























































Healthcare AI teams annotate thousands of clinical documents every week. Discharge summaries. Procedure notes. Lab reports. Referral letters. Most arrive as PDFs, sometimes scanned, sometimes native, often a mix of both.
Extracting text from these documents for NER annotation isn’t just about getting the words out. It’s about preserving the structure that makes those words intelligible. A report with sections loses meaning when those sections get linearized into a flat stream.Multi-paragraph notes become harder to annotate when paragraph boundaries disappear. Tables extracted out of sequence create confusion about what data relates to what.
The gap between accurate text extraction and usable annotation input is where NER workflows break down.
Generative AI Lab offers built-in PDF text extraction that preserves document structure, eliminating the need for external OCR servers while improving annotation quality.
The Structure Problem in PDF Text Extraction
Entity annotation depends on context. Annotators need to understand what they’re reading to label entities correctly. A medication name in the “Current Medications” section means something different from the same medication mentioned in “Allergies.” A procedure in a surgery report header carries a different meaning from a procedure mentioned in the follow-up.
When PDF text extraction flattens document structure, that context degrades. Traditional OCR often produces:
- Broken reading order. Text from different sections gets interleaved unpredictably. A two-column layout produces tokens that jump between columns mid-sentence.
- Lost paragraph boundaries. Multi-paragraph clinical notes become wall-of-text blocks where logical breaks disappear, making it harder to track context during annotation.
- Excessive whitespace and formatting noise. Extracted text includes artifacts, extra line breaks, misplaced spaces, header/footer fragments, that don’t reflect the actual document content.
- Misaligned table data. Tables get extracted as disconnected text fragments, losing the visual column representation that gives the data meaning.
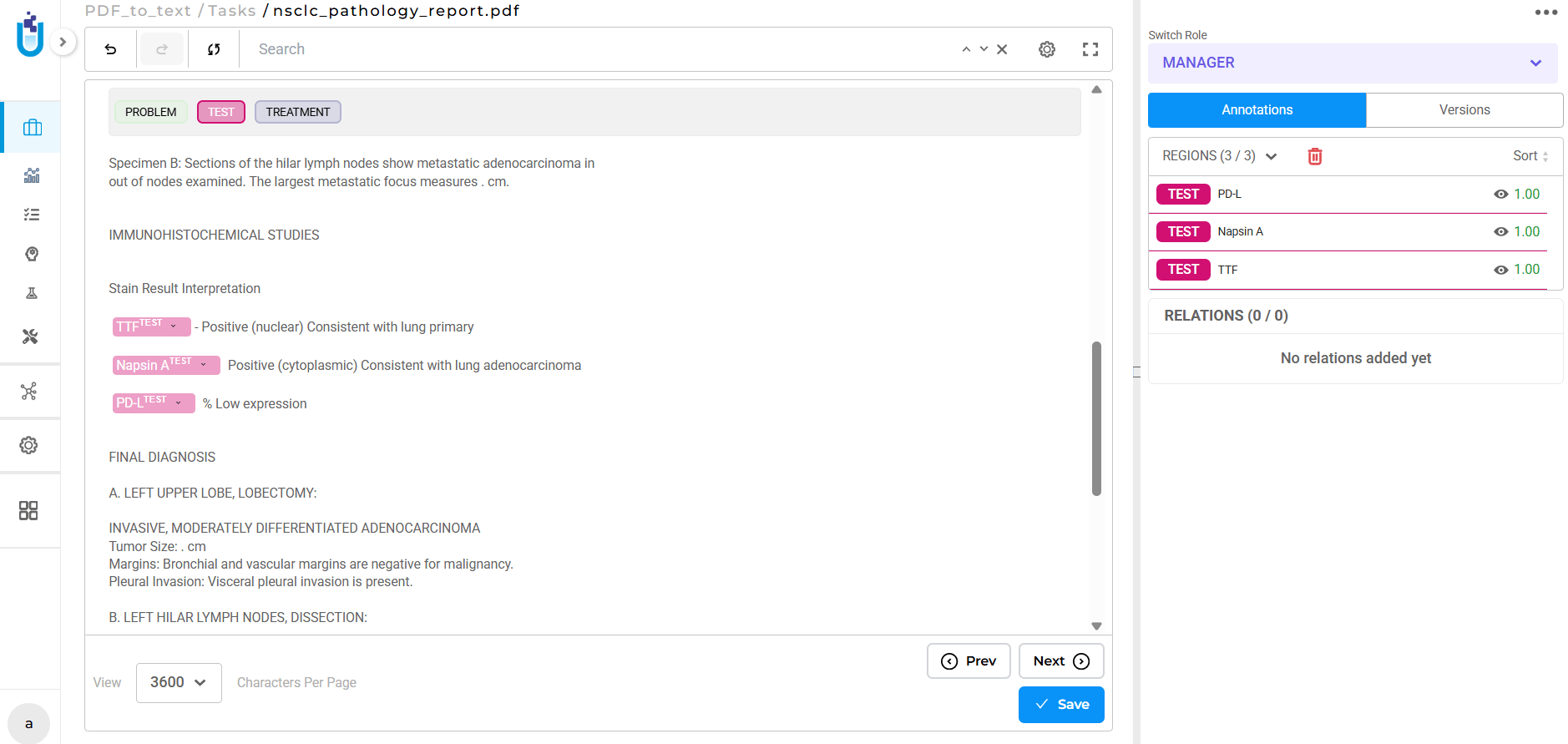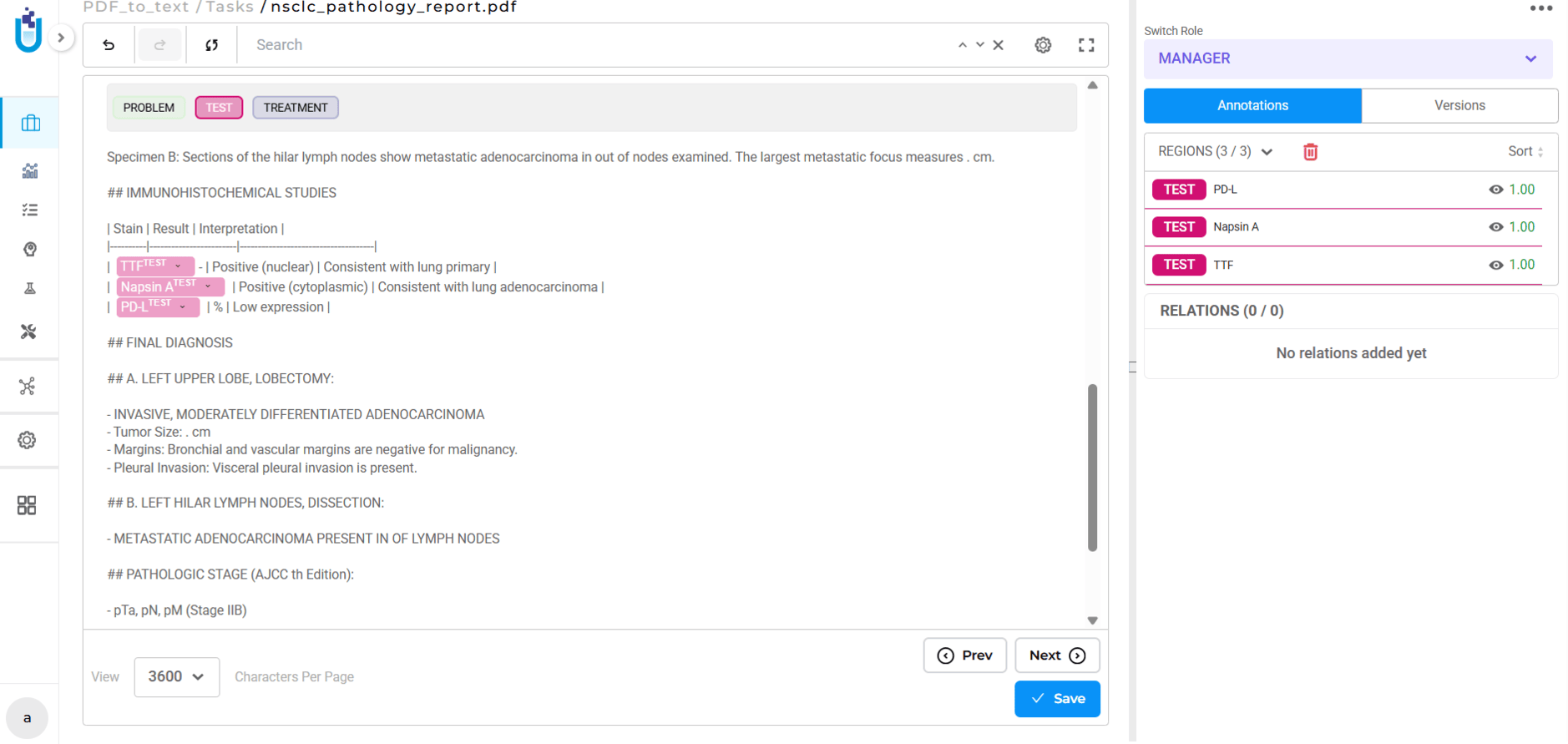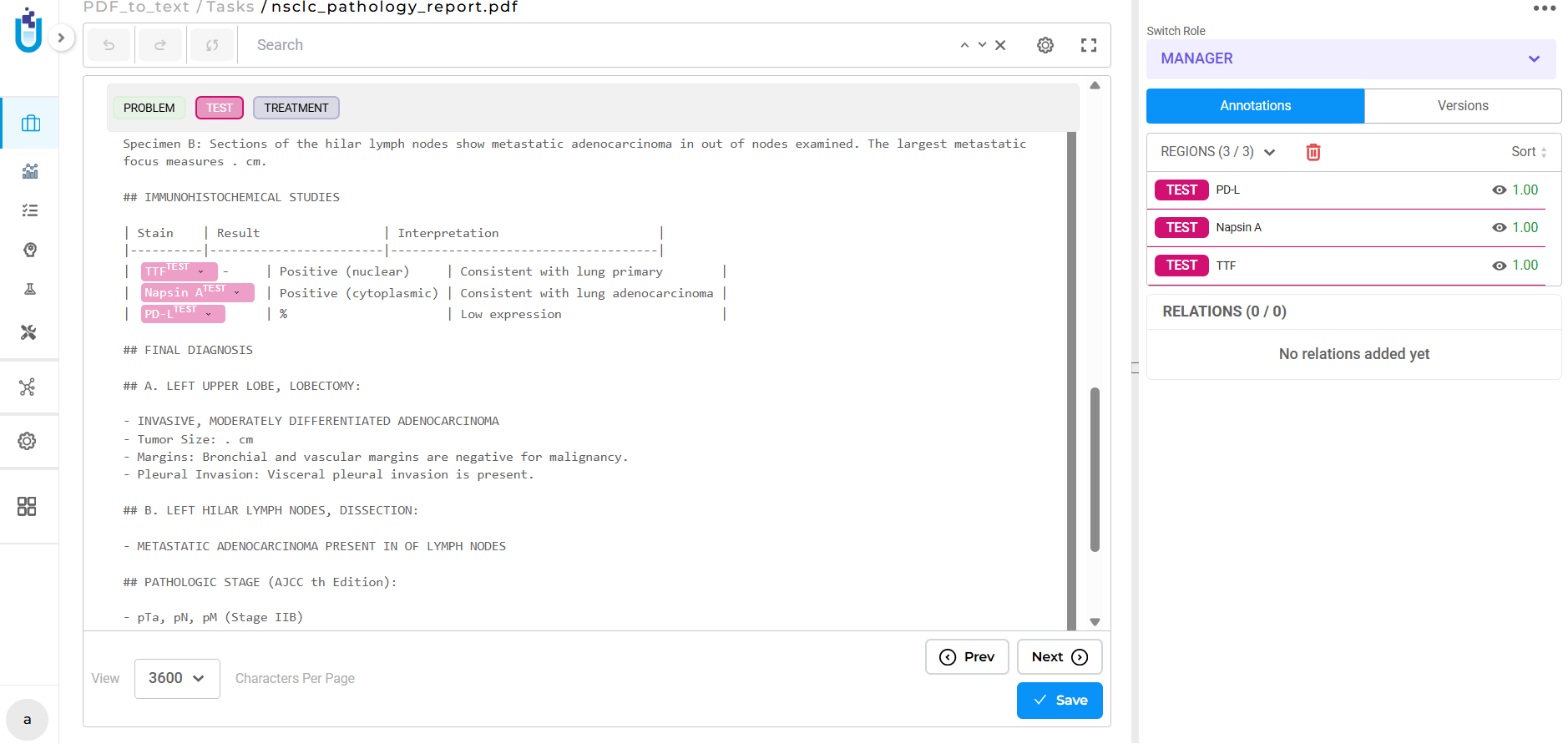
These aren’t minor formatting issues. They’re structural problems that make annotation slower and less accurate. Annotators spend time interpreting malformed text rather than labeling entities. Context gets lost. Quality degrades.
What Built-In Text Extraction Provides
In Generative AI Lab, PDF text extraction is integrated directly into the platform for NER text-based projects. No external OCR server deployment required. No additional setup. The extraction engine processes PDFs, scanned documents, and image-based files, optimizing the output for NER annotation workflows.
The key difference is structure preservation. Where traditional OCR returns text as a linear stream, the built-in extraction maintains:
- Logical reading order. Text flows the way it appears on the page, top to bottom, left to right, even in multi-column layouts. Sections stay sequential. Paragraphs remain intact.
- Paragraph boundaries and section breaks. The extraction preserves document organization: headings, sections, paragraph separations. This keeps context clear during annotation.
- Clean formatting. Excessive whitespace, broken lines, and OCR artifacts are minimized. The extracted text reflects actual content, not formatting noise.
- Stable, consistent output. Repeated imports of the same document produce the same text extraction, ensuring annotation consistency across projects.
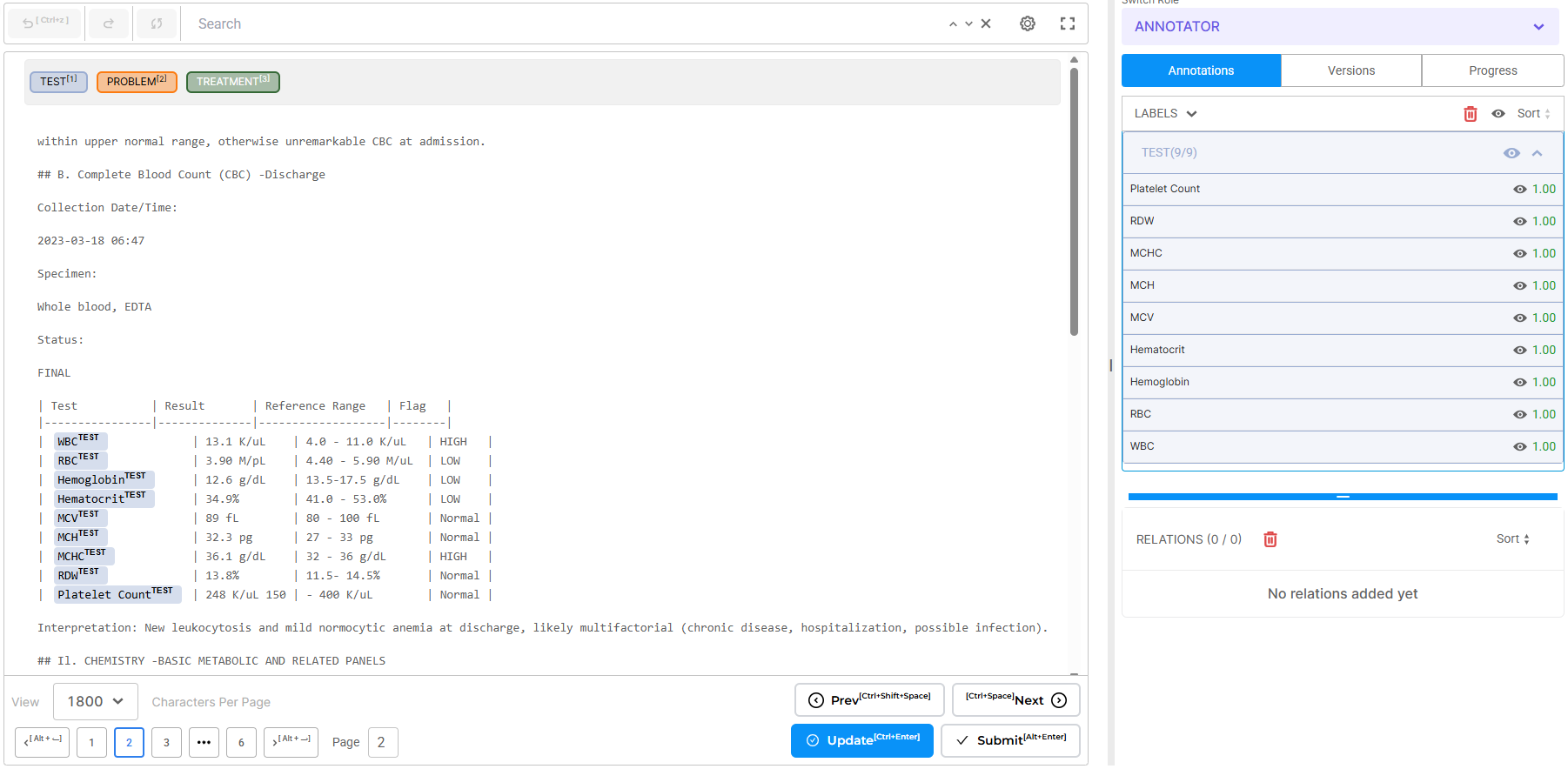
The extracted content maps automatically into the NER task format, with source file references and page-level markers retained for traceability.
How It Works in Practice
When a user imports a PDF into an NER project, the new Import page offers “Text Extraction from PDFs ” as a built-in option. No server configuration. No pipeline deployment. The extraction runs as part of the import process.
For a structured clinical report with sections, headings, and detailed content, the engine preserves that organization. Annotators see text that reflects the document’s actual layout: sections appear in order, paragraphs are separated, headers are distinct from body text.
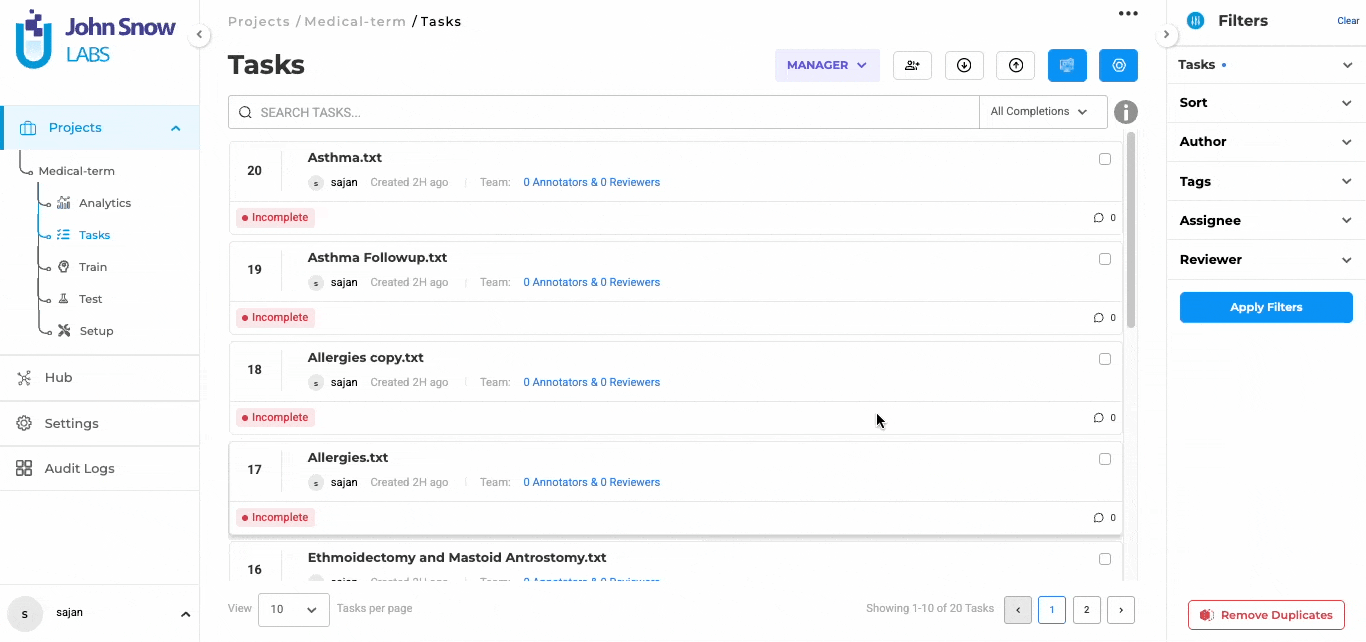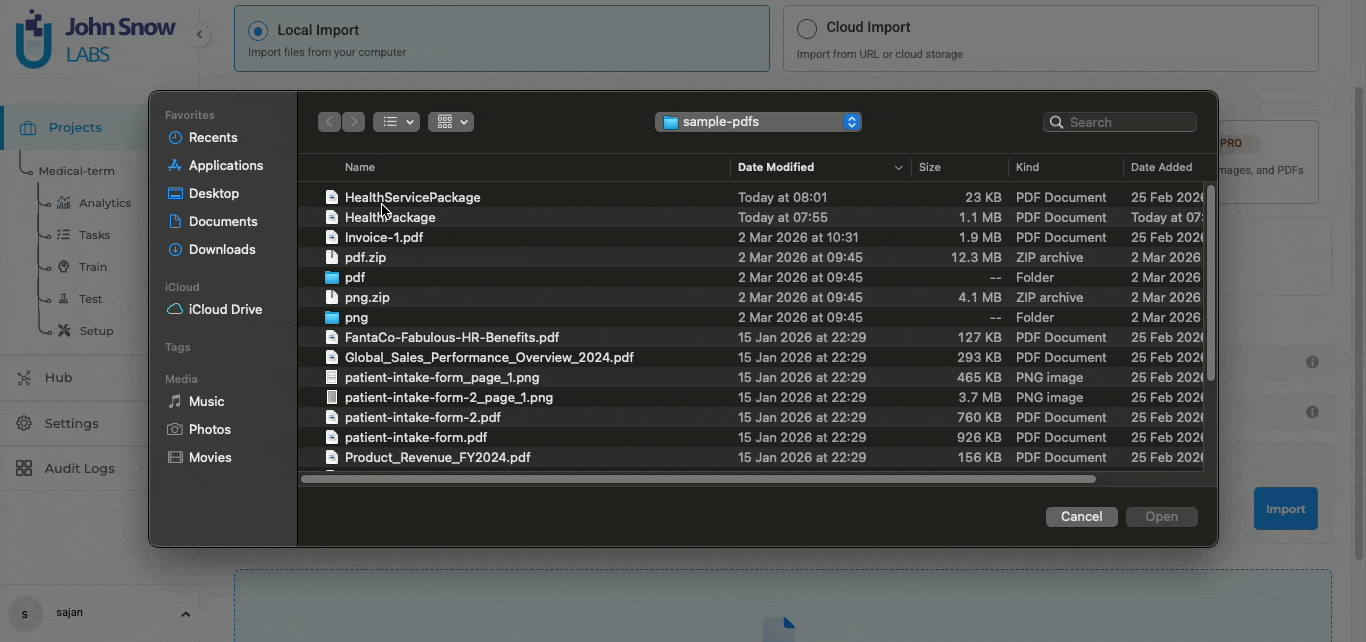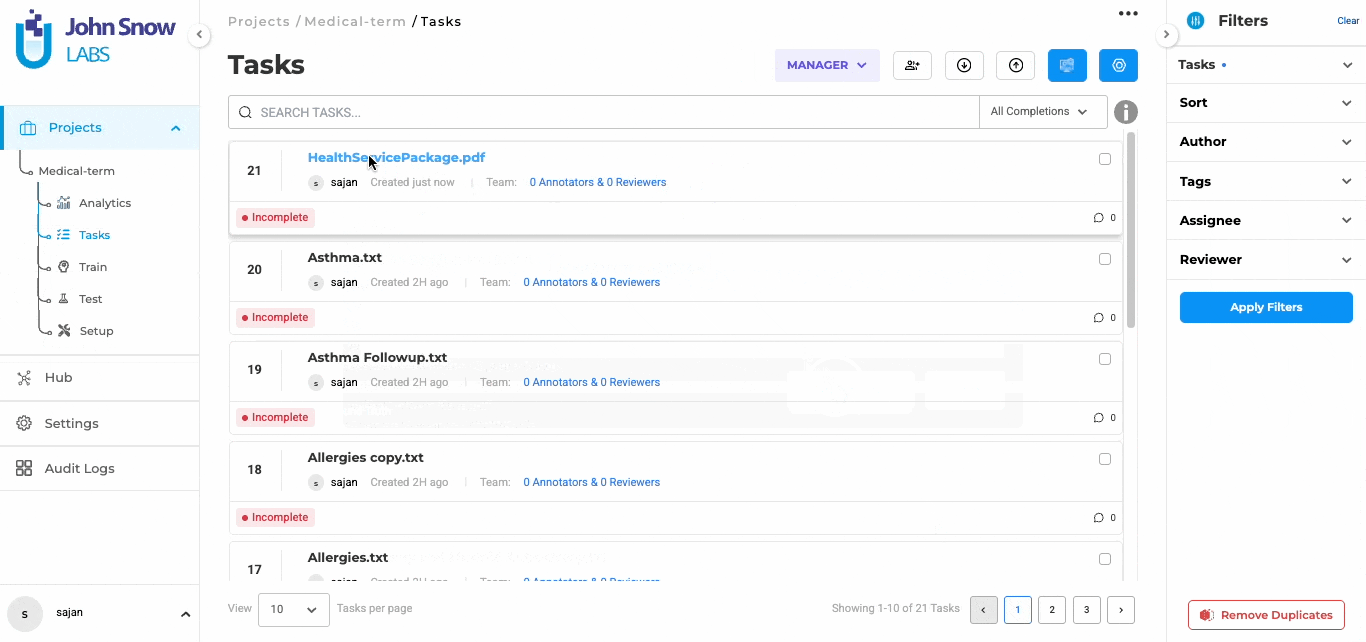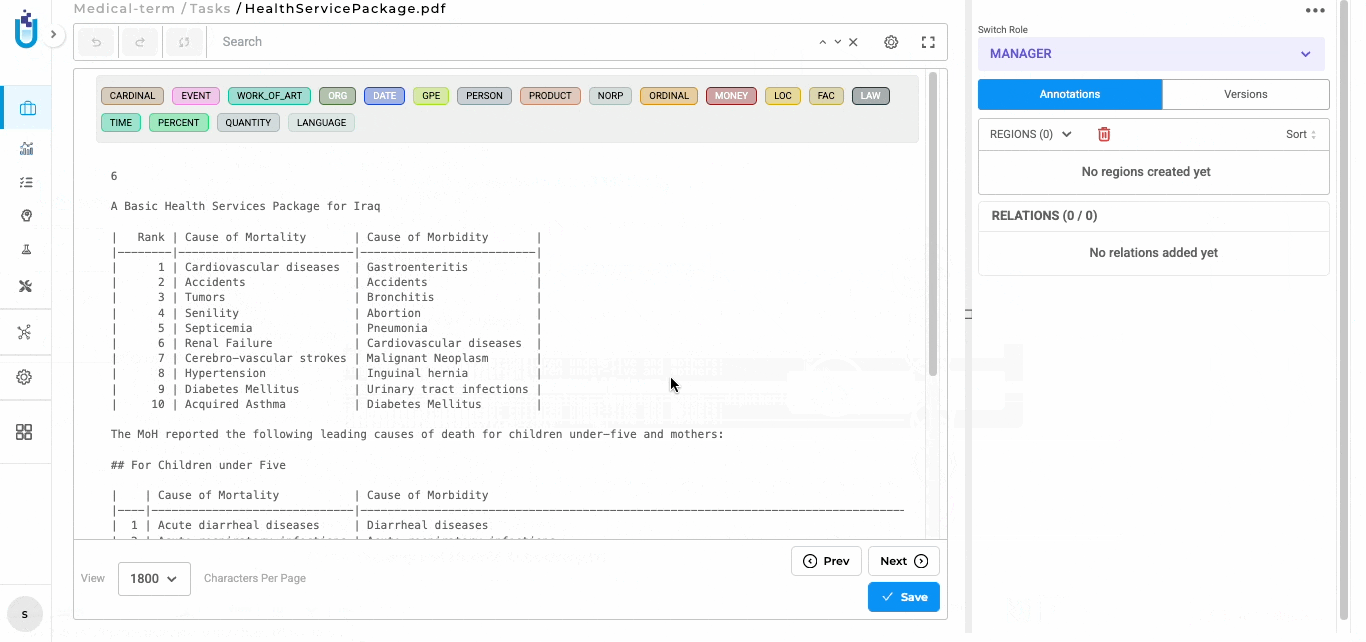
This matters because annotation quality depends on readability. When text structure is preserved, annotators understand context immediately. They don’t need to cross-reference the original PDF to figure out which section they’re reading or where paragraph breaks should be. The extracted text is annotation-ready.
For teams processing mixed document types, native PDFs with complex layouts, scanned intake forms, reports with tables, the extraction handles all of them. Native PDFs get parsed for text while preserving layout structure. Scanned documents go through OCR with the same structure-aware processing. Tables maintain their organization where possible.The extracted text requires minimal configuration.
Projects need to include a specific XML setup to support the improved formatting:
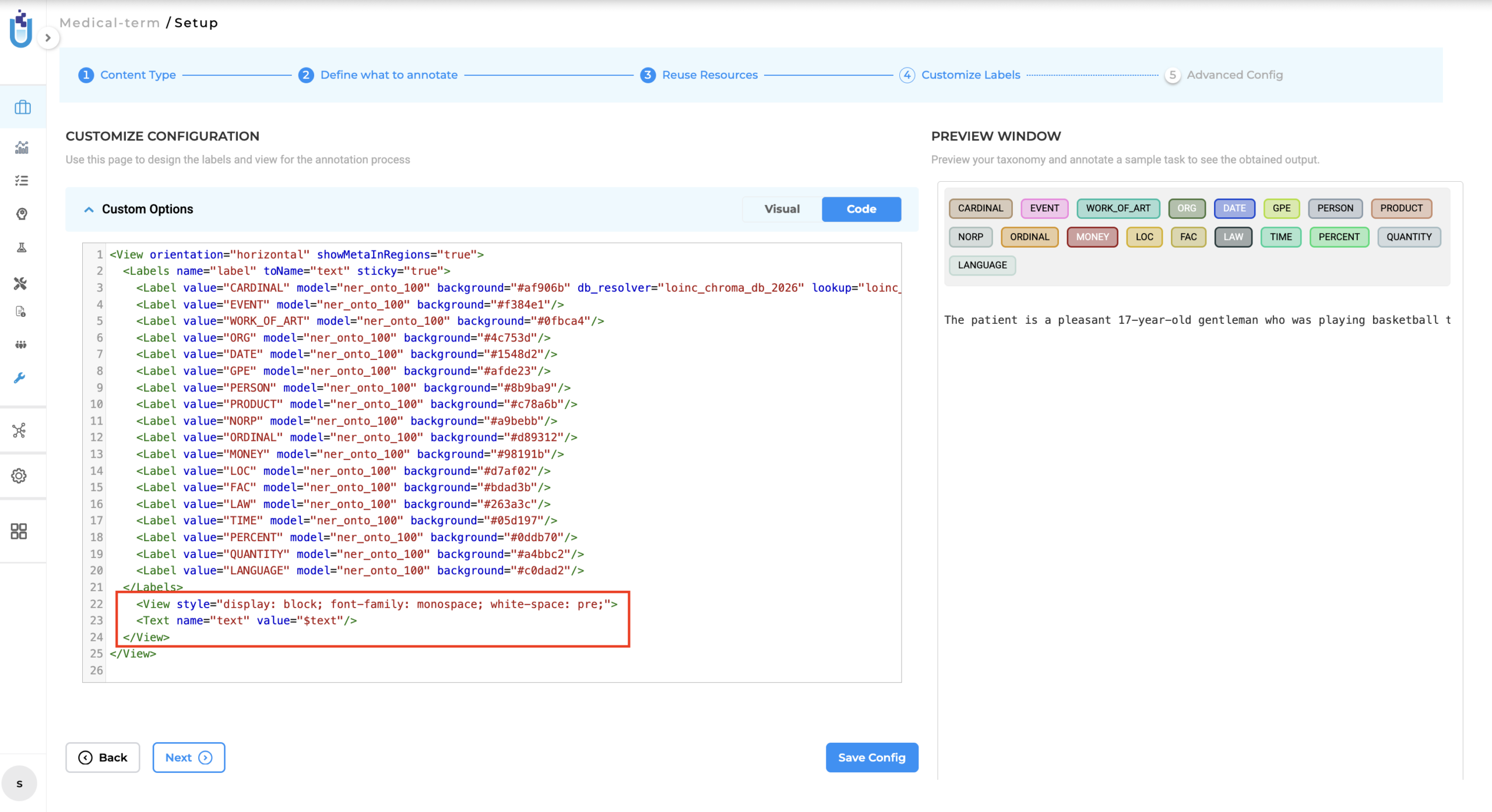
This ensures text renders with preserved formatting in the annotation interface, maintaining the structure that was extracted.
What Changes for NER Annotation Teams
- No external OCR setup required. Teams working on NER projects can extract text from PDFs directly within the platform. No separate OCR server to deploy, configure, or maintain. Import workflow stays simple.
- Better annotation context. Preserved document structure means annotators see logical sections, paragraph breaks, and clean text. Context is clearer. Annotation decisions are more accurate because the text reflects how the document was actually organized.
- More consistent outputs. Stable extraction across repeated imports means the same PDF produces the same text every time. This consistency matters for quality control and for teams re-importing documents during iterative annotation workflows.
- Reduced formatting cleanup. Fewer broken lines, less excessive whitespace, cleaner separation between sections. Annotators spend less time interpreting malformed text and more time labeling entities.
- Flexible OCR strategy. The built-in extraction handles standard PDF workflows reliably with no setup. For teams that need higher precision, domain-specific documents, complex layouts, strict accuracy requirements, advanced OCR capabilities are available as a seamless upgrade. Teams can start simple and scale to enterprise-grade accuracy when needed.
Why This Matters for Healthcare NLP at Scale
Clinical NLP models are only as good as the training data they learn from. And training data quality depends heavily on annotation accuracy, which depends on whether annotators can clearly understand the text they’re labeling.
When PDF extraction produces poorly structured text, annotation quality suffers in ways that cascade into model performance. Entity boundaries get misidentified because paragraph breaks are unclear. Labels get applied to wrong sections because reading order was scrambled. Training examples look reasonable in isolation but lack the structural context that makes them meaningful.
Built-in text extraction with structure preservation addresses this at the source. By producing clean, well-organized text from the start, it ensures that what annotators see reflects the actual document, and that what they label becomes high-quality training data.
For healthcare organizations building NER models that need to perform reliably on the diverse, complex, and sometimes messy documents that make up real clinical workflows, that text quality isn’t optional. It’s the foundation.
Next Steps
Ready to see how PDF integration improves annotation accuracy on your clinical documents?
Full technical details are available in the release notes:
👉 https://nlp.johnsnowlabs.com/docs/en/alab/release_notes
Questions about Visual NER projects, document ingestion, or annotation workflows? Our team is here to help.




