See how Bert-based models in Spark NLP can effortlessly resolve co-reference in your text data

Coreference resolution is the task of identifying and linking all expressions within a text that refer to the same real-world entity, such as a person, object, or concept. Using Spark NLP, it is possible to perform many NLP applications, including text understanding, information extraction, and question answering.
What is coreference resolution in NLP
Coreference resolution is the task of identifying and linking all expressions within a text that refer to the same real-world entity, such as a person, object, or concept. In practical terms, the coreference resolution NLP technique involves analyzing a text and identifying all expressions that refer to a specific entity, such as “he,” “she,” “it,” or “they.” Once these expressions are identified, they are linked together to form a “coreference chain,” which represents all the different ways in which that entity is referred to in the text.
For example, given the sentence, “John went to the store. He bought some groceries,” ; a coreference resolution model would identify that “John” and “He” both refer to the same entity and produce a cluster of coreferent mentions.
Coreference resolution is a complex task, and it is used in a variety of applications, including information extraction, question answering, and machine translation. It is an important task in natural language processing (NLP), as it enables machines to accurately understand the meaning of a text and generate more human-like responses.
In this post, you will learn how to use Spark NLP to perform coreference resolution.
Let us start with a short Spark NLP introduction and then discuss the details of the coreference resolution techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs (JSL). It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown into a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in the industry (5 years in a row)
- The most scalable, accurate, and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, a structure that contains all the steps to be run on the input data:
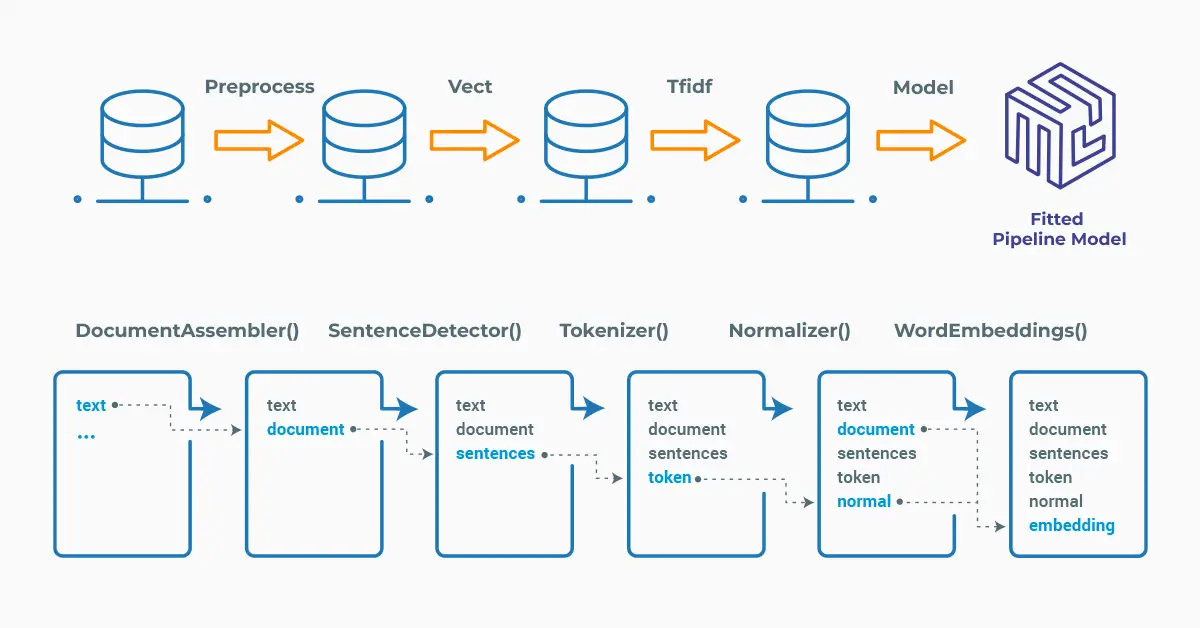
Spark NLP pipelines
Each step contains an annotator that performs a specific task, such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document. In contrast, a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP and perform coreference resolution in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
Defining the Spark NLP Pipeline
The SpanBertCoref annotator expects DOCUMENT and TOKEN as input, and then will provide DEPENDENCY as output. Thus, we need the previous steps to generate those annotations that will be used as input to our annotator.
Spark NLP has the pipeline approach and the pipeline will include the necessary stages.
Please check Unraveling Coreference Resolution in NLP here! for the examples and explanations below.
The first example is for this text:
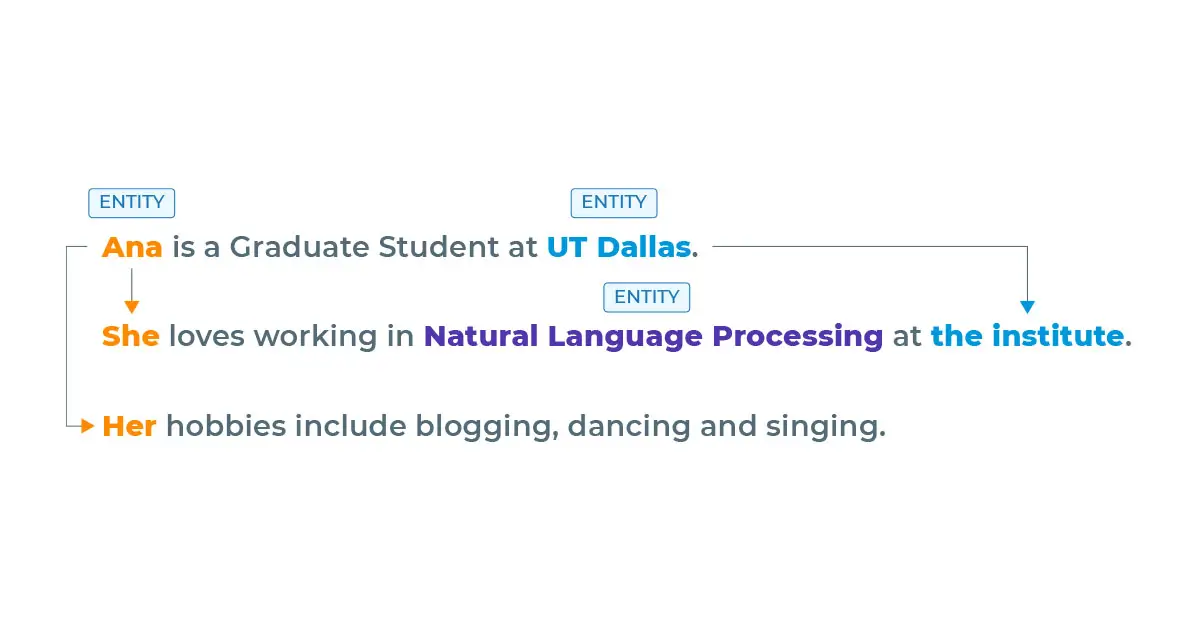
Here, “Ana”, “Natural Language Processing” and “UT Dallas” are possible entities.
“She” and “Her” are references to the entity “Ana” and “the institute” is a reference to the entity “UT Dallas”.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
SentenceDetector,
Tokenizer,
SpanBertCorefModel
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
# Step 2: Sentence Detection
sentenceDetector = SentenceDetector() \
.setInputCols("document") \
.setOutputCol("sentences")
# Step 3: Tokenization
token = Tokenizer() \
.setInputCols("sentences") \
.setOutputCol("tokens") \
.setContextChars(["(", ")", "?", "!", ".", ","])
# Step 4: Coreference Resolution
corefResolution= SpanBertCorefModel().pretrained("spanbert_base_coref")\
.setInputCols(["sentences", "tokens"]) \
.setOutputCol("corefs") \
.setCaseSensitive(False)
# Define the pipeline
pipeline = Pipeline(stages=[document, sentenceDetector, token, corefResolution])
# Create the dataframe
data = spark.createDataFrame([["Ana is a Graduate Student at UT Dallas. She loves working in Natural Language Processing at the Institute. Her hobbies include blogging, dancing and singing."]]).toDF("text")
# Fit the dataframe to the pipeline to get the model
model = pipeline.fit(data)
Let us transform in order to get a prediction and determine the related entities:
model.transform(data).selectExpr("explode(corefs) AS coref").selectExpr("coref.result as token", "coref.metadata").show(truncate=False)

The data frame shows the extracted entities and their metadata
One-liner alternative
In October 2022, John Snow Labs released the open-source johnsnowlabs library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow, especially for users working with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all of John Snow Lab’s libraries and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To run Language Detection with one line of code, we can simply:
# Import the NLP module which contains Spark NLP and NLU libraries
from johnsnowlabs import nlp
sample_text= "Ana is a Graduate Student at UT Dallas. She loves working in
Natural Language Processing at the Institute. Her hobbies include blogging,
dancing and singing."
# Returns a pandas Data Frame, we select the desired columns
nlp.load('en.coreference.spanbert').predict(sample_text, output_level='sentence')

The resulting data frame produced by the one-liner model
The reason for the difference between the one-liner’s results and the previous results is here the model’s case sensitivity was ON and did not detect ‘the Institute.’
The one-liner is based on default models for each NLP task. Depending on your requirements, you may want to use the one-liner for simplicity or customize the pipeline to choose specific models that fit your needs.
NOTE: when using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function include using the licensed Healthcare NLP library with nlp=True, but we can set that to False and use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
The second example is much longer and more complicated.
The paragraph involves a person and a company’s names mentioned in multiple ways, and the model was able to detect them all.

We will use the same model but feed the text above:
data_2 = spark.createDataFrame([[""" "I had no idea I was getting in so deep," says Mr. Kaye, who founded Justin in 1982. Mr. Kaye had sold Capetronic Inc., a Taiwan electronics maker, and retired, only to find he was bored. With Justin, he began selling toys and electronics made mostly in Hong Kong, beginning with Mickey Mouse radios. The company has grown - to about 40 employees, from four initially, Mr Kaye says. Justin has been profitable since 1986."""]]).toDF("text")
model = pipeline.fit(data_2)
model.transform(data_2).selectExpr("explode(corefs) AS coref").selectExpr("coref.result as token", "coref.metadata").show(truncate=False)
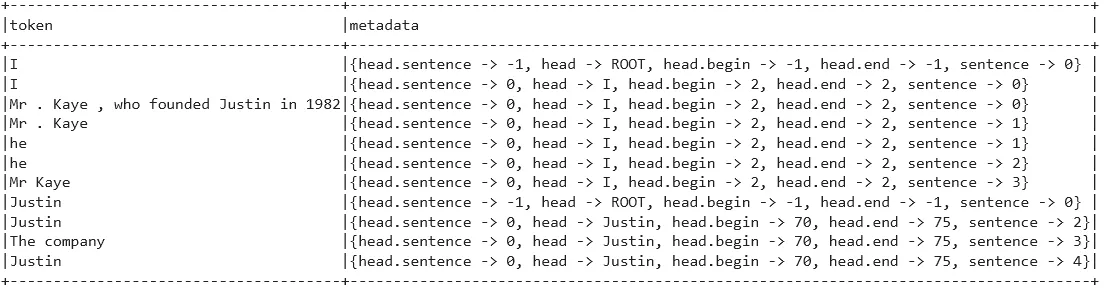
The data frame shows the extracted entities and their metadata
For additional information, please consult the following references:
- Documentation : SpanBertCoref
- Python Docs : SpanBertCoref
- Scala Docs : SpanBertCoref
- Academic Reference Paper: SpanBERT: Improving Pre-training by Representing and Predicting Spans
- John Snow Labs SpanBertCoref Model
Conclusion
SpanBertCoref annotator of Spark NLP is a coreference resolution model based on SpanBert, which identifies expressions that refer to the same entity in a text.
Coreference resolution NLP models produce a mapping of all the expressions in a text that refer to the same real-world entity. Coreference resolution tasks can be a challenging, particularly in cases where there are multiple potential referents for a given expression or when the referent is implicit or ambiguous.