






















































Spark NLP is a Python library that integrates transformer-based models, such as BERT, RoBERTa, and GPT, for efficient and accurate Named Entity Recognition (NER). By using Spark NLP, you can easily implement NER tasks by leveraging the power of transformer-based models. Simply install Spark NLP, choose the desired transformer-based annotator, build a pipeline, and fit it to your text data. With transformer-based NER models, Spark NLP enables you to achieve exceptional NER results while optimizing NLP efficiency.

Introduction
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that involves identifying and classifying named entities within a text. These entities can include names of people, organizations, locations, dates, and more. Traditional NER models often struggle with the complexity and variability of human language. However, recent advancements in transformer-based models have significantly improved NER performance. In this article, we will explore how to leverage the power of transformer-based models using the Python library Spark NLP for efficient and accurate Named Entity Recognition.
Spark NLP is an open-source Python library that brings the power of Natural Language Processing (NLP) to the Apache Spark ecosystem. Built on top of Apache Spark, Spark NLP provides a high-level API that simplifies the implementation of NLP tasks, such as text preprocessing, sentiment analysis, named entity recognition, and more. With its seamless integration with Spark, Spark NLP enables scalable and distributed processing of large-scale NLP pipelines, making it a valuable tool for both research and production environments. By leveraging the latest advancements in NLP, Spark NLP empowers data scientists and NLP practitioners to unlock valuable insights from textual data efficiently and effectively. For more information on the library, check the following references:
- GitHub repository
- Workshop Repositorywith example notebooks
- Official documentation page
Understanding Spark NLP and Transformer-based Models
Spark NLP is an open-source library that provides a high-level API for NLP tasks, including Named Entity Recognition. It integrates seamlessly with Apache Spark and leverages state-of-the-art transformer-based models to achieve excellent NER results.
Transformer-based models, such as BERT, RoBERTa, and GPT, have revolutionized the field of NLP by capturing contextual information effectively. They use self-attention mechanisms to consider the entire input sequence simultaneously, resulting in superior understanding of the context surrounding each word. Spark NLP allows you to utilize different transformer-based models, each with its own annotator, providing flexibility in choosing the most suitable model for your NER tasks, with the capability to process your data at scale using spark.
Performing Named Entity Recognition with Spark NLP
The following steps outline the process of performing NER using Spark NLP:
- Import the necessary libraries and start a Spark session:
# pip install sparknlp import sparknlp from sparknlp.annotator import * from sparknlp.common import * from sparknlp.base import * spark = sparknlp.start()
2. Load the text data into a Spark DataFrame:
data = [("1", "Apple Inc. is planning to open a new store in London."),
("2", "John Doe is a senior data scientist at XYZ Corp.")]
df = spark.createDataFrame(data, ["id", "text"])
3. Initialize the Spark NLP annotators:
To process named entity recognition using a transformers-based annotator in Spark NLP, all we need to add in the pipeline are the texts as annotation objects, which can be done using the DocumentAssembler annotator, and the tokenization stage that splits the texts into tokens (usually words). With these annotations, we can use one of the transformers-based annotators to detect the entities:
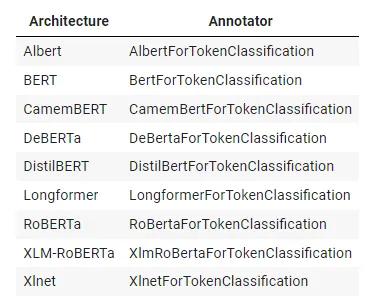
Available architectures and the corresponding annotator in Spark NLP
For example, let’s use the BERT architecture in the pipeline:
document_assembler = (
DocumentAssembler().setInputCol("text").setOutputCol("document")
)
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
ner_model = (
BertForTokenClassification.pretrained("bert_base_token_classifier_conll03", "en")
.setInputCols(["document", "token"])
.setOutputCol("ner")
)
ner_converter = (
NerConverter()
.setInputCols(["document", "token", "ner"])
.setOutputCol("ner_span")
)
The example model is the “bert_base_token_classifier_conll03” for English language, but other pretrained models are available at the NLP Models Hub.
The last stage of the pipeline uses the NerConverter annotator, which transforms the IOB / IOB2 format of the entities into a more user-friendly one, joining the full span/chunk into one entity.
To get a model for inference, we need to fit the pipeline with data. Since this pipeline doesn’t contain any trainable annotator, this step is merely a formality.
model = pipeline.fit(df)
Next, we use the method transform to make predictions:
result = model.transform(df)
The obtained spark DataFrame contains all the stages of the pipeline in the corresponding columns. To visualize the obtained entities, we can manipulate the data frame using the SQL functions from the pyspark library.
import pyspark.sql.functions as F
result.select(
F.explode(
F.arrays_zip(result.ner_span.result, result.ner_span.metadata)).alias(
"cols"
)
).select(F.expr("cols['0']"), F.expr("cols['1'].entity")).show()
Obtaining the following output:
+----------+--------------+ | cols.0|cols.1[entity]| +----------+--------------+ |Apple Inc.| ORG| | London| LOC| | John Doe| PER| | XYZ Corp| ORG| +----------+--------------+
To select other architectures, we only replace the NER stage with the corresponding annotator, also choosing a different pretrained model from the NLP Models Hub.
Conclusion
The use of transformer-based models has revolutionized Named Entity Recognition (NER) in Natural Language Processing (NLP). With the Python library Spark NLP, harnessing the power of transformer-based models for NER tasks has become more accessible and efficient than ever before. By leveraging models like BERT, RoBERTa, and GPT, Spark NLP enables users to capture rich contextual information and achieve exceptional NER performance.
The flexibility provided by Spark NLP’s support for various transformer architectures allows users to choose the most suitable model for their specific NER needs. The simplicity of implementing NER with Spark NLP, using transformer-based annotators, empowers researchers and practitioners to extract named entities accurately and efficiently.
Whether it’s identifying people, organizations, locations, or other entities in text, Spark NLP opens a world of possibilities for maximizing NLP efficiency with transformer-based Named Entity Recognition.




