A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
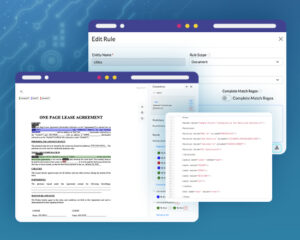
Rule-based annotation, introduced in 2.6.0, with limited options, was improved in this release. The Rule creation UI form was simplified and extended, and helpful tips were added to each field. While creating a rule, the user can define the scope of the rule as being a sentence or document.
- When document is selected, the rule searched for a match on each sentence of a document.
- When sentence is selected, the rule searched for a match on each token of a sentence.
A new toggle parameter Complete Match Regex is added to the rules. Complete Match Regex can be toggled on to preannotate the entity that exactly matches the regex or dictionary value regardless of the Match Scope.
Users can now view the Help Text for all rule fields by hovering over the ? icon. This release also adds the validation of fields: Suffix, Prefix, and Exception such that only single tokens are accepted.
When clearing prefixes, suffixes, and exceptions from the input field, the operation was not saved. In this version, these fields can be cleared to EMPTY and saved. Also case-sensitive is always true (and hence the toggle is hidden in this case) for REGEX while the case-sensitive toggle for dictionary can be toggled on or off.
Users can now download the uploaded dictionary of an existing rule. To download the CSV, users need to go to Models Hub > Available Rules, click on the edit button of the required rule, and then click download.

In the previous release, if a dictionary-based rule was defined with an invalid CSV file, the preannotation server would crash and would only recover when the rule was removed from the configuration. This issue has been fixed. Also, it is possible to upload both vertical and horizontal CSV which can consist of multi-token dictionary values.
Horizontal CSV for Disease Rule:
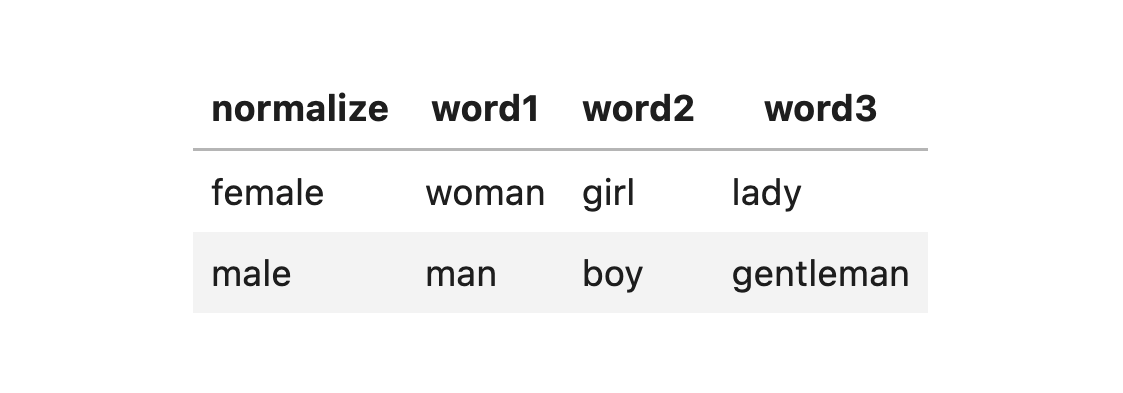
Vertical CSV for Disease Rule:

Note: The first value in the CSV should be the same as the name of the rule.
For further details about ContextualParser which drives the Rule-based annotation please refer to this article.

Get & Install It HERE.
Full Feature Set HERE.