taken the world by storm and gained immense popularity, leading people to use it for a wide range of tasks, including healthcare-related ones. Our goal is to determine whether a general Large Language Models (LLM) like ChatGPT can excel in highly specific tasks like medical terminology mapping, which is typically handled by human coders, as opposed to specialized models.
All prompts, scripts to query ChatGPT API (ChatGPT-3.5-turbo, ChatGPT-4, temperature=0.7), evaluation logic, and results are shared publicly at a Github repo. Additionally, a detailed Colab notebook to run all the entity resolution models (not just ICD10) step by step can be found at the Spark NLP Workshop repo.
Initially, we aimed to test RxNorm and Snomed terminologies as well; however, ChatGPT did not provide any responses based on our prompts. When we insisted on receiving answers, the outcomes were entirely fabricated. Consequently, we narrowed our focus to ICD10-CM for this analysis.
Results and Analysis
In our evaluation of Spark NLP solutions for Healthcare and ChatGPT concerning entity resolution for ICD10-CM terminology, the results indicate that Spark NLP is superior in this particular task. We tested both models on five documents containing 50 ‘Problem’ entities that could receive ICD10-CM codes.
In the test with 5 documents containing 50 ‘Problem’ entities that could receive ICD10-CM codes, Spark NLP for Healthcare successfully extracted all entities but assigned the correct ICD-10 codes to only 38 of them, resulting in a 76% success rate.
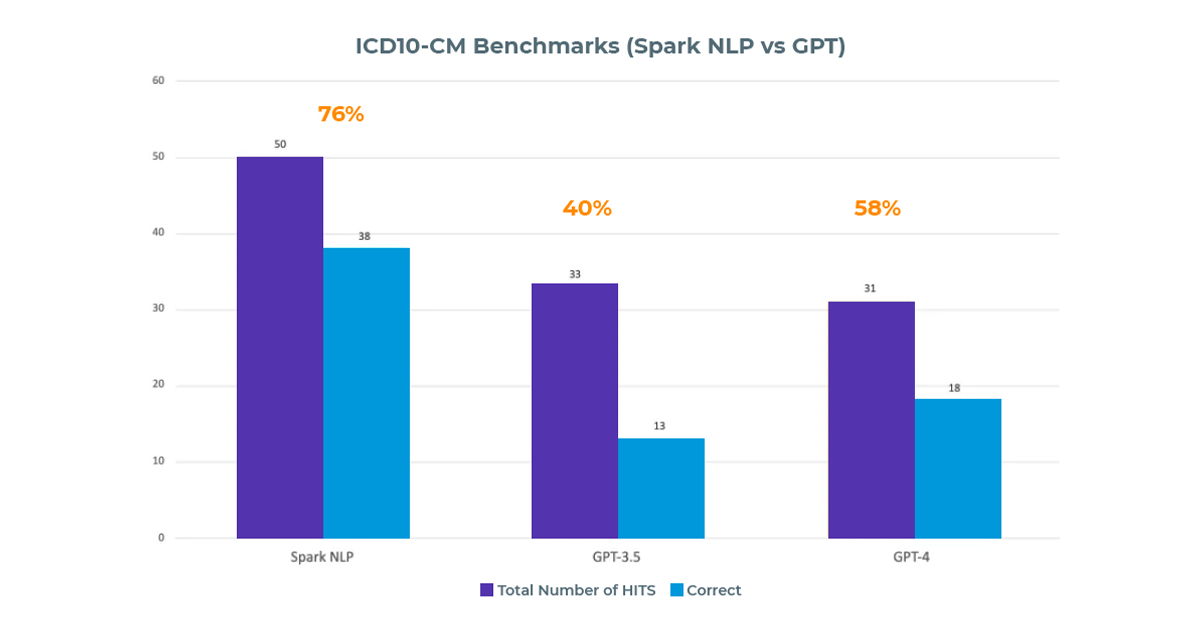
The comparison of Spark NLP for Healthcare and ChatGPT on on entity resolution for ICD10-CM terminology
GPT-3.5, on the other hand, managed to extract only 38 out of the 50 entities, and correctly assigned ICD10 codes to just 13 of them. Its success rate was 40% for the extracted entities (13/38), and its overall accuracy stood at 26% (13/50).
GPT-4 performed slightly better than its predecessor, extracting 31 out of 50 entities and accurately assigning ICD10 codes to 18 of them. The success rate for the extracted entities was 58% (18/31), while its overall accuracy reached 36% (18/50).
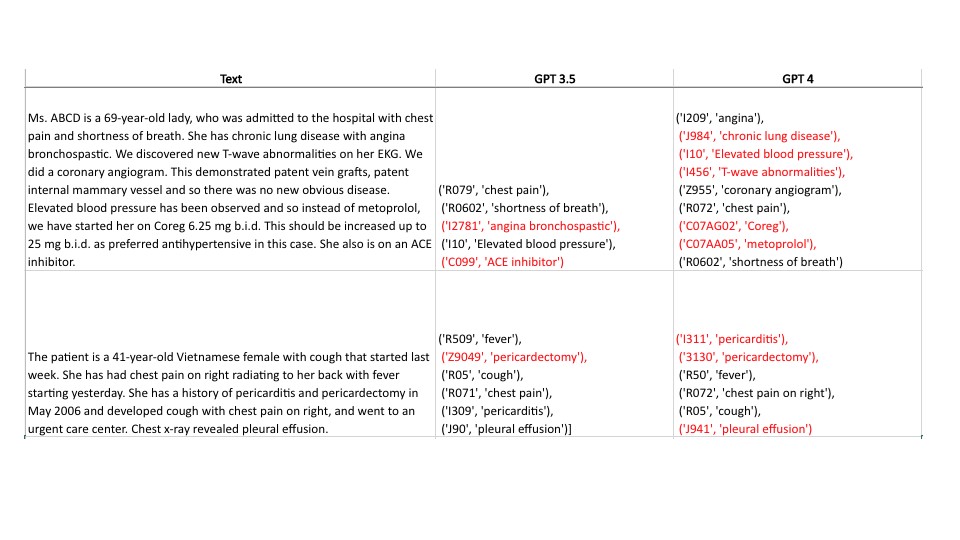
Sample output from GPT-3.5 and GPT-4 for ICD10-CM resolution. The words written in red indicate fabricated & partially-wrong ICD10 codes given the medical condition
Conclusion
As a result, In a test involving 50 ‘Problem’ entities eligible for ICD10-CM codes, Spark NLP for Healthcare achieved a 76% success rate by accurately assigning ICD-10 codes to 38 entities. In contrast, GPT-3.5 extracted 38 entities but only assigned correct ICD10 codes to 13, resulting in a 40% success rate for extracted entities and a 26% overall accuracy. GPT-4 showed a slight improvement, extracting 31 entities and correctly assigning ICD10 codes to 18 of them, with a 58% success rate for extracted entities and an overall accuracy of 36%.
Beyond the results of this comparison, it’s important to recognize how the broader landscape of clinical NLP is evolving.
Emerging Trends in Healthcare NLP
The integration of multimodal NLP systems in healthcare has already shown a breakthrough. Models that combine text, imaging, and genomics data are achieving strong coding accuracy in large hospital pilots across the US and EU. This demonstrates that entity resolution is no longer just a text-based challenge but part of a broader multimodal understanding of patient health.
Another significant trend is the rise of continual learning in clinical NLP systems. Hospitals are increasingly deploying models capable of updating their knowledge from newly approved treatments and evolving ICD standards in real time. This approach has led to a noticeable improvement in the accuracy of coding rare diseases, highlighting the importance of adaptability in clinical environments.
The focus is also shifting toward regulatory-grade NLP systems. Healthcare organizations are beginning to demand explainability reports alongside automated coding outputs, reflecting a stronger emphasis on compliance and accountability. The next competitive edge in healthcare NLP will not only be higher accuracy but also adherence to frameworks such as the EU AI Act and FDA’s Good Machine Learning Practices, ensuring safe and auditable use of NLP in clinical workflows.
The results highlight the importance of using specialized models like Spark NLP for Healthcare when dealing with domain-specific tasks such as ICD10-CM entity resolution. While ChatGPT models like GPT-3.5 and GPT-4 can perform well in various general language understanding tasks, they may not be as effective as domain-specific models when it comes to specialized fields like healthcare.
In conclusion, the comparison indicates that Spark NLP for Healthcare provides a more accurate and reliable solution for medical NLP tasks compared to ChatGPT. This is likely due to its dedicated training and fine-tuning on healthcare-related data, which enables it to better understand and process medical concepts and terminology. It’s essential for professionals in the healthcare industry to carefully consider the strengths and limitations of different AI models to ensure they use the most appropriate and accurate tools for their specific needs. By leveraging domain-specific models like Spark NLP for Healthcare, healthcare providers and organizations can improve the accuracy of entity resolution, leading to better patient care, more efficient billing processes, and more effective use of healthcare data for research and quality improvement initiatives.

FAQ
1. Why is entity resolution critical in healthcare NLP?
Entity resolution ensures that clinical terms are consistently mapped to standardized codes like ICD10-CM. This supports accurate diagnoses, billing, research, and compliance with regulatory requirements.
2. How does Spark NLP for Healthcare differ from general-purpose models like ChatGPT?
Spark NLP is trained on domain-specific medical data and fine-tuned for healthcare terminology, making it more accurate in mapping clinical notes to ICD10-CM codes compared to general LLMs.
3. Can ChatGPT still play a role in medical coding workflows?
ChatGPT can assist with summarization and language understanding, but its lack of specialized training means it may generate incomplete or fabricated codes. It’s best used as a supportive tool rather than a primary coding engine.
4. What trends are shaping the future of healthcare NLP?
Key trends include multimodal data integration, continual learning for adapting to new medical standards, and explainable NLP models that provide transparency in coding decisions.
5. How does explainability influence the adoption of NLP tools in hospitals?
Explainable NLP allows clinicians to understand why a specific code was assigned, improving trust and regulatory acceptance. Hospitals using interpretable models report higher coding accuracy and greater physician confidence in AI-driven workflows.




