























































In the first two posts of this series, we benchmarked OCR on two increasingly demanding tasks:
- Grounded (BBox) OCR, reading text AND returning its coordinates
- Image → Markdown OCR, plain-text extraction for RAG / search / summarization
This third post tackles the task that actually gets shipped to production in healthcare, insurance, and regulated workflows: schema-constrained JSON extraction. You give the model an image and a JSON Schema. You expect back valid JSON that conforms to that schema, with the right values in the right fields.
Most models fail this test. A few succeed. One thing the benchmark makes painfully clear:
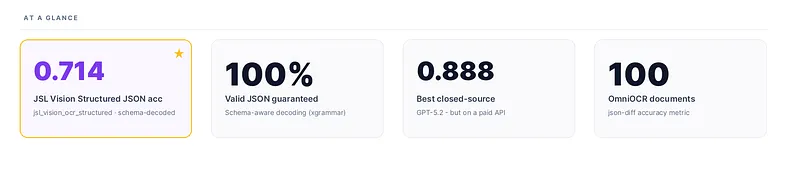
Best at OCR ≠ best at schema-following. The best OCR model by flat-text CER (JSL Vision) isn’t the best JSON extractor. The best chat model (Claude Opus 4.5) isn’t either. The winner is GPT-5.2, a model that barely cracked the top 14 on plain OCR.
What “JSON-schema OCR” looks like
The task takes two inputs (a JSON Schema and a document image) and produces structured JSON that conforms to the schema:
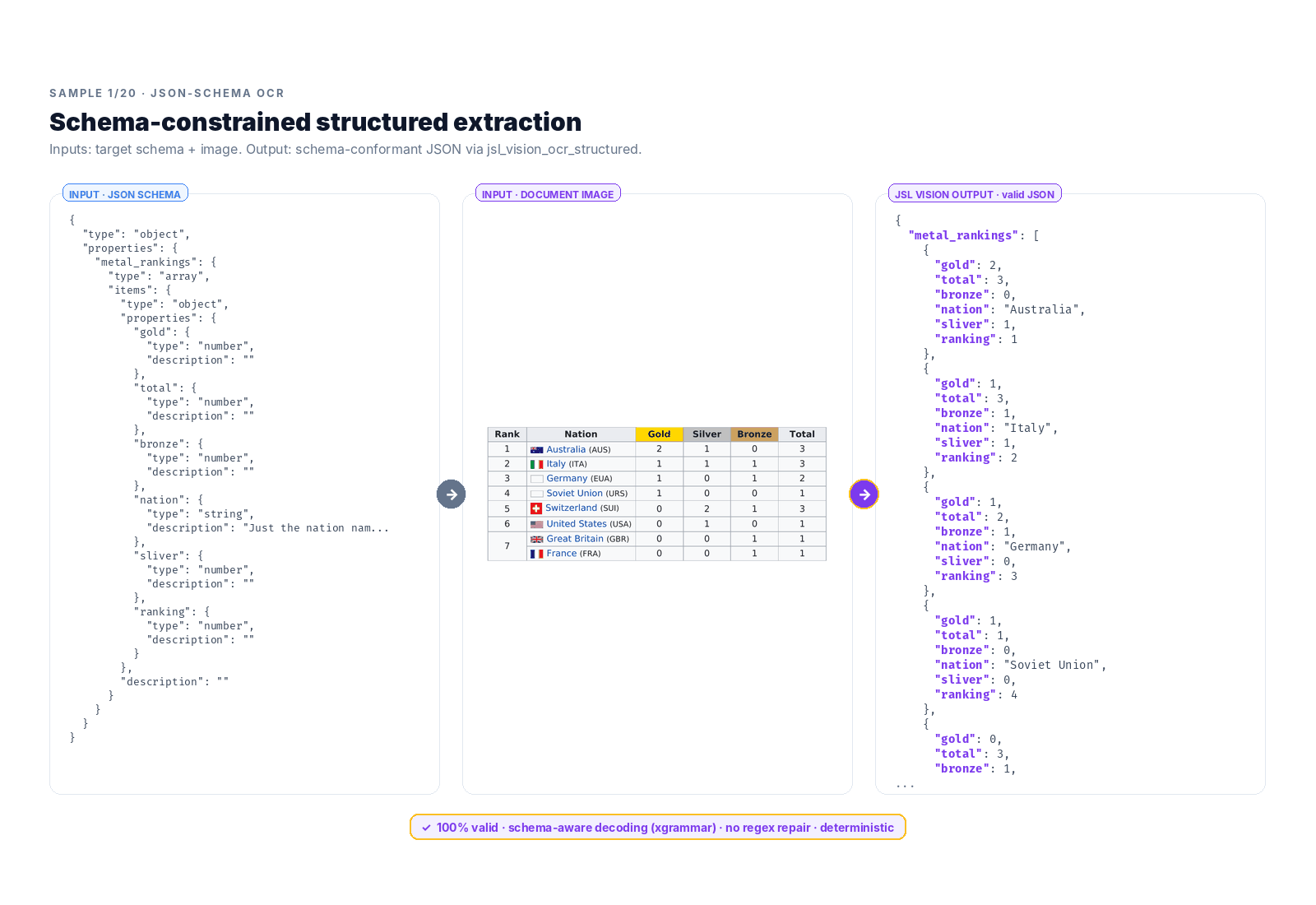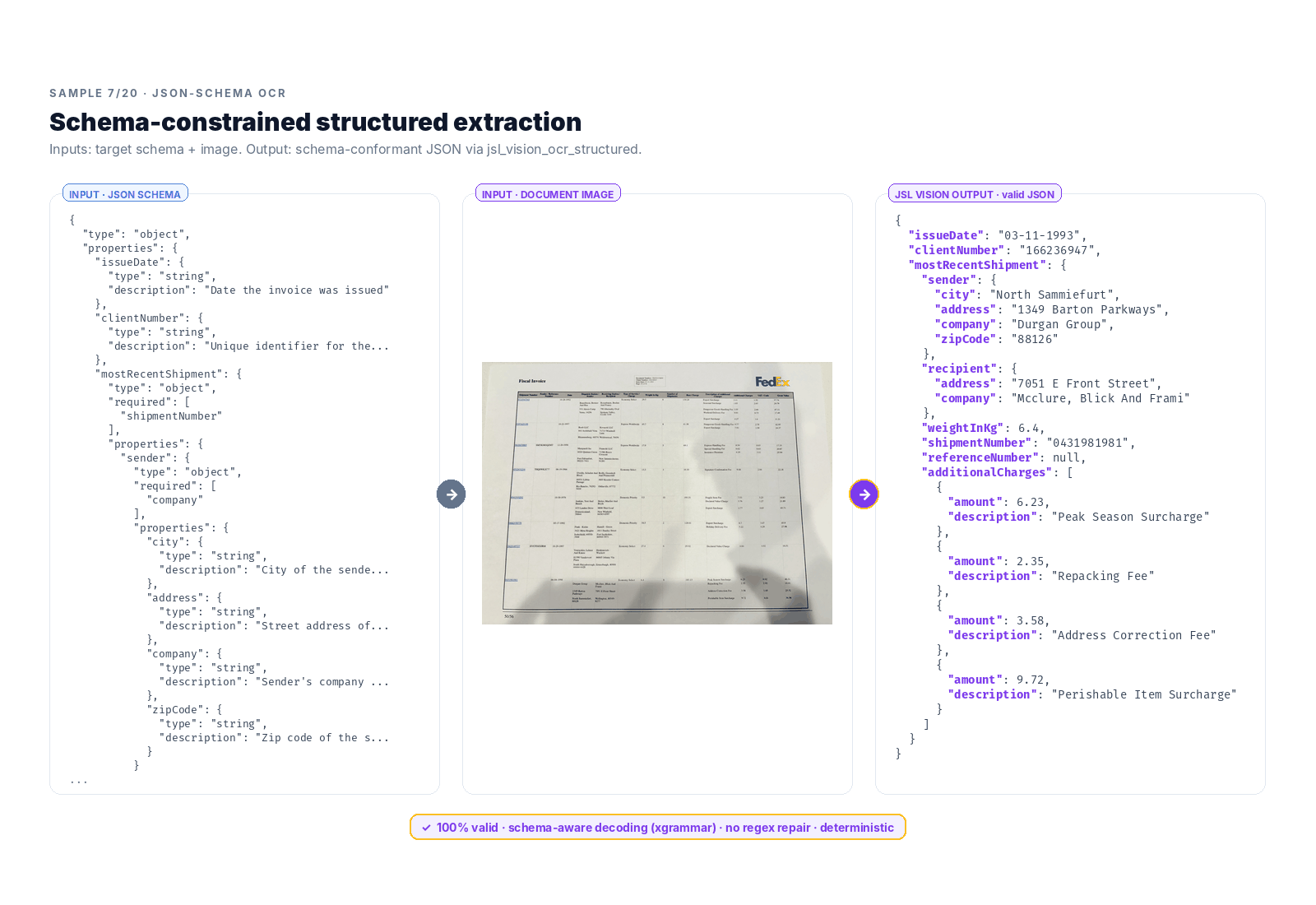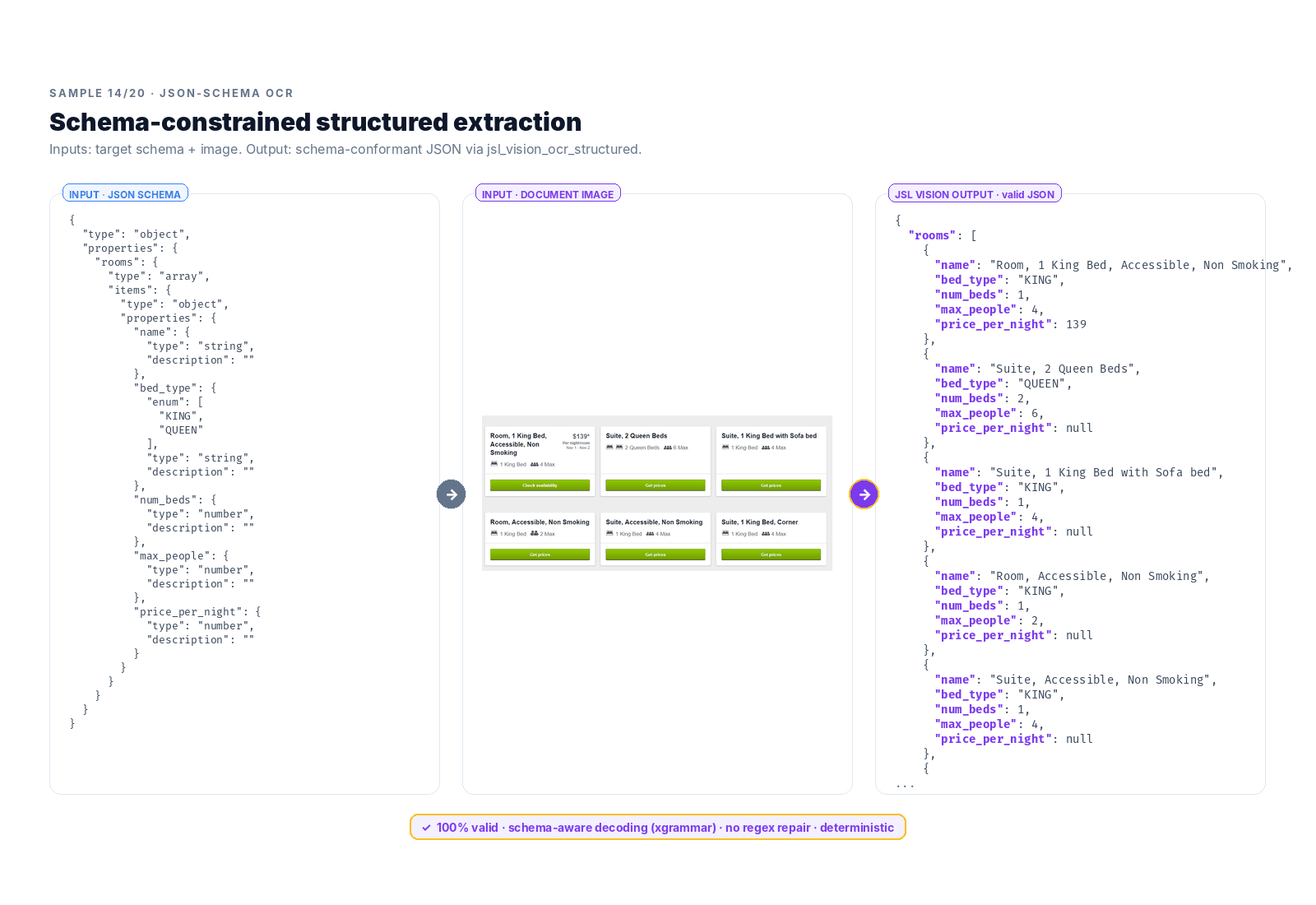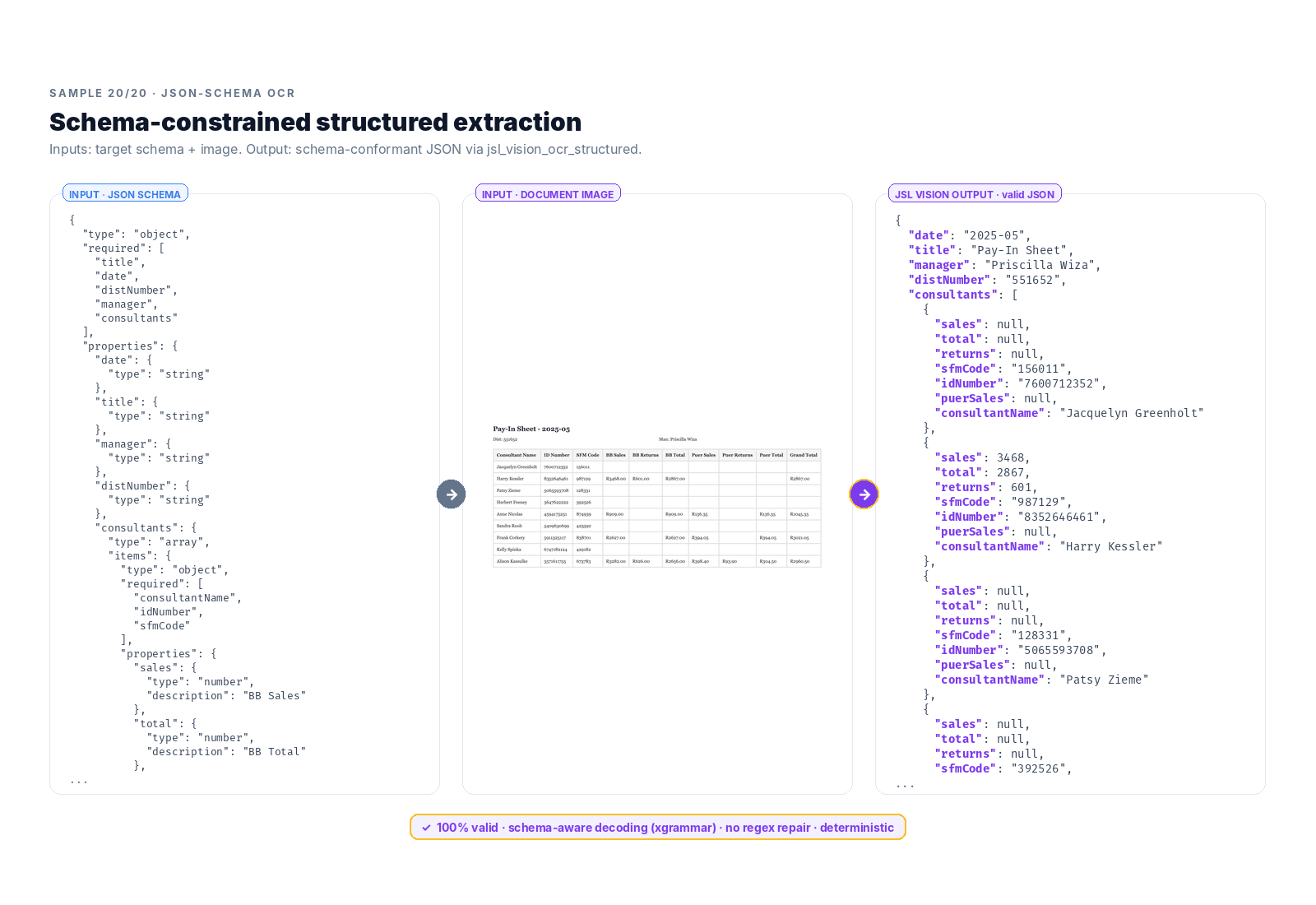
This is the real shape of enterprise document AI. EHR fields, claims line items, lab measurements, invoice totals: all of it lives downstream of a model that can take a schema, read a page, and produce valid structured data.
Why JSON is the real enterprise benchmark
Most enterprise OCR pipelines don’t end at “extract the text.” They end at “populate this form in our downstream system”:
- EHR ingestion, map lab values, diagnoses, medications into structured records
- Claims automation, extract policy number, diagnosis code, procedure code, amount
- Clinical trial data capture, CRF fields, timestamps, measurements
- Form parsing, tax forms, insurance intake, onboarding paperwork
For these workflows, “the OCR was 95% accurate” is not a success metric. What matters is:
Did the model emit valid JSON that conforms to our schema with the right values in the right fields?
A prediction that’s 98% accurate but malformed is worse than useless: it crashes your pipeline.
One unexpected winner
The top of the leaderboard is dominated by closed-source frontier models, GPT-5.2 (0.888), Gemini 2.5 Flash (0.873), Gemini 2.5 Pro (0.840). JSL Vision Structured-8B (jsl_vision_ocr_structured) lands at #5 with 0.730, the #1 on-prem model, ahead of olmOCR-7B (0.714), Claude Sonnet 4.5 (0.709), Holo2-30B-A3B (0.684), Qwen3-VL-8B (0.676), and every other self-hosted model tested. JSL Vision-30B (jsl_vision) follows at #8 with 0.689, within 22% of the frontier leader and ahead of every closed-source model outside the OpenAI/Google/Anthropic tier.
Two results stand out. GPT-5.2, which underperformed on flat OCR (0.271 CER, last of 16 on the markdown leaderboard), wins the JSON benchmark outright. Why? Schema extraction is a structured-reasoning task: parse the schema, match image regions to fields, emit valid JSON in the right shape. That’s instruction-following, not transcription.
Second, Gemini 2.5 Flash beats Gemini 2.5 Pro (0.873 vs 0.840). At current pricing, Flash is strictly the better deal for JSON extraction.
Claude Opus 4.5 rounds out the top 4 at 0.800, ahead of Claude Sonnet 4.5 (0.709, #6) by a clear margin. For structured extraction, Opus significantly outperforms its sibling model, which is the opposite of their typical pricing relationship.
19 models, ranked
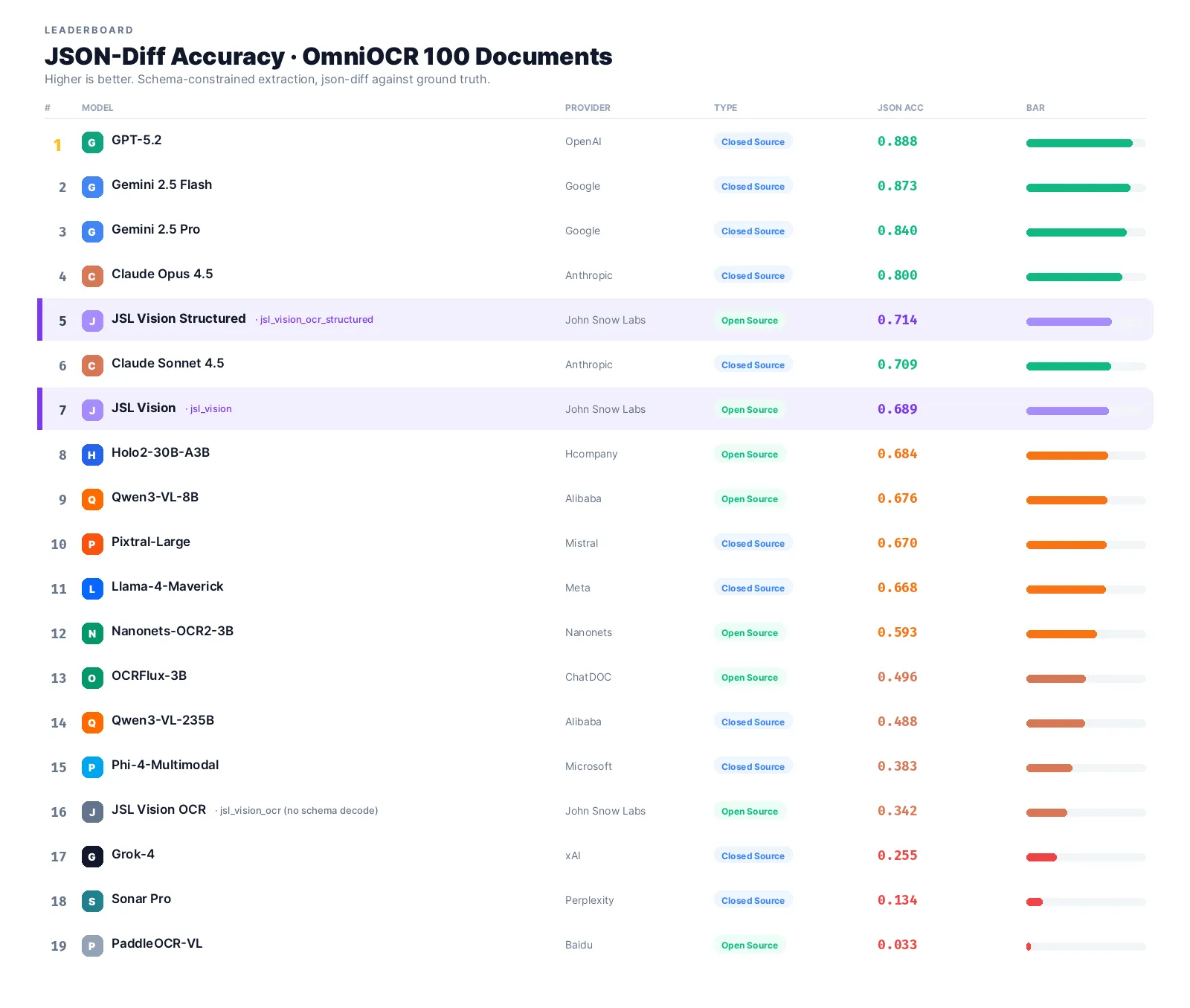
JSL Vision Structured-8B is #1 among on-prem models.
jsl_vision_ocr_structured (an 8B model built for structured document parsing and schema-constrained JSON extraction; it runs on a single A10G (24 GB VRAM)) scores 0.730, beating olmOCR-7B (0.714), Claude Sonnet 4.5 (0.709), and every other self-hosted model tested. Evaluated with xgrammar structured generation (which JSL Vision Structured ships with natively), its OCR capability translates directly into schema-compliant JSON.
JSL Vision-30B rounds out the on-prem podium.
jsl_vision, our 30B flagship VLM, scores 0.689, ahead of Hcompany’s Holo2-30B-A3B (0.684), Qwen3-VL-8B (0.676), and every closed-source model not named OpenAI, Google, or Anthropic. Combined with guaranteed-valid JSON outputs via schema-aware decoding (no regex, no parser retries, no malformed output) and on-prem deployment, it hits the sweet spot for regulated workflows where determinism and compliance matter more than the last 15% of accuracy.
Some well-known names catastrophically fail.
Grok-4 (0.255) is strong on flat OCR but unable to follow schema instructions. Sonar Pro (0.134) consistently outputs search-style responses instead of JSON. PaddleOCR-VL failed to emit any parseable JSON on 50/100 documents. These aren’t small gaps. For production workflows, these models are unusable regardless of other capabilities.
Cost vs accuracy
JSL Vision Structured-8B beats Claude Sonnet 4.5 (0.709) outright. Only four models beat it: GPT-5.2, Gemini Flash, Gemini Pro, and Claude Opus. Cost tells the rest of the story:
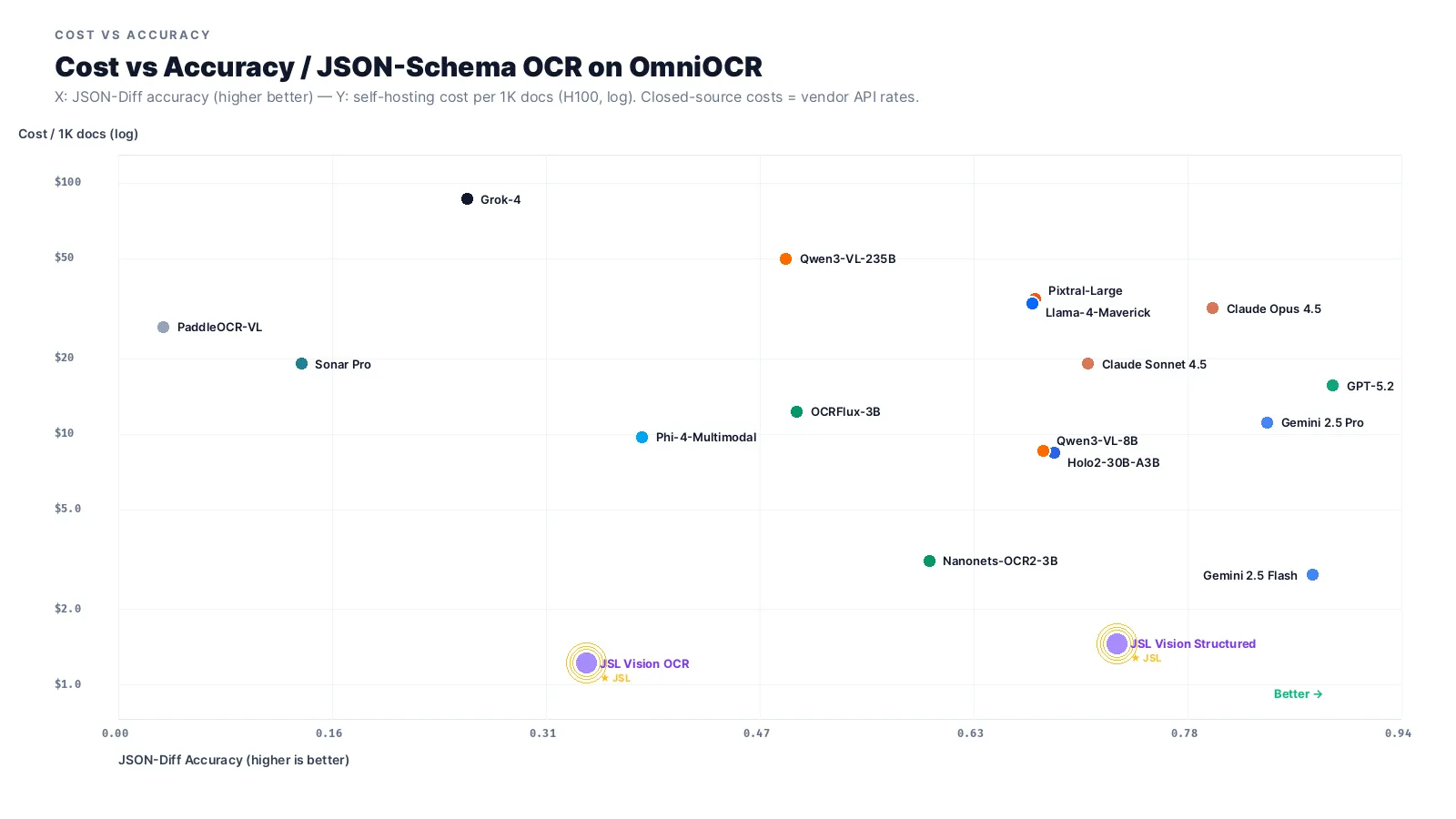
GPT-5.2 at 0.888 accuracy costs ~$15.58 per 1K docs. Gemini 2.5 Flash gets you 0.873 at ~$2.75 per 1K docs, the most accuracy-per-dollar of any model in the benchmark. JSL Vision Structured-8B lands at 0.730 accuracy and ~$6.76 per 1K docs on H100 (or ~$1.50/1K on A10G). JSL Vision-30B lands at 0.689 and $6.76 per 1K docs (single H100), with the additional guarantee that 100% of outputs are valid JSON via schema-aware decoding.
Grok-4 at $86.70 per 1K docs and 0.255 accuracy is the worst quadrant on the schema task: expensive and unreliable. Sonar Pro is similar.
How long does JSON extraction take?
JSON outputs are longer than flat OCR, so durations are higher across the board:
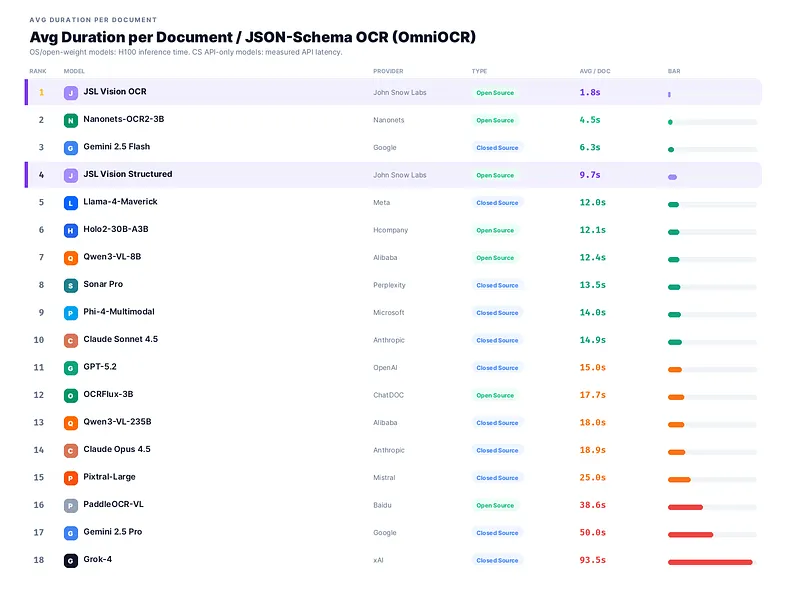
JSL Vision at 9.7s per doc lands in the fast half of the leaderboard (JSL Vision Structured is faster at ~3–4s on an A10G). Gemini 2.5 Pro takes 50s per doc, 5× slower. Grok-4 at 94s per doc means a 1,000-doc batch takes over 26 hours.
The hidden killer: empty predictions
The leaderboard tells you the average accuracy. It doesn’t tell you what happens when a model silently fails to produce any valid JSON. For every empty prediction, your pipeline needs a fallback, and on most production stacks, “no fallback” means “service crash.”
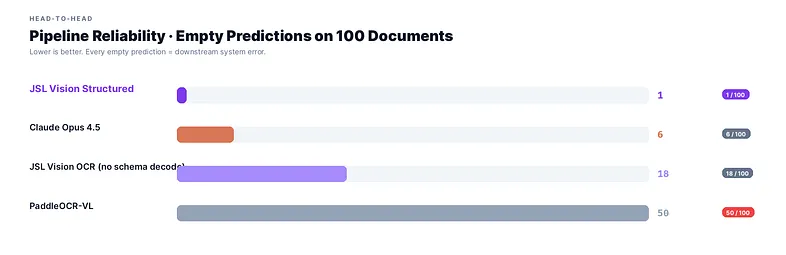
JSL Vision guarantees valid JSON. Schema-aware decoding (xgrammar) makes schema-breakage structurally impossible, the model is mathematically prevented from emitting tokens that would invalidate the schema. No post-processing. No regex repair. No silent failures. 0 empty predictions out of 100.
Every other model in this benchmark, including the leaders, has a non-zero failure mode you have to engineer around.
Why structured generation matters
Every closed-source frontier model in this benchmark was prompted the same way: image + schema + “return only valid JSON.” GPT-5.2, Claude, and Gemini mostly comply. Grok-4 and Sonar Pro mostly don’t.
Open-source VLMs behave similarly by default. But with xgrammar (vLLM) or Outlines, you can bolt schema-aware decoding onto any OS model, the model is mathematically prevented from emitting tokens that would break the schema. The result:
- 100% valid JSON, always
- No regex / LLM post-processing layer
- Deterministic behavior across runs, deployments, and environments
JSL Vision’s structured OCR ships this natively. It’s not a research feature; it’s a production guarantee.
What JSL Vision optimizes for
For regulated enterprise workflows, the optimization function isn’t pure accuracy:
- Schema validity, invalid JSON crashes downstream systems
- Deterministic outputs, same input → same output, always (compliance + audit)
- On-prem deployment, data never leaves your infrastructure (HIPAA / GDPR / SOC 2)
- Single-GPU inference, no distributed infrastructure
- Predictable cost, ~$1.50 per 1K documents on A10G (or ~$6.76 on H100 for the 30B model)
Most closed-source APIs cost 2–13× more per document (GPT-5.2 at ~$15.58/1K, Claude Opus at ~$31.75/1K, Grok-4 at $86.70/1K) and require data-sharing agreements with an external vendor. Gemini 2.5 Flash (~$2.75/1K) is the one exception on cost, but not on deployment model. For regulated industries, the ability to run entirely on-prem, with no data leaving your infrastructure, matters more than the cost differential.
How we ran the benchmark
- Dataset: getomni-ai/ocr-benchmark, 100-document test split
- Metric: json-diff accuracy (deep-sorted keys, case-insensitive values), reference Python implementation
- Closed-source models: OpenRouter API at
temperature=0,max_tokens=8192, explicit schema in prompt - Open-source models: vLLM v0.17.1 on NVIDIA H100, f16 precision, structured generation where supported
- Preprocessing: strip markdown fences from model output before JSON parsing; attempt fallback extraction from first { to last } if initial parse fails
- Empty predictions: counted separately and included in average as score = 0
All per-document results reproducible, cached JSON outputs archived on the JSL benchmark cluster.
GPU or CPU for JSON extraction?
We benchmarked all major OS OCR models on both H100 GPU and c5.2xlarge CPU (8 vCPUs, float32) to give a complete deployment picture.
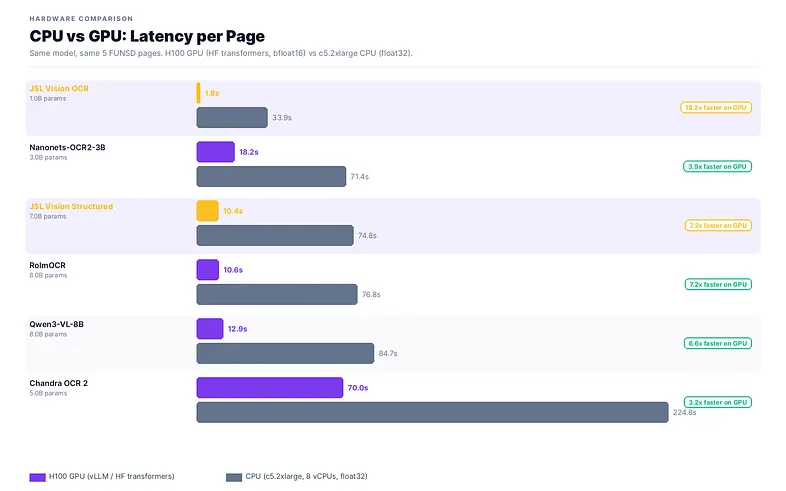
Across model sizes, GPU runs 2–7× faster per page. JSL Vision Structured is 7.2× faster on GPU (10.4s vs 74.8s). JSL Vision OCR via vLLM at 1.76s/page remains the fastest option across the entire benchmark.
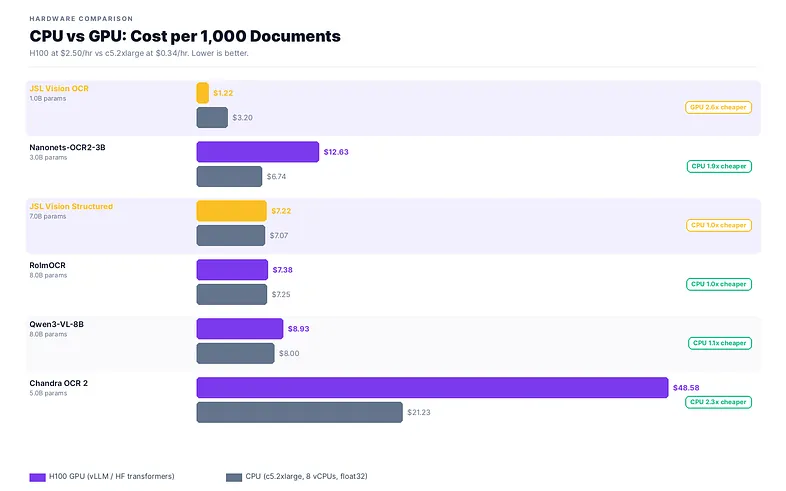
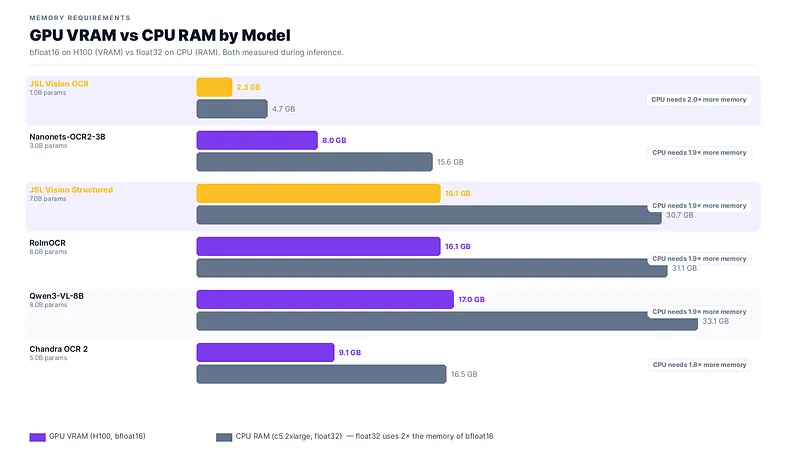
For structured JSON extraction, JSL Vision Structured on CPU costs $7.07/1K docs vs $7.22/1K on H100 (benchmark hardware), within 2% of each other. On an A10G ($1.50/hr), the 8B model delivers ~$1.50/1K with GPU-class latency. If latency matters, use GPU (7.2× faster than CPU). If you’re running overnight batch jobs, CPU saves money and needs no GPU provisioning. Both options deliver #1 on-prem JSON accuracy at 0.730.
Beyond this series
This closes the three-part OCR benchmark series:
- Grounded (BBox) OCR on FUNSD, JSL Vision #1 overall
- Image → Markdown OCR on FUNSD, JSL Vision #1 overall
- Schema-Constrained JSON OCR on OmniOCR, you are here. JSL Vision Structured-8B #1 on-prem at 0.730, beats Claude Sonnet 4.5, within 18% of the frontier
Future benchmarks in the pipeline: medical DEID evaluation on clinical notes, OmniDocBench, OmniMedVQA, and domain-specific fine-tunes.
> In regulated industries, invalid JSON doesn’t fail gracefully. It crashes the pipeline. JSL Vision guarantees structurally valid JSON on every document, on your own hardware, without sending data to an external service.
If schema-constrained extraction is your production bottleneck, Schedule a demo: we’ll show JSL Vision Structured running on your schemas and your documents.




