Since Spark NLP is sitting on the shoulders of Apache Spark, it’s better to explain Spark NLP components with a reference to Spark itself.
Apache Spark, once a component of the Hadoop ecosystem, is now becoming the big-data platform of choice for enterprises mainly because of its ability to process streaming data. It is a powerful open-source engine that provides real-time stream processing, interactive processing, graph processing, in-memory processing as well as batch processing with very fast speed, ease of use and standard interface.
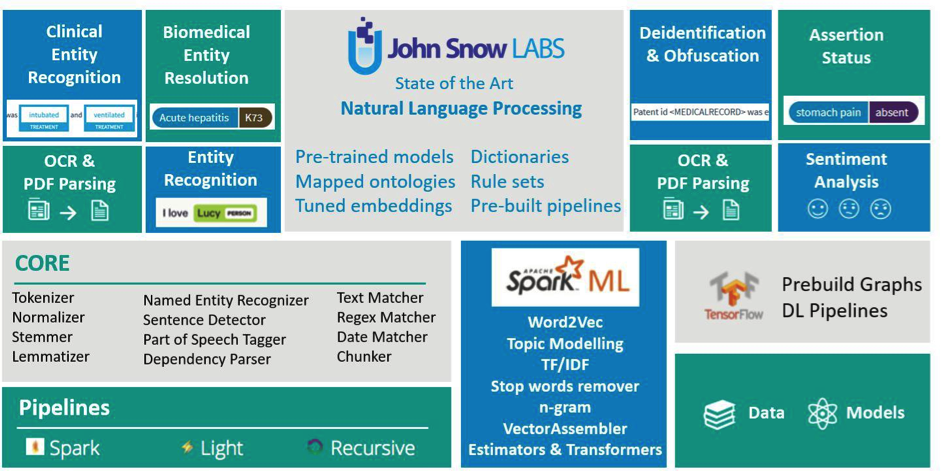 An overview of Spark NLP components
An overview of Spark NLP components
In the industry, there is a big demand for a powerful engine that can do all of the above. Sooner or later, your company or your clients will be using Spark to develop sophisticated models that would enable you to discover new opportunities or avoid risk. Spark is not hard to learn, if you already know Python and SQL, it is very easy to get started. To get familiar with Spark and its Python wrapper Pyspark, you can find the additional resources at the bottom of this article.
Spark has a module called Spark ML which introduces several ML components. Estimators, which are trainable algorithms, and transformers which are either a result of training an estimator, or an algorithm that doesn’t require training at all. Both Estimators and Transformers can be part of a Pipeline, which is no more and no less than a sequence of steps that execute in order, and are probably depending on each other’s result.
Spark-NLPintroduces NLP annotators that merge within this framework and its algorithms are meant to predict in parallel. Now, let’s start by explaining each component in detail.
1. Annotators
In Spark NLP, all Annotators are either Estimators or Transformers as we see in Spark ML. An Estimator in Spark ML is an algorithm which can be fit on a DataFrame to produce a Transformer. E.g., a learning algorithm is an Estimator that trains on a DataFrame and produces a model. A Transformer is an algorithm that can transform one DataFrame into another DataFrame. E.g., an ML model is a Transformer that transforms a DataFrame with features into a DataFrame with predictions.
In Spark NLP, there are two types of annotators: AnnotatorApproach and AnnotatorModel.
AnnotatorApproach extends Estimators from Spark ML, which are meant to be trained through fit(), and AnnotatorModel extends Transformers which are meant to transform data frames through transform().
Some of Spark NLP annotators have a Model suffix and some do not. The model suffix is explicitly stated when the annotator is the result of a training process. Some annotators, such as Tokenizer are transformers but do not contain the suffix Model since they are not trained, annotators. Model annotators have a pre-trained() on its static object, to retrieve the public pre-trained version of a model.
Long story short, if it trains on a DataFrame and produces a model, it’s an AnnotatorApproach; and if it transforms one DataFrame into another DataFrame through some models, it’s an AnnotatorModel (e.g. WordEmbeddingsModel) and it doesn’t take Model suffix if it doesn’t rely on a pre-trained annotator while transforming a DataFrame (e.g. Tokenizer).
You can find the list of annotators offered by Spark NLP v2.2.2 at this link.
By convention, there are three possible names:
Approach— Trainable annotator
Model— Trained annotator
nothing— Either a non-trainable annotator with pre-processing step or shorthand for a model
So for example, Stemmer doesn’t say Approach nor Model, however, it is a Model. On the other hand, Tokenizer doesn’t say Approach nor Model, but it has a TokenizerModel(). Because it is not “training” anything, but it is doing some preprocessing before converting into a Model.
When in doubt, please refer to official documentation.
Even though we will do many hands-on practices in the following articles, let us give you a glimpse to let you understand the difference between AnnotatorApproach and AnnotatorModel.
As stated above, Tokenizer is an AnnotatorModel. So we need to call fit() and then transform().

On the other hand, Stemmer is an AnnotatorApproach. So we just need to call transform().

You will get to learn all these parameters and syntax later on. So, don’t bother trying to reproduce these code snippets before we get into that part.
Another important point is that each annotator accepts certain types of columns and outputs new columns in another type (we call this AnnotatorType). In Spark NLP, we have the following types: Document, token, chunk, pos, word_embeddings, date, entity, sentiment, named_entity, dependency, labeled_dependency. That is, the DataFrame you have needs to have a column from one of these types if that column will be fed into an annotator; otherwise, you’d need to use one of the Spark NLP transformers. We will talk about this concept in detail later on.
2. Pre-trained Models
We mentioned that trained annotators are called AnnotatorModel and the goal here is to transform one DataFrame into another through the specified model (trained annotator). Spark NLP offers the following pre-trained models in four languages (English, French, German, Italian) and all you need to do is to load the pre-trained model into your disk by specifying the model name and then configuring the model parameters as per your use case and dataset. Then you will not need to worry about training a new model from scratch and will be able to enjoy the pre-trained SOTA algorithms directly applied to your own data with transform(). In the official documentation, you can find detailed information regarding how these models are trained by using which algorithms and datasets.
You can find the list of pre-trained models offered by Spark NLP v2.2.2 at this link.

3. Transformers
Remember that we talked about certain types of columns that each Annotator accepts or outputs. So, what are we going to do if our DataFrame doesn’t have columns in those types? Here come transformers. In Spark NLP, we have five different transformers that are mainly used for getting the data in or transform the data from one AnnotatorType to another. Here is the list of transformers:
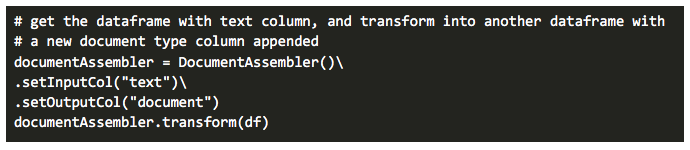
DocumentAssembler: To get through the NLP process, we need to get raw data annotated. This is a special transformer that does this for us; it creates the first annotation of type Document which may be used by annotators down the road.
TokenAssembler: This transformer reconstructs a Document type annotation from tokens, usually after these have been normalized, lemmatized, normalized, spell checked, etc, to use this document annotation in further annotators.
Doc2Chunk: Converts DOCUMENT type annotations into CHUNK type with the contents of a chunkCol.
Chunk2Doc: Converts a CHUNK type column back into DOCUMENT. Useful when trying to re-tokenize or do further analysis on a CHUNK result.
Finisher: Once we have our NLP pipeline ready to go, we might want to use our annotation results somewhere else where it is easy to use. The Finisher outputs annotation(s) values into a string.
4. Pipeline
We mentioned before that Spark NLP provides an easy API to integrate with Spark ML Pipelines and all the Spark NLP annotators and transformers can be used within Spark ML Pipelines. So, it’s better to explain Pipeline concept through Spark ML official documentation.
What is a Pipeline anyway? In machine learning, it is common to run a sequence of algorithms to process and learn from data. E.g., a simple text document processing workflow might include several stages:
- Split each document’s text into sentences and tokens (words).
- Normalize the tokens by applying some text preprocessing techniques (cleaning, lemmatizing, stemming, etc.)
- Convert each token into a numerical feature vector (e.g. word embeddings, tfidf, etc.).
- Learn a prediction model using the feature vectors and labels.
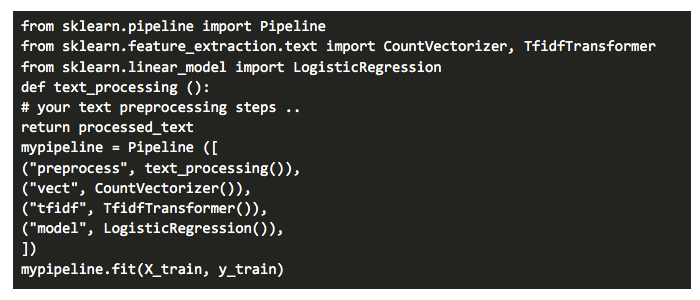
This is how such a flow can be written as a pipeline with sklearn, a popular Python ML library.
Apache Spark ML represents such a workflow as a Pipeline, which consists of a sequence of Pipeline Stages (Transformers and Estimators) to be run in a specific order.
In simple terms, a pipeline chains multiple Transformers and Estimators together to specify an ML workflow. We use Pipeline to chain multiple Transformers and Estimators together to specify our machine learning workflow.
The figure below is for the training time usage of a Pipeline.
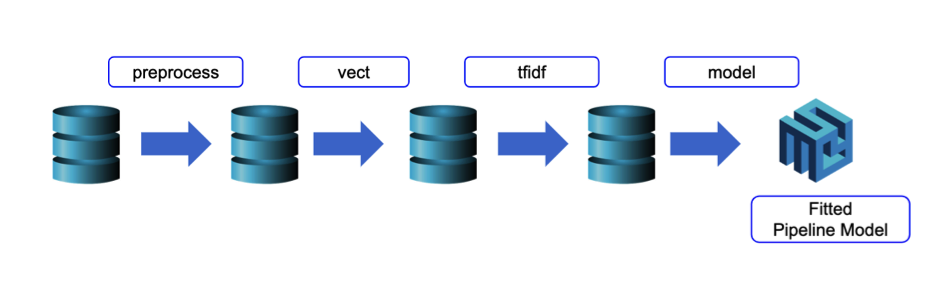
A Pipeline is specified as a sequence of stages, and each stage is either a Transformer or an Estimator. These stages are run in order, and the input DataFrame is transformed as it passes through each stage. That is, the data are passed through the fitted pipeline in order. Each stage’s transform() method updates the dataset and passes it to the next stage. With the help of Pipelines, we can ensure that training and test data go through identical feature processing steps.
Now let’s see how this can be done in Spark NLP using Annotators and Transformers. Assume that we have the following steps that need to be applied one by one on a data frame.
- Split text into sentences
- Tokenize
- Normalize
- Get word embeddings
And here is how we code this pipeline up in Spark NLP.
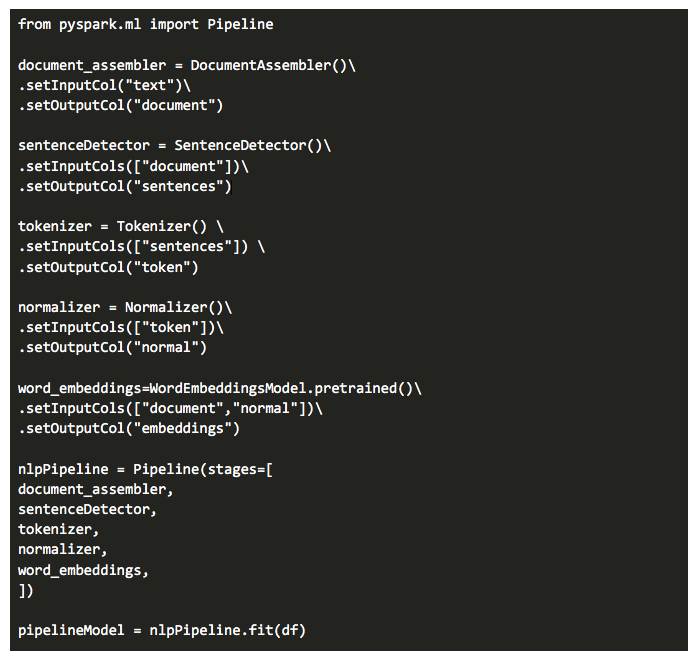
Let’s see what’s going on here. As you can see from the flow diagram below, each generated (output) column is pointed to the next annotator as an input depending on the input column specifications. It’s like building-blocks and legos through which you can come up with amazing pipelines with a little bit of creativity.
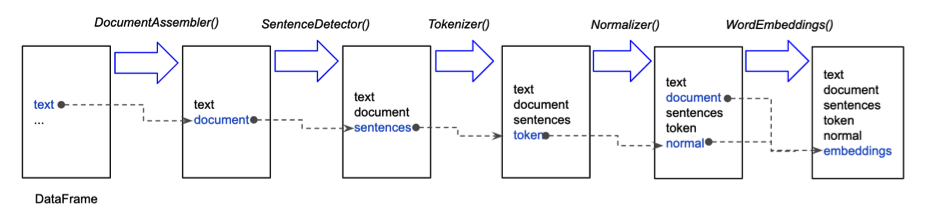
What’s actually happening under the hood?
When we fit() on the pipeline with Spark data frame (df), its text column is fed into DocumentAssembler() transformer at first and then a new column “document” is created in Document type (AnnotatorType). As we mentioned before, this transformer is basically the initial entry point to Spark NLP for any Spark data frame. Then its document column is fed into SentenceDetector()(AnnotatorApproach) and the text is split into an array of sentences and a new column “sentences” in Document type is created. Then “sentences” column is fed into Tokenizer() (AnnotatorModel) and each sentence is tokenized and a new column “token” in Token type is created. And so on. You’ll learn all these rules and steps in detail in the following articles, so we’re not elaborating much here.
In addition to customized pipelines, Spark NLP also has pre-trained pipelines that are already fitted using certain annotators and transformers according to various use cases.
We will explain all these pipelines in the following articles but let’s give you an example using one of these pipelines.
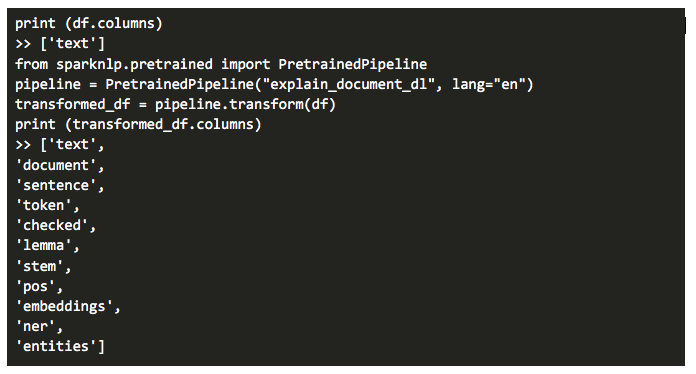
Here are the NLP annotators we have in “explain_document_dl” pipeline:
- DocumentAssembler
- SentenceDetector
- Tokenizer
- LemmatizerModel
- Stemmer
- PerceptronModel
- ContextSpellCheckerModel
- WordEmbeddings (GloVe 6B 100)
- NerDLModel
- NerConverter (chunking)
All these annotators are already trained and tuned with SOTA algorithms and ready to fire up at your service. So, when you call this pipeline, these annotators will be run under the hood and you will get a bunch of new columns generated through these annotators. To use pre-trained pipelines, all you need to do is to specify the pipeline name and then transform(). You can also design and train such kind of pipelines and then save them to your disk to use later on.
While saying SOTA algorithms, we really mean it. For example, NERDLModel is trained by NerDLApproach annotator with Char CNNs — BiLSTM — CRF and GloVe Embeddings on the WikiNER corpus and supports the identification of PER, LOC, ORG and MISC entities. According to a recent survey paper, this DL architecture achieved the highest scores for NER. So, with just one single line of code, you get a SOTA result!
5. Conclusion
In this article, we tried to get you familiar with the basics of Spark NLP and its building blocks. Being used in enterprise projects, built natively on Apache Spark and TensorFlow and offering an all-in-one state of the art NLP solutions, Spark NLP library provides simple, performant as well as accurate NLP notations for machine learning pipelines which can scale easily in a distributed environment. Despite its steep learning curve and sophisticated framework, the virtual developer team behind this amazing library pushes the limits to implement and cover the recent breakthroughs in NLP studies and strives to make it easy to implement into your daily workflows.
In the following articles, we plan to cover all the details with clear code samples both in Python and Scala. Till then, feel free to visit Spark NLP workshop repository or take a look at the following resources. Welcome to the amazing world of Spark NLP and stay tuned!
As the field continues to evolve, the integration of Generative AI in Healthcare and the development of advanced Healthcare Chatbot solutions are transforming patient care, enhancing efficiency, and improving overall healthcare delivery.
Resources
https://www.oreilly.com/radar/one-simple-chart-who-is-interested-in-spark-nlp/
https://blog.dominodatalab.com/comparing-the-functionality-of-open-source-natural-language-processing-libraries/
https://medium.com/@saif1988/spark-nlp-walkthrough-powered-by-tensorflow-9965538663fd
https://www.infoworld.com/article/2243822/why-you-should-use-spark-for-machine-learning.html
http://ruder.io/state-of-transfer-learning-in-nlp/