























































This blog post explores how Natural Language Processing (NLP) and Knowledge Graphs (KG) revolutionize opioid research. By leveraging NLP to analyze vast amounts of unstructured medical data and using Knowledge Graphs to map complex relationships, researchers can gain deeper insights into the opioid crisis. These advanced technologies enable more effective data integration, pattern recognition, and predictive analytics, ultimately contributing to better understanding, prevention, and treatment strategies for opioid addiction.
The opioid crisis is a devastating public health emergency affecting millions of people worldwide. Characterized by widespread misuse of prescription opioids, heroin, and synthetic opioids like fentanyl, the crisis has led to unprecedented rates of addiction, overdose, and death. The complexity and scale of the epidemic demand innovative research approaches to uncover new insights and develop effective interventions.
Using NLP and knowledge graphs have emerged as powerful tools in the battle against the opioid crisis. By harnessing these cutting-edge technologies, researchers can unlock a wealth of information buried within vast repositories of unstructured data, such as scientific literature, clinical notes, medical reports, and social media discussions.
NLP techniques allow for the extraction of structured information from these unstructured sources, enabling the identification of entities like drugs, diseases, and adverse events, as well as the relationships between them. This capability is particularly valuable in the context of opioid research, where understanding the complex relationships between various factors is crucial.
Knowledge graphs, on the other hand, provide a powerful framework for integrating and representing diverse data types, including the structured information extracted through NLP. By modeling the intricate relationships between entities, knowledge graphs enable researchers to perform advanced querying, reasoning, and knowledge discovery, unveiling insights that might remain hidden in siloed datasets.
Neo4j is used to analyze the connected data in ways not possible without graphs. Neo4j is a native graph database specifically designed to store and process connected data, which helps solve complicated life sciences problems at every scale.
The combination of NLP and knowledge graphs holds the promise of revolutionizing opioid research by facilitating a comprehensive understanding of the multifaceted factors contributing to addiction, identifying potential risk factors, and ultimately informing the development of more effective prevention and treatment strategies.
This post covers using pretrained models in the Healthcare NLP library from John Snow Labs to extract entities related to opioids and their adverse effects and then building knowledge graphs by using Neo4J that represents complex relationships between opioid drugs, symptoms, and research publications. By representing entities like opioid drugs, associated conditions (effects), and related PubMed publications as nodes, and their relationships as edges, Neo4j can uncover insights into the adverse effects of opioids, and the PubMed articles those drugs and conditions are mentioned. Overall, Neo4j’s capability to handle highly connected data makes it a valuable tool for various healthcare use cases, from knowledge management to operational analytics and decision support.
Let us start with a short Spark NLP introduction and then discuss the details of opioid drugs analysis with some solid results.
Spark NLP & LLM
The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. This library provides over 2,200 pre-trained models and pipelines tailored for medical data, enabling accurate information extraction, NER for clinical and medical concepts, and text analysis capabilities. Regularly updated and built with cutting-edge algorithms, the Healthcare library aims to streamline information processing and empower healthcare professionals with deeper insights from unstructured medical data sources, such as electronic health records, clinical notes, and biomedical literature.
John Snow Labs’ GitHub repository serves as a collaborative platform where users can access open-source resources, including code samples, tutorials, and projects, to further enhance their understanding and utilization of Spark NLP and related tools.
John Snow Labs also offers periodic certification training to help users gain expertise in utilizing the Healthcare Library and other components of their NLP platform.
John Snow Labs’ demo page provides a user-friendly interface for exploring the capabilities of the library, allowing users to interactively test and visualize various functionalities and models, facilitating a deeper understanding of how these tools can be applied to real-world scenarios in healthcare and other domains.
Reason for Opioid Research
The opioid epidemic has been a devastating public health crisis, claiming countless lives and causing immeasurable suffering. As the fight against this crisis intensifies, researchers and healthcare professionals are exploring innovative approaches to gain deeper insights and develop more effective strategies to combat opioid addiction and its far-reaching consequences.
The graph below (produced by the National Institutes of Health (NIH)) paints a grim picture, with the total number of deaths sharply rising from relatively low levels in the late 1990s to an alarming peak of over 81,000 deaths in 2022. The graph’s distinct lines for males and females reveal the disproportionate impact on the male population, although both genders have experienced a substantial increase in opioid-related fatalities over the years.
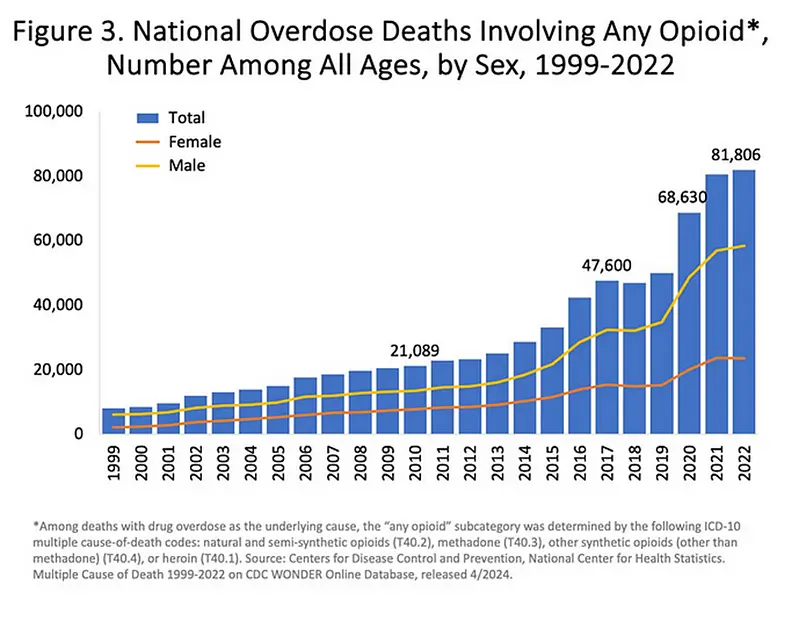
https://nida.nih.gov/research-topics/trends-statistics/overdose-death-rates
Extracting Oncology-Related Entities from Clinical Notes
The extraction of opioid-related information from unstructured text data using Named Entity Recognition (NER) models or Large Language Models (LLMs) is the critical step in the analysis. Unstructured data sources, such as electronic health records (EHRs), clinical notes, and medical literature, hold extensive amounts of valuable information but present significant challenges due to their lack of structured format. NER models are specifically trained to address these challenges by identifying and classifying entities within the text into predefined categories (labeling).
In the context of opioid research, NER models are trained to recognize and extract entities related to opioid drugs, such as specific medication names (e.g., oxycodone, fentanyl), patient symptoms associated with opioid use (e.g., respiratory depression, constipation), and other critical medical terms (e.g., diagnoses, treatments, comorbidities). Advanced NER models, especially those based on deep learning techniques and LLMs utilize sophisticated algorithms to understand the context and semantics of the text, significantly improving the accuracy of entity recognition.
Using Relation Extraction for establishing relationships between named entities efficiently handles large volumes of unstructured text data, converting it into structured information with recognized entities and their relationships.
After the successful extraction of relevant opioid-related entities from unstructured data, the next crucial step is to establish relationships between these entities. This is where Knowledge Graphs come into play. Knowledge Graphs organize the extracted data into a structured format, mapping out the relationships between different entities in a network-like structure. For example, a Knowledge Graph can link a specific opioid medication to its potential side effects, correlate patient symptoms to particular opioid prescriptions, and highlight interactions between opioids and other drugs the patient may be taking.
The process starts with the NER model extracting entities from text data. For instance, from a clinical note stating, “The patient was prescribed oxycodone for chronic pain but developed severe constipation and respiratory depression,” the NER model would identify “oxycodone,” “chronic pain,” “constipation,” and “respiratory depression” as entities. Subsequently, the Knowledge Graph would establish relationships such as caused_by between “alfentanil” and “neonatal respiratory distress” and caused_by between “oxycodone” and “constipation” and “respiratory depression.”
This integrated approach not only enhances data analysis but also facilitates a comprehensive understanding of the complex interdependencies in opioid research. By leveraging NER models for entity extraction plus the relation extraction for establishing the relations between the entities (nodes), and then using Knowledge Graphs for relationship mapping, researchers can uncover hidden patterns, predict potential health outcomes, and develop targeted interventions. This methodology represents a significant advancement in addressing the opioid crisis, providing deeper insights and more effective strategies for prevention, treatment, and policy-making in the realm of opioid use and its associated impacts.
Information Extraction from Text
The ability to quickly visualize the entities generated using the Healthcare NLP library’s NER models is a very useful feature for examining the generated results. Spark NLP Display is an open-source Python library for visualizing the extracted and labeled entities generated with Spark NLP. NerVisualizer highlights the extracted named entities and also displays their labels as decorations on top of the analyzed text.
In the example below, the model (ner_opioid), specifically trained for extracting entities related to opioids, identified two opioid medications: Oxycodone, prescribed for chronic pain, and Fentanyl patch, used for breakthrough pain. The visualizer labelled non-opioid medications: Metformin for diabetes management and Lisinopril for hypertension. Medications were clearly categorized medications by type (OPIOID_DRUG and OTHER_DRUG) Also, the intended uses or associated conditions (GENERAL_SYMPTOMS, OTHER_DISEASE) were also extracted and labeled.
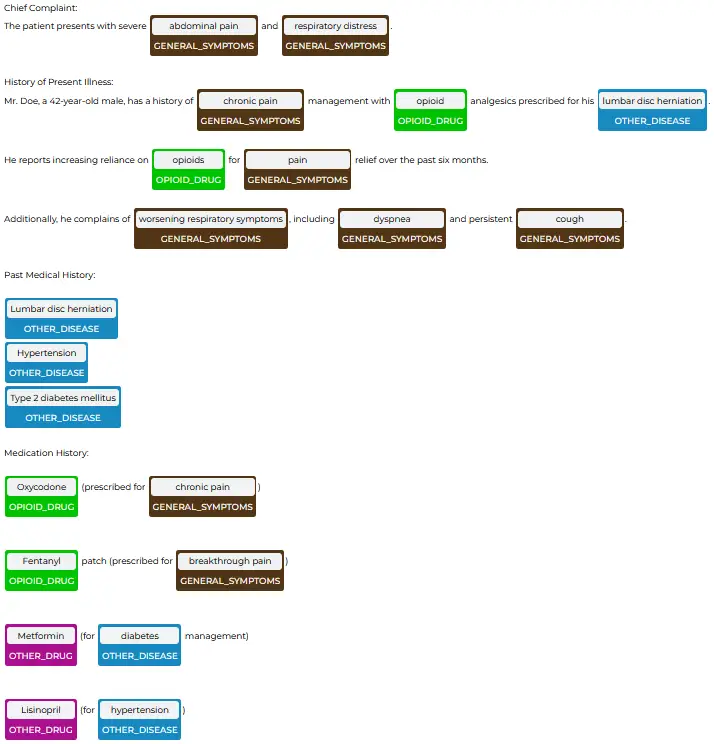
The Relation Extraction Visualizer provides a comprehensive overview of a (hypothetical) 42-year-old male patient’s medical history and current condition as an example, with a focus on opioid use. It highlights the patient’s chief complaints of chronic and breakthrough pain, linking these to his chronic pain management with opioid analgesics. The diagram details the patient’s past medical history, including hypertension and type 2 diabetes mellitus, and outlines his current medication regimen. This visual representation effectively captures the complex relationships between the patient’s symptoms, medical history, and medication use, providing valuable insights into potential opioid-related complications and areas requiring further medical attention.

KG Results
Cypher is Neo4j’s graph query language that lets you retrieve data from the graph and it is similar to SQL for graphs. It is the easiest graph language to learn by far because of its similarity to other languages and intuitiveness.
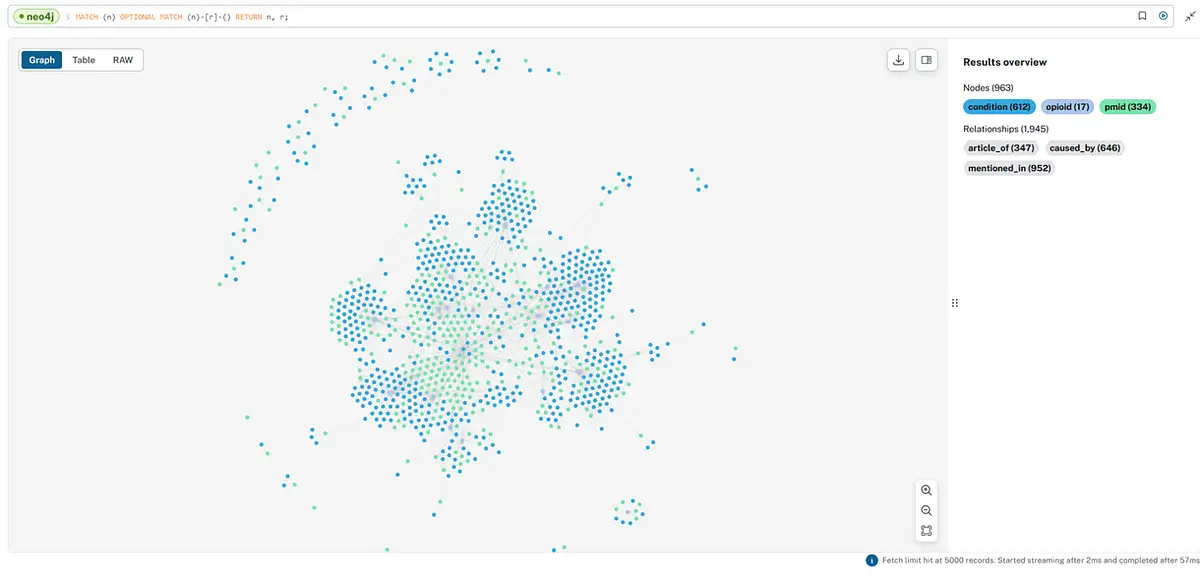
In the following example, the query retrieves all nodes and their relationships, providing a complete picture of all the nodes — opioids, conditions, and PubMed article IDs.
This representation is useful for identifying clusters, outliers, and patterns within the data. Dense areas indicate high connectivity and interaction among nodes, suggesting areas of extensive research or highly referenced topics. Sparse areas or isolated nodes may indicate less researched or niche topics.
Such visualizations are valuable in research for identifying key areas of study, potential gaps in research and the overall structure of data relationships. They aid in understanding the interconnected nature of medical conditions, drug references, and scholarly articles.
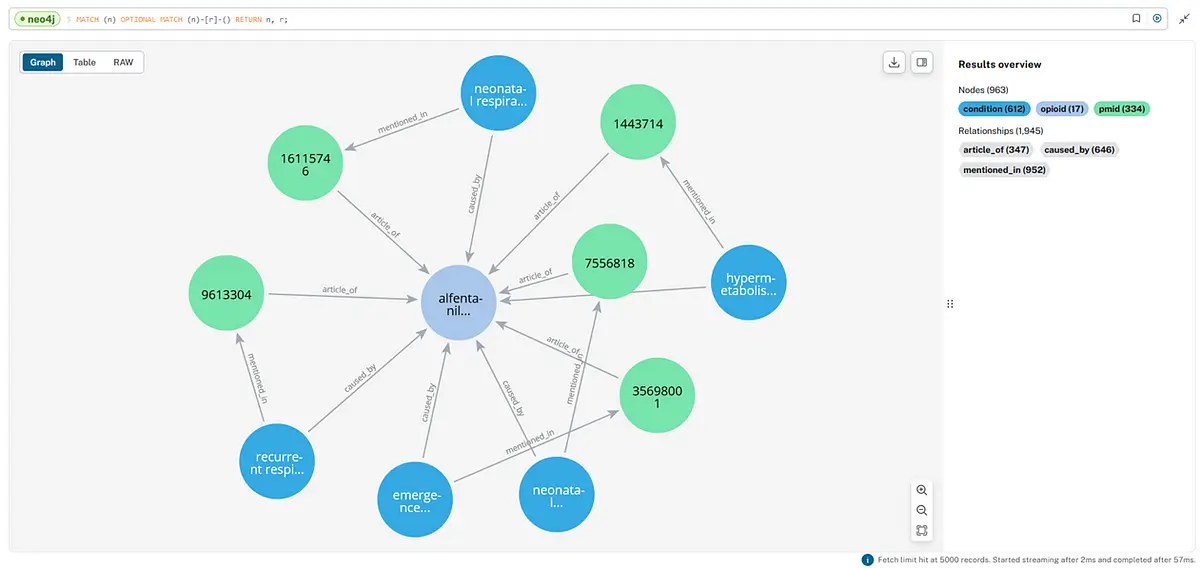
The visualization below offers a more detailed look at the network of nodes and relationships, showing a comprehensive mapping of the data. Alfentanil is a synthetic, short-acting opioid analgesic classified as a small-molecule derivative of fentanyl.
The central node, alfentanil, is connected to various conditions and articles. Relationships like caused_by highlight medical conditions potentially caused by alfentanil.
The dense network of article_of and mentioned_in indicates the extensive research and references available for the entities in this dataset.
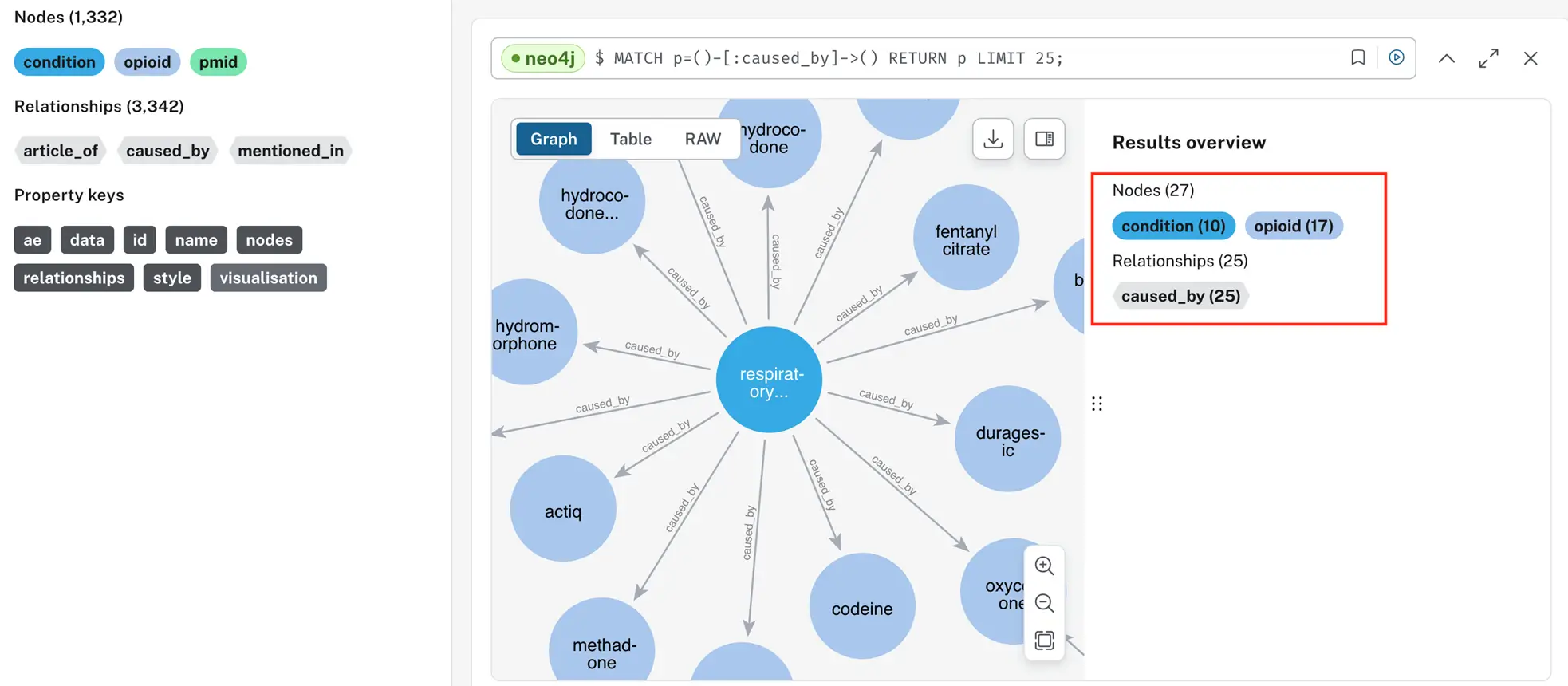
This visualization focuses on the relationships between a respiratory condition and various opioid drugs that may cause or be associated with it.
For example, nodes labeled hydrocodone, fentanyl citrate, Duragesic, codeine, and oxycodone could be opioid analgesics or other substances that potentially cause, exacerbate or are linked to the respiratory condition in some way.
The results overview on the right shows that there are 27 nodes in total, with 10 condition nodes, 17 opioid nodes, and 25 caused_by relationships.
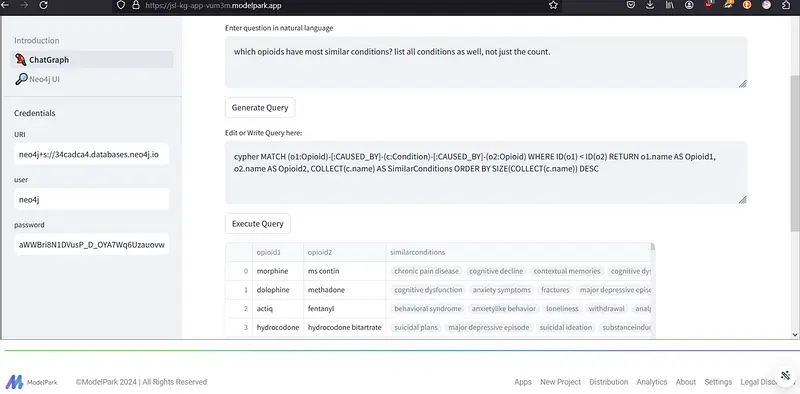
In the example below, a query is run on the database to identify which opioids have the most similar conditions.
The query returns pairs of opioids with their shared conditions. For example, Morphine and MS Contin share conditions like chronic pain disease and cognitive decline. On the other hand, Dolophine and Methadone share conditions such as cognitive dysfunction and anxiety symptoms.
This approach can guide healthcare professionals in understanding the shared side effects and therapeutic uses. Also, it may be helpful in the prediction of the side effects of drugs based on shared conditions.
Conclusion
In conclusion, the combination of NLP and Knowledge Graphs offers a powerful approach to accelerate and enhance opioid research. By efficiently extracting, organizing, and connecting vast amounts of biomedical information, these technologies enable researchers to:
- Uncover hidden relationships between drugs, side effects, and biological pathways
- Identify potential new targets for pain management
- Predict and mitigate adverse drug interactions
- Analyze patterns in prescription practices and patient outcomes
As the opioid crisis continues to pose significant challenges to public health, leveraging these advanced computational techniques becomes increasingly crucial. They not only streamline the research process but also provide novel insights that may lead to safer and more effective pain management strategies.
The integration of NLP and Knowledge Graphs in opioid research represents a significant step forward in our ability to tackle this complex issue. As these technologies continue to evolve, they promise to play an even greater role in shaping evidence-based policies, developing innovative treatments, and ultimately improving patient care in the field of pain management.
P.S. This study was presented at the Neo4j Health Care & Life Sciences Workshop 2024. The video for the entire Workshop is here.





