






















































Spark NLP Short Blogpost Series: 2
In this post, we will briefly explain what you can accomplish with Spark NLP clinical modules. For the sake of brevity, we will just focus on two modules: Clinical Named Entity Recognition (NER) and Assertion Status Detection.
In clinical NER, we basically have three entities: Problem, Treatment, and Test.
These are the most practical entities being used in healthcare analytics and we trained this model using i2b2 dataset – a part of Challenges in NLP for Clinical Data. The goal is to extract clinical entities (Problem, Treatment, and Test) from highly unstructured clinical text.
On the other hand, assertion status assigns certain assertions to each clinically relevant named entity. These assertion types could be “present”, “absent”, “hypothetical”, “conditional”, “associated_with_other_person”, etc. We again used the same i2b2 dataset for this task.
In Spark NLP, we implemented Clinical NER using char CNN+BiLSTM+CRF algorithm and the Assertion Status model using a SOTA approach in Tensorflow. These modules are only available to licensed users at the moment.
Lets see how it works!
We start by importing the licensed Spark NLP library.

Then we load the pretrained clinical pipeline from disk.

“explain_clinical_doc_dl” has the following annotators inside.
- Tokenizer
- Sentence Detector
- Clinical Word Embeddings (glove trained on pubmed dataset)
- Clinical NER-DL (trained by SOTA algorithm on i2b2 dataset)
- AssertionDL model (trained by SOTA algorithm on i2b2 dataset)
Getting faster inferences and not to deal with Spark data frames, we can convert this pipeline into Spark NLP LightPipeline.

Here is our sample clinical text:
 And we just send it to pretrained lightpipeline and get the results back.
And we just send it to pretrained lightpipeline and get the results back.
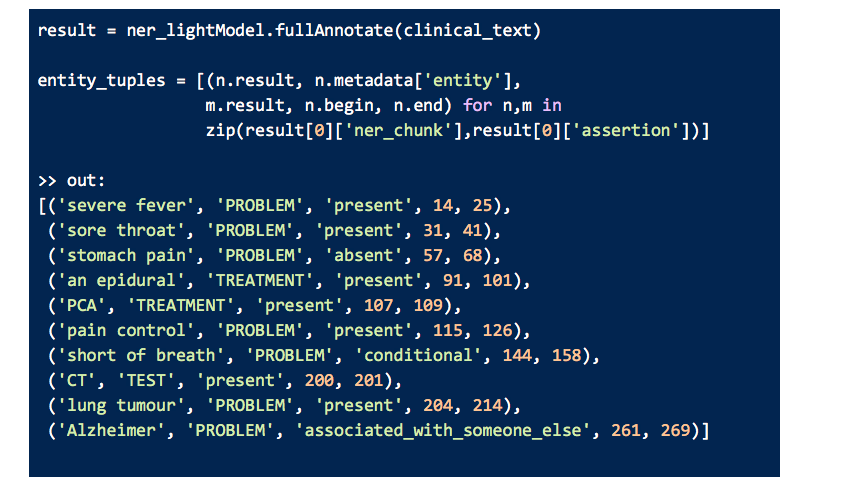
As you can see, we get the clinical entities, assertions and start-end indices.
We can also print this out as a pandas data frame.
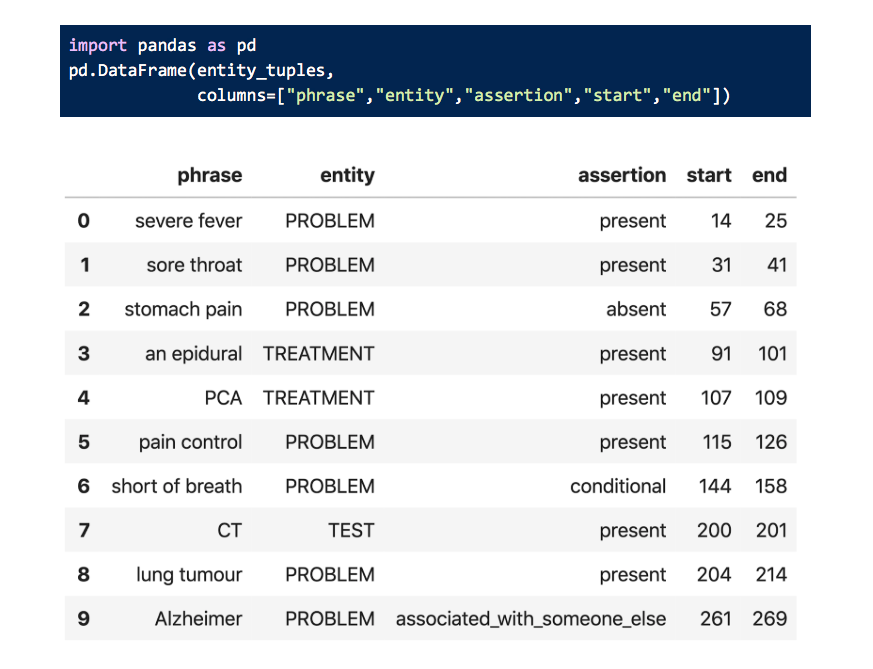
It’s really exciting to see that the model correctly assigned ‘associated_with_someone_else’ for “Alzheimer” entity (Problem) when it sees the sentence “Father with Alzheimer.”
And it also finds that “short of breath” happens conditionally as it’s clear from the sentence that it happens while “climbing a flight of stair”.
You can find the notebook for this post here and more examples in Spark NLP workshop healthcare repo.
We hope that you already read the previous articles on our official Medium page, and started to play with Spark NLP. Here are the links for the other articles. Don’t forget to follow our page and stay tuned!
Introduction to Spark NLP: Foundations and Basic Components (Part-I)
Introduction to: Spark NLP: Installation and Getting Started (Part-II)
After reading the previous articles and exploring Spark NLP, you can enhance your understanding by integrating technologies such as Generative AI in Healthcare and Healthcare Chatbots. These tools can significantly improve data processing and interaction within the healthcare sector, streamlining clinical document analysis and patient engagement.



