
























































The RAG ingestion problem
In real-world RAG systems, the quality of the final answer is constrained by the quality of the indexed representation. If the ingestion layer fails to capture the meaning encoded in charts, diagrams, screenshots, tables, legends, and other layout-dependent visual artifacts, the retriever is not operating over the true document semantics. It is operating over an incomplete surrogate of the source page.
That failure mode is especially pronounced in multimodal business and technical documents. Consider a quarterly revenue report that contains a paragraph introducing a chart, but where the actual trend, inflection point, or category comparison only appears in the figure. A text only pipeline will embed the surrounding prose and perhaps some OCR fragments, yet it will often miss the precise visual claim that a human reader immediately extracts from the chart. In a RAG setting, that means relevant chunks may never be retrieved for questions such as Which product line declined in Q3? or What trend is shown in the revenue breakdown? even though the answer is visually obvious on the page.
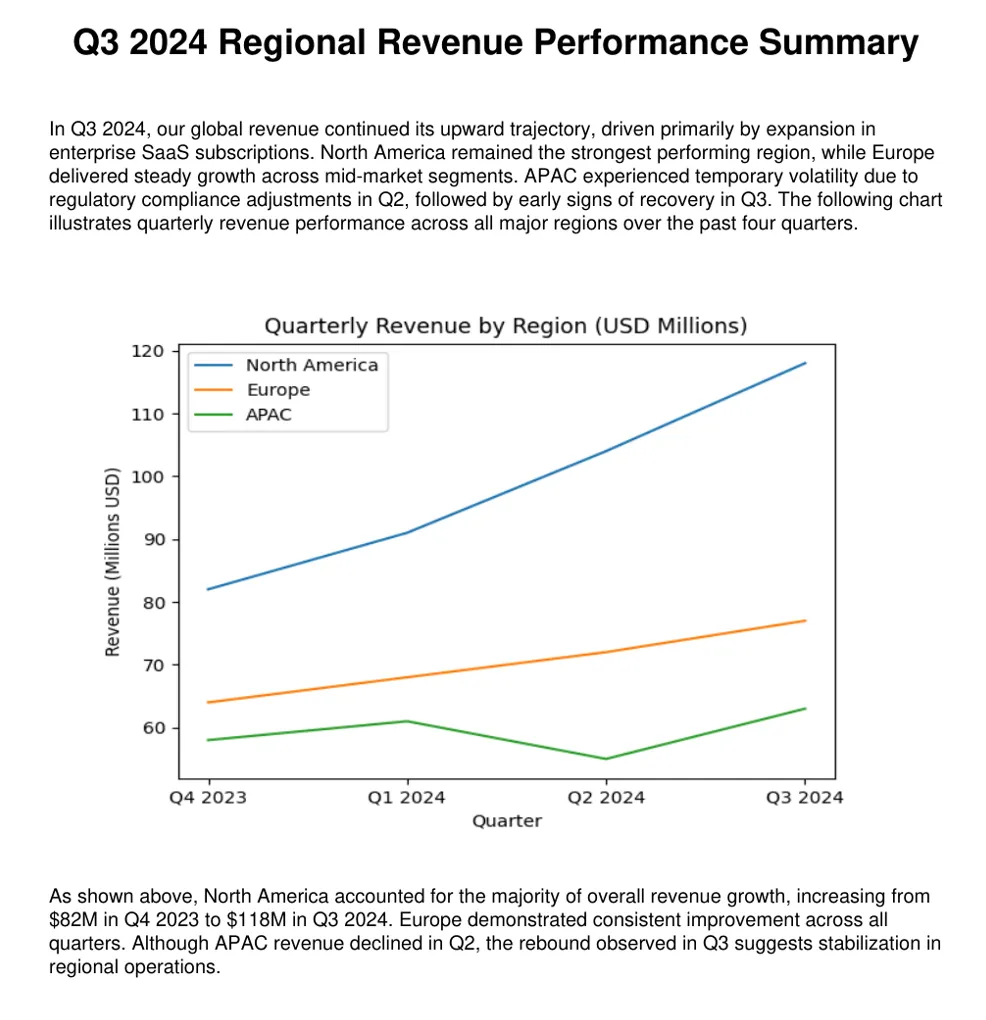
Clinical and scientific documents introduce another variant of the same issue. Endpoint plots, cohort diagrams, treatment arm schemas, and adverse event tables often encode the most decision relevant information in highly structured visual form. If those artifacts are not semantically reconstructed during ingestion, a RAG system may retrieve a general summary paragraph while overlooking the image that actually contains the efficacy pattern, patient-group distinction, or safety signal needed to answer the user question precisely.
In other words, multimodal RAG does not fail only at generation time. It often fails much earlier, during ingestion, when visually grounded meaning is discarded or flattened into weak OCR text. Once that information is absent from the index, prompt engineering and reranking can only compensate so much.
Layout-aware multimodal ingestion
At enterprise scale, document ingestion rarely happens over a clean corpus of plain text files. Real world knowledge bases are usually composed of heterogeneous, mixed-type assets such as PDFs, PPTX decks, DOCX reports, technical summaries, clinical dossiers, financial statements, and slide based architecture reviews. These assets are multimodal by construction: they combine narrative text with charts, diagrams, screenshots, tables, icons, and other layout-dependent visual artifacts whose semantic contribution is often critical to downstream retrieval quality.
Multimodal Document
When teams deploy ingestion pipelines for these corpora, they typically fall into one of two sub-optimal patterns:
- Push everything through text centric parsing and embedding pipelines, effectively treating the document as if its machine-readable text were the whole signal.
- Over correct by sending entire documents through vision language models (VLMs), even when most pages are predominantly textual and only a small subset of regions actually require visual interpretation.
Both strategies create avoidable failure modes.
Text-only ingestion pipelines are computationally efficient, but they systematically under represent visually encoded meaning, especially in charts, topology diagrams, annotated screenshots, and figure-heavy reports.
Full document VLM ingestion captures more multimodal context, but it is operationally expensive, introduces unnecessary latency, and allocates vision inference to document regions that are already well handled by OCR and standard NLP components.
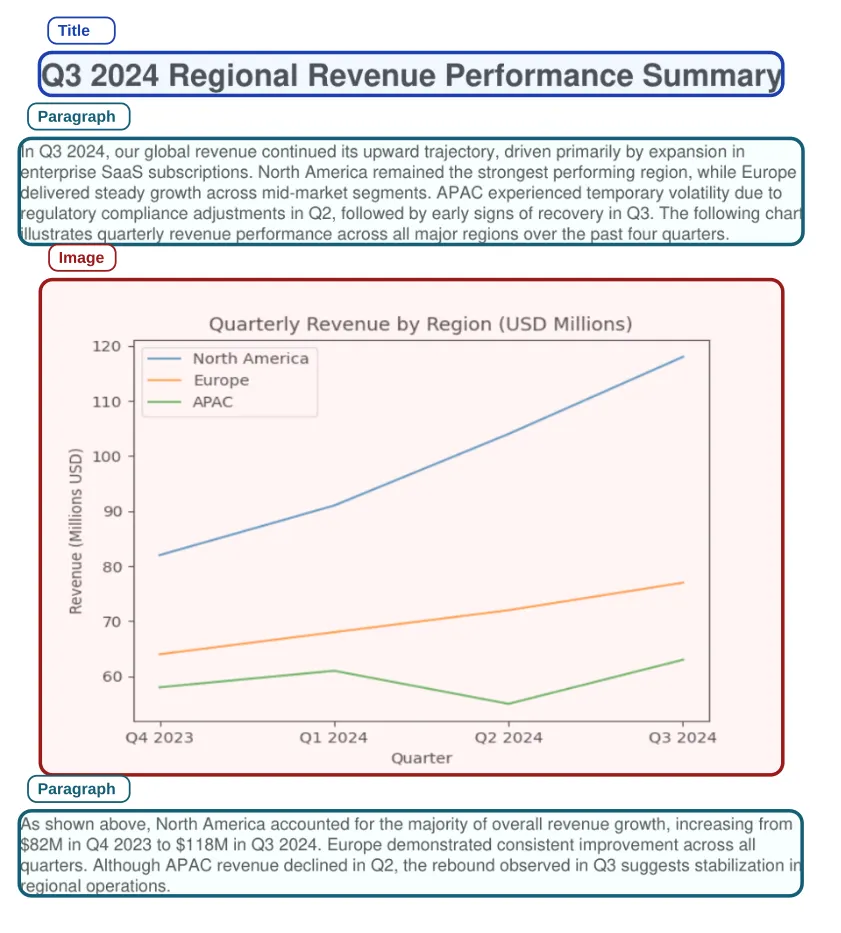
A more robust design pattern is layout-aware selective multimodal ingestion. Instead of captioning the entire document, the pipeline first identifies the non-text visual regions that actually require multimodal interpretation, aligns those regions with their nearest textual context, prompts the VLM with localized semantic grounding, and then reconstructs the document so that the generated image understanding is reinserted into the final reading flow. This produces a retrieval ready representation that is both semantically richer and substantially more efficient than a brute force multimodal pass.
Layout-Aware Selective Multimodal Ingestion
This is precisely the problem space addressed by Spark NLP’s new LayoutAlignerForVision and LayoutAlignerForText annotators. Together, they provide an end-to-end mechanism for aligning extracted text and image annotations, generating context-aware captions only where needed, and rebuilding coherent multimodal document text for downstream chunking, embedding, indexing, and retrieval workflows.
Methodology
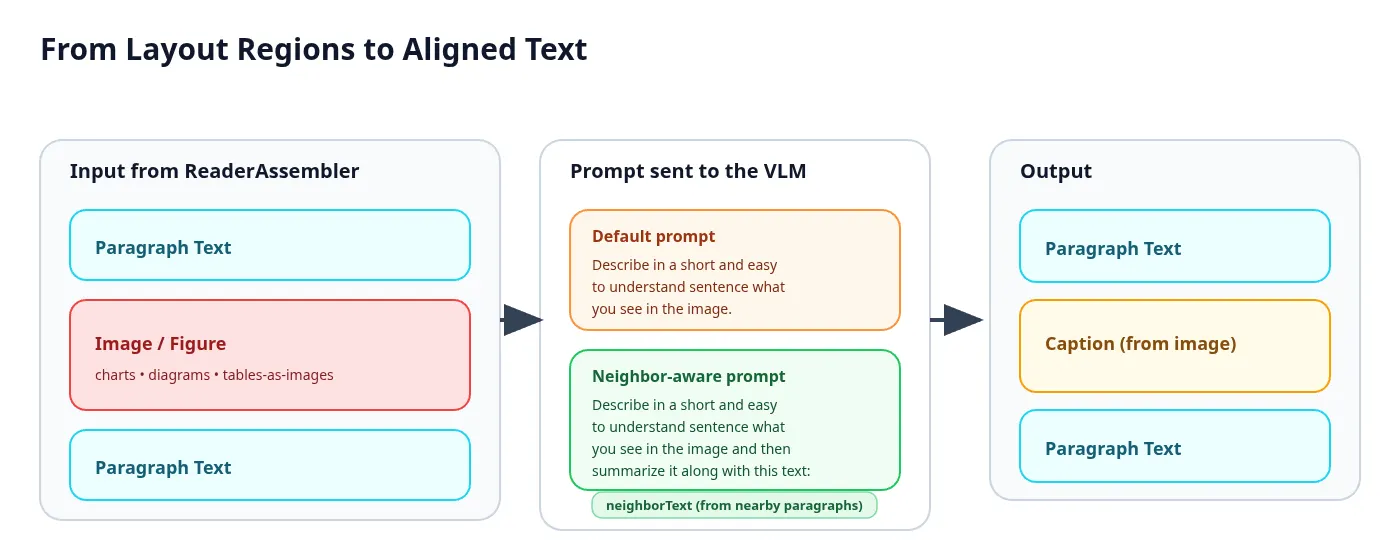
The core methodology follows a selective multimodal enrichment architecture designed for retrieval and indexing pipelines rather than generic document captioning. Conceptually, the workflow separates document understanding into two stages:
- Identify and align the regions that require vision reasoning

Selective Multimodal Enrichment
- Propagate the resulting visual semantics back into a text centric representation that can be consumed by conventional embedding and search infrastructure.
The processing path can be summarized as follows:
1. Ingest each document and extract both text annotations and image annotations.
2. Apply layout-aware alignment so that each relevant image is paired with the nearest textual region using positional heuristics.
3. Optionally enrich the image caption prompt with neighboring textual context by enabling:
addNeighborText=True neighborTextCharsWindow=
4. Run VLM captioning only on those aligned image regions instead of the full document.
5. Reconstruct the document by reinserting captioned visual meaning into the surrounding text flow with LayoutAlignerForText.
6. Split the reconstructed multimodal text into retrieval sized chunks.
7. Generate dense sentence or document embeddings for each chunk.
8. Hand off the chunk text, vectors, and metadata to Elasticsearch for downstream vector indexing.
From a systems perspective, the important design choice is that multimodal inference is applied surgically, not globally. This reduces VLM utilization to the subset of content where it adds actual value, while preserving the strong throughput and distributed execution characteristics of Spark based text processing. The result is a retrieval oriented representation that retains chart and figure semantics without paying the cost of end-to-end VLM processing across all pages.
Why LayoutAligners matter?
The key innovation in this approach is not merely that images are captioned, but that they are captioned in layout context. In rich documents, the meaning of a visual artifact is rarely self-contained. A chart may depend on the title above it, the explanatory paragraph below it, or the KPI definitions introduced in the previous section. A network diagram may only become interpretable when paired with adjacent architectural prose. Captioning such images in isolation often produces generic or weak descriptions that are insufficient for high-quality semantic retrieval.
LayoutAlignerForVision addresses this by aligning DOCUMENT and IMAGE annotations through layout-aware heuristics and emitting three derived outputs from the configured output column.
LayoutAlignerForText completes the second half of the workflow by rebuilding coherent text from document chunks and generated captions.
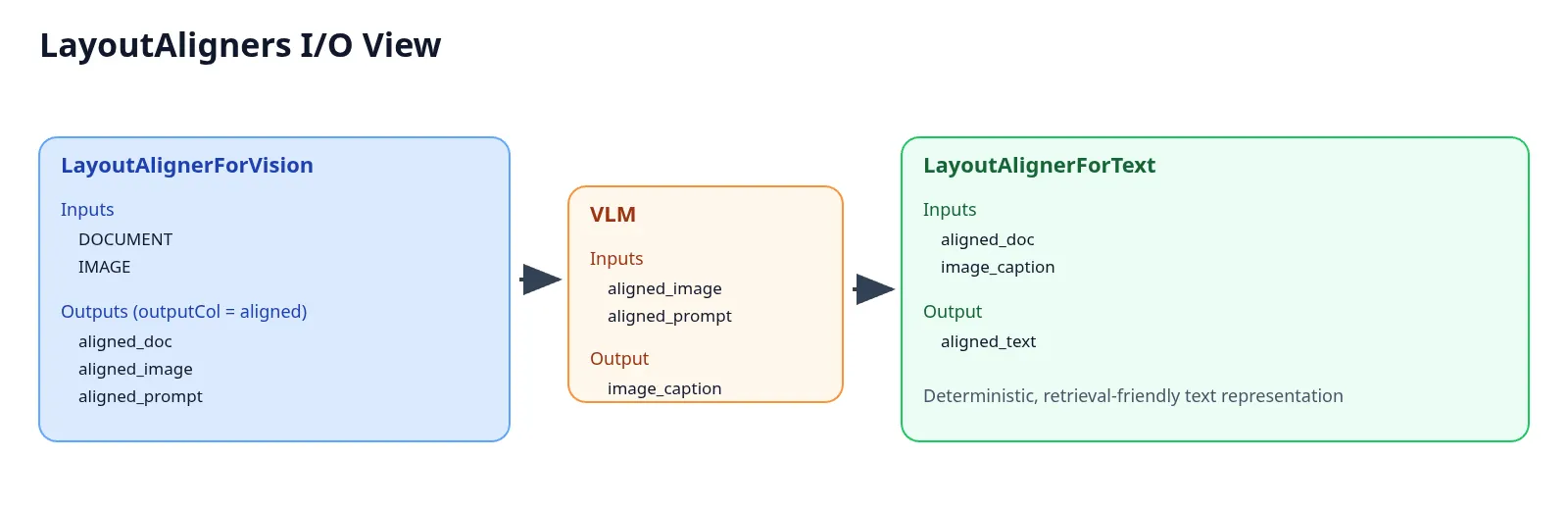
Inputs/Outputs for LayoutAlignerForVision, VLM, and LayoutAlignerForText
Taken together, these annotators convert what is usually a disconnected multimodal intermediate state into a deterministic and retrieval friendly document representation. That is the architectural reason they matter: they bridge the gap between layout parsing and downstream semantic indexing.
Implementation
This walk through follows the pipeline structure demonstrated in the notebook and frames it as a production-oriented ingestion pattern rather than a one-off captioning demo. The implementation can be thought of as four major phases: extraction, alignment, caption generation, and reconstruction for embeddings
1) Ingestion with ReaderAssembler
ReaderAssembler()
.setContentType("application/pdf")
.setContentPath(pdf_directory)
.setOutputAsDocument(False)
.setOutputCol("data")
.setUseEncodedImageBytes(True)
The ingestion layer starts with ReaderAssembler, which parses the source files and emits structured text and image annotations instead of collapsing the entire document into a monolithic string. In this configuration, the assembler is reading PDFs and generating separate annotation streams such as data_text and data_image. That distinction is fundamental, because the downstream alignment stage relies on having explicit document chunks and image objects available as first-class annotations rather than implicit artifacts buried inside a raw payload. The notebook also enables encoded image bytes so that the extracted visual regions can be passed directly into downstream vision inference without an additional serialization or image reconstruction step.
2) Layout-aware image-text pairing
Default mode (no neighbor text):
LayoutAlignerForVision()
.setInputCols(["data_text", "data_image"])
.setOutputCol("aligned")
Neighbor-aware mode:
<LayoutAlignerForVision()
.setInputCols(["data_text", "data_image"])
.setOutputCol("aligned")
.setAddNeighborText(True)
.setNeighborTextCharsWindow(500)
This stage is where layout intelligence enters the pipeline. LayoutAlignerForVision consumes DOCUMENT and IMAGE annotations and applies proximity based heuristics to determine which text region should serve as the semantic anchor for each image. According to the implementation, the alignment logic considers distance, paragraph geometry, slide or page scope, optional contextual windows for floating images, and a confidence model derived from relative vertical distance. The annotator can also fall back to same slide or same page strategies when a strict local match is not found, which makes it more resilient across variable layouts such as presentations, PDF reports, and mixed visual documents.
The aligned outputs are: aligned_doc, aligned_image, aligned_prompt
These outputs are important because they enforce a structured data transition between layout alignment and VLM inference, replacing manual prompt assembly with a formalized process. The aligned_prompt column is not just a static instruction string; when neighbor text is enabled, it becomes a localized captioning prompt that blends a base instruction with surrounding textual context. In practice, this means a chart can be captioned with awareness of nearby business, scientific, or technical narrative, which substantially improves grounding quality for visuals whose meaning depends on local prose rather than pixel content alone. The notebook explicitly demonstrates this difference by comparing a default prompt path against a neighbor-aware prompt path that injects up to 500 characters of surrounding context.
3) VLM captioning only where needed
AutoGGUFVisionModel.pretrained()
.setInputCols(["aligned_prompt", "aligned_image"])
.setOutputCol("image_caption")
At this point the pipeline hands only the aligned image regions, plus their layout informed prompts, to the VLM. This is the operational efficiency win of the overall design. The model is not asked to reinterpret entire pages or complete documents; it is asked to caption the specific image regions that survived alignment and confidence filtering. The demo notebook wraps this step with a helper builder for AutoGGUFVisionModel so that inference parameters such as batchSize, nCtx, nPredict, temperature, topK, and topP remain consistent across experiments, making it easier to isolate the effect of layout aware prompt construction.
From a machine learning systems perspective, this selective captioning pattern is much closer to how one would design a production ingestion service. It conserves GPU budget, reduces unnecessary multimodal tokens, improves throughput, and keeps vision inference bounded to the document subregions that are most likely to alter retrieval semantics.
4) Reassemble text and image meaning
Once captions are generated, LayoutAlignerForText reconstructs a text centric representation of the document in which visual meaning is inserted back into the reading flow. In the demo notebook this stage is fed with data_text and image_caption, while the annotator implementation itself is explicitly designed for aligned document caption reconstruction. The important outcome is that the final aligned_text column is no longer plain extracted text; it is a semantically enriched document representation that incorporates the informational payload of previously non-textual regions.
Internally, the annotator rebuilds text at the element or file scope by pairing document chunks with captions, normalizing layout metadata, deduplicating repeated image assignments, deciding whether captions should be inserted before or after paragraph text, and optionally merging all rebuilt elements into a single file level annotation. This reconstruction step is what makes the downstream embedding stage materially better: instead of embedding isolated paragraphs and separately storing opaque image captions, the system embeds a unified multimodal text stream whose semantics better reflect how a human reader would interpret the source document.
5) Split into chunks and generate sentence embeddings
DocumentCharacterTextSplitter()
.setInputCols(["aligned_text"])
.setOutputCol("chunked_docs")
.setChunkSize(1200)
.setChunkOverlap(120)
BertSentenceEmbeddings.pretrained("sent_small_bert_L2_128", "en")
.setInputCols(["chunked_docs"])
.setOutputCol("chunk_embeddings")
EmbeddingsFinisher()
.setInputCols(["chunk_embeddings"])
.setOutputCols(["finished_embeddings"])
.setOutputAsVector(True)
After multimodal reconstruction, the document is returned to a familiar retrieval pipeline. DocumentCharacterTextSplitter partitions the enriched document into index sized chunks, and BertSentenceEmbeddings converts each chunk into a dense vector representation suitable for semantic search. EmbeddingsFinisher then materializes the embedding annotations into vector form so they can be persisted in tabular or search-index-ready structures. In the demo notebook, the resulting dataset is flattened to one row per chunk so that each chunk can map cleanly to an indexable unit containing chunk_text, metadata, and its embedding vector. The sequencing here is critical. The chunking happens after the layout aware multimodal reconstruction, not before it. That ordering ensures the embedding model sees a coherent semantic unit in which visual meaning has already been grounded and merged, rather than forcing retrieval to correlate independent text chunks and disconnected caption artifacts later in the pipeline.
6) Indexing hand-off (next step)
This post intentionally stops before the Elasticsearch write path, but the operational hand-off is straightforward. The next stage is to send: chunk_text, embedding_vector, chunk, and source metadata into an Elasticsearch vector index, where the chunks can participate in k-NN search, hybrid lexical-semantic retrieval, filtered retrieval, or downstream re-ranking pipelines. The important point is that the LayoutAligners do not replace the retrieval stack; they improve the semantic quality of the content being indexed into it.
Representative use cases
Although the notebook demonstrates the workflow on a small sample of three PDFs, the pattern generalizes well across several high value enterprise scenarios. The included demo examples highlight financial reports, clinical trial summaries, and cloud architecture documents, each of which contains high density visual content whose meaning depends heavily on adjacent text.
In financial reporting, charts, KPI summaries, and annotated performance graphics often encode the most retrieval worthy facts in the document. Without layout aware captioning, a vector index may capture the narrative commentary but miss the visual explanation of revenue trend inflections, category breakdowns, or quarter-over-quarter variance. Aligning charts with nearby explanatory paragraphs improves the probability that downstream search will retrieve chunks containing both the business narrative and the visual evidence.
In clinical and life sciences content, endpoint plots, cohort flow diagrams, and adverse event tables are especially sensitive to contextual grounding. A caption generated without surrounding text may correctly identify that an image is a graph or table, yet still miss the medically salient variables, treatment groups, or outcome semantics that make the visual useful during evidence retrieval. Local neighbor text helps constrain the caption toward domain relevant interpretation.
In cloud and software architecture documentation, topology diagrams, service dependency visuals, and deployment schematics are often more informative than the prose alone. By aligning those diagrams to nearby technical paragraphs before caption generation, the reconstructed text can better preserve system boundaries, component relationships, and infrastructure intent, making architecture search and RAG-based troubleshooting more precise.
Benefits
This layout aware ingestion pattern produces several concrete benefits for mixed-type corpora.
- Higher multimodal efficiency: Vision inference is targeted at image regions that actually need semantic interpretation, rather than being wasted on full pages whose dominant signal is already present in extracted text. This makes the approach more cost-efficient and more production friendly for large scale corpora.
- Better semantic grounding: Neighbor aware prompts enable captions to incorporate local narrative context, which is particularly valuable for charts, diagrams, and screenshots whose meaning is not fully recoverable from pixels alone. The result is caption output with higher contextual fidelity and stronger downstream retrieval utility.
- Stronger reconstructed text for embeddings: Because LayoutAlignerForText reinserts captioned visual meaning into the document reading order, the chunks that reach the embedding model are semantically more complete. This improves the representation quality of retrieval units without forcing the rest of the search stack to become natively multimodal.
- Spark-native pipelines: The pattern is still a standard Spark pipeline and therefore inherits Spark’s distributed execution model for large document batches. In other words, the design scales not because the VLM sees bigger documents, but because the overall ingestion DAG remains partitionable, pipeline based, and aligned with Spark execution semantics
- Cleaner downstream indexing: By the time the data reaches Elasticsearch or any other vector backend, each row can represent a retrieval-ready chunk with aligned text, grounded caption semantics, and associated metadata. This leads to a cleaner interface between document understanding and search infrastructure, which is particularly valuable in production RAG and enterprise search systems where observability and deterministic pre-processing matter. For large ingestion workloads, this becomes a high-leverage design pattern: apply multimodal reasoning only where it is information bearing, then collapse the result back into a text first representation that standard embedding and search systems can consume efficiently.
Conclusion
For mixed-type document ingestion, the architectural goal should not be to maximize vision usage, but to maximize useful multimodal signal per unit of compute. That is the broader lesson behind LayoutAligners. They offer a middle path between two extremes: the semantic blind spots of text-only ingestion and the computational overkill of sending whole documents to VLMs.
In practice, the workflow is straightforward but powerful: detect non-text content, align it to nearby text, caption it with localized context, merge the resulting visual semantics back into the reading flow, and only then split and embed the final representation for search. The end result is a corpus that is not merely parsed, but semantically reconstructed for retrieval.
For data scientists, machine learning engineers, and AI platform teams, this is the practical value proposition. LayoutAlignerForVision and LayoutAlignerForText do not just add two new annotators to Spark NLP; they introduce a more disciplined ingestion pattern for multimodal enterprise content. That pattern improves semantic completeness, constrains multimodal inference cost, and creates a stronger foundation for vector indexing, RAG, document understanding, and large-scale search over rich business and technical content.
Do you want to know more?
- Read a related story of document ingestion with Spark NLP here
- Check the example notebooks in the Spark NLP repository, available here
- Visit John Snow Labs and Spark NLP Technical Documentation websites
- Follow us on Medium: Spark NLP and Veysel Kocaman
- Write to support@johnsnowlabs.com for any additional requests you may have



