






















































Robustness in Models
Recent developments in machine learning have revolutionized the field of Natural Language Processing in biomedical domains, healthcare NLP, and general fields, enabling remarkable achievements in both understanding and generating natural language. However, these powerful NLP models also face new difficulties and limitations. One of the key problems in the field is the issue of robustness, which means a model’s ability to handle a variety of textual inputs with consistent and accurate performance, even when they are unusual or unexpected. These inputs can be user errors like typos, wrong capitalization, missing punctuation, or grammatical mistakes, or they can be adversarial attacks like noise injection, word substitution, or paraphrasing that aim to fool or degrade the model.
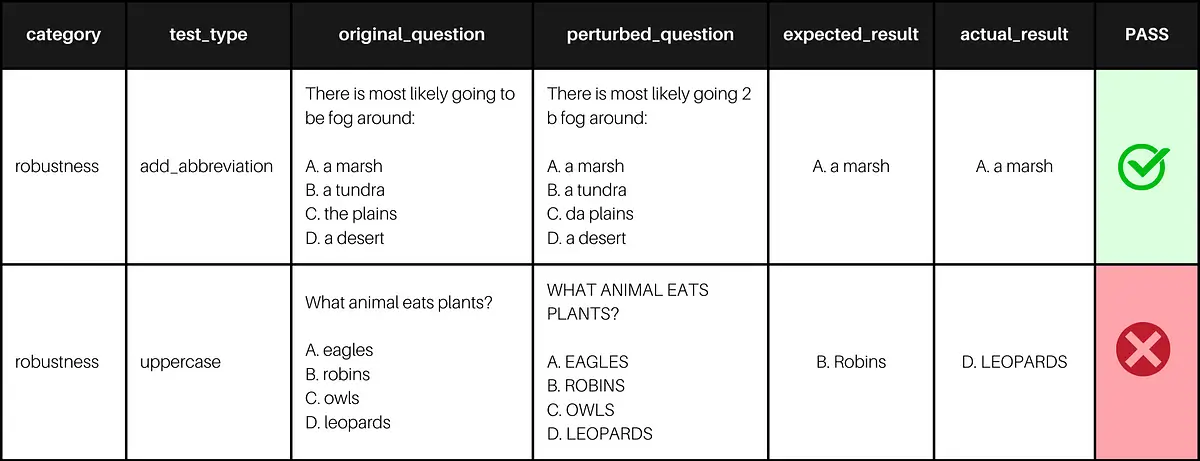
Example testcases and results
LangTest by John Snow Labs
LangTest, an open-source Python library by John Snow Labs, aims to be the saver for testing and augmenting the models for robustness, bias, and other metrics. It supports multiple NLP libraries such as JohnSnowLabs, transformers, and spaCy. It also allows for automatic data augmentation based on test results for select models3, which can improve the model performance and generalization.
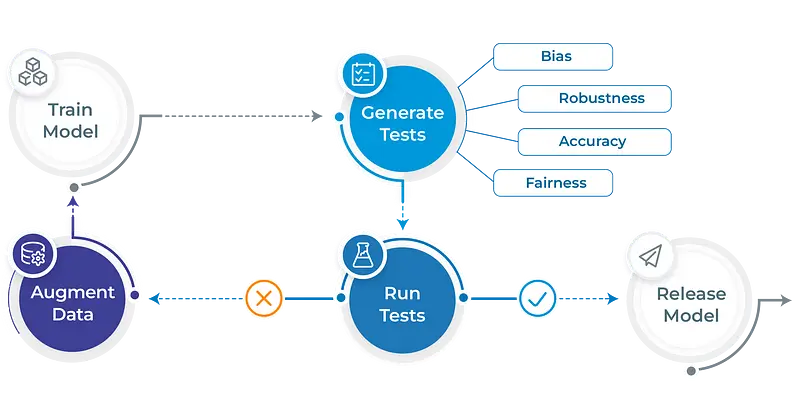
Workflow in LangTest
Testing The Model
LangTest is a flexible and customizable tool that enables you to design your own test suite for natural language models. You can specify which types of robustness and bias tests you want to include, such as typos, capitalization tests, racial or gender-based bias tests, etc. You can also provide your own data sets or use the ones that come with LangTest. You can also select the model you want to test from online hubs like HF and JSL or use your own model. After creating a Harness object with the desired configuration, data, and model, there is a three-step process in LangTest: generate -> run -> report. This will create testcases, run the tests, and display the results in a clear report table. You can then analyze the performance of the model and make specific adjustments or let the LangTest create an enhanced dataset.
Firstly, we use the LangTest 1.9.0 in this blog, and we install and import it the following way.
!pip install langtest==1.9.0 from langtest import Harness
Here is the configuration we will use in this blog post that is also available in the provided notebook you can find at the end:
h = Harness(
task="ner",
model={"model": "./trained_model", "hub": "huggingface"},
data={"data_source" :"sample.conll"}
)
h.configure({
"tests": {
...
}
})
h.generate().run().report()
The report of the test suite is shown in the table below. From this table, we can observe that the model failed to pass more than half of the tests, including some tests that seem to be simple, such as “lowercase.” This indicates that the model is not robust enough to handle different types of inputs and variations. Therefore, this suggests that a proper testing and augmentation process can help improve the performance and quality of your model significantly.
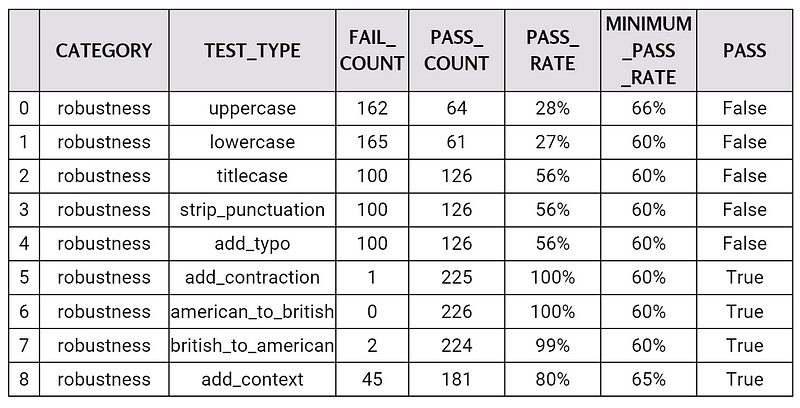
harness.report()
Creating The Augmented Dataset
LangTest provides a powerful and convenient function: .augment(). This function takes an original dataset as input and returns an enhanced dataset that can be used to further fine-tune your model. The enhancement process is based on the test results and the pass_rate’s of the model on different tests. The function generates more samples to improve the performance of the model on the tests that it failed most severely. For example, if the model fails the “typos” test with a low pass_rate, the function will create more samples with typos to help the model learn to handle them better. This way, the function can help you create a more robust and diverse dataset for your model.
The augment function also allows for a custom_proportions parameter overrides the calculated proportions of test types and uses the provided ones. We will continue with LangTest’s own calculation in this blog. Here is the code for creating an augmented dataset:
h.augment(
training_data={"data_source" : "conll03.conll"},
save_data_path="augmented_conll03.conll",
export_mode="add"
)
Testing The Augmented Model
After training the model and saving it. We can use Harness again to create a new test suite with our new model. If we save our previous harness object using .save() then we can load the same configuration to our new model using harness.load(). We can then run the same tests and view the report of our augmented model easily with the same functions as before: generate(), run(), and report().
h_new = Harness.load('saved_harness', model="augmented_model", hub="huggingface")
h_new.generate().run().report()
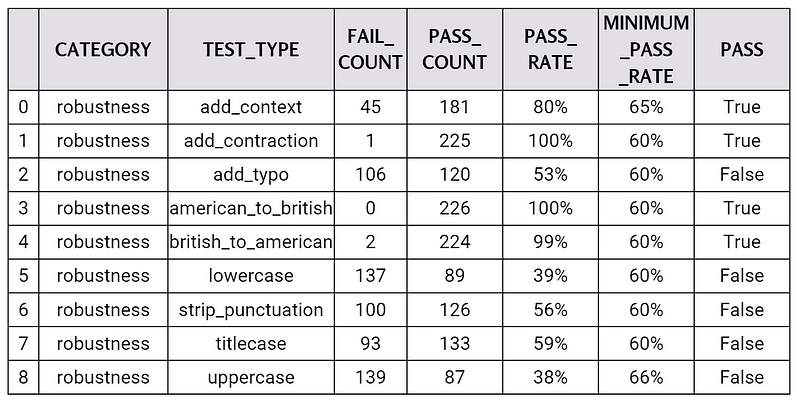
Output of report() function
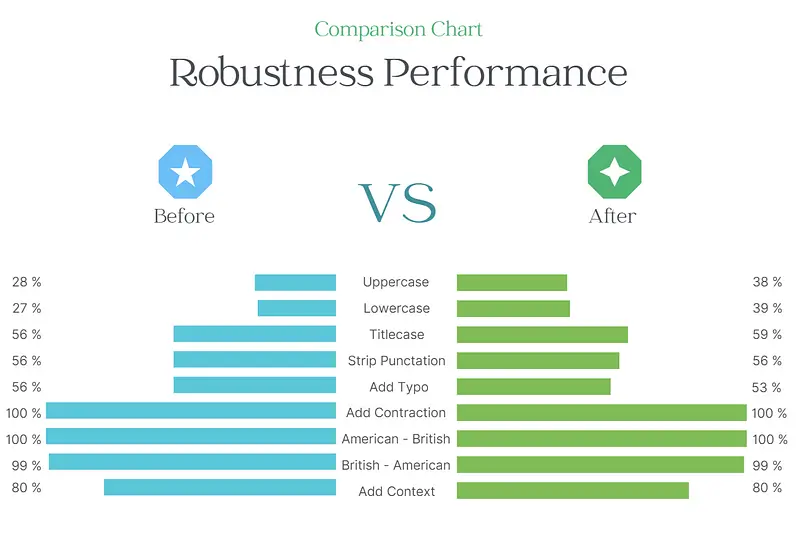
Comparison of reports
Conclusion
In this blog, we showed how LangTest can be used to test and improve the robustness of NLP models on various linguistic challenges. We used a NER model as an example and followed a simple workflow with LangTest. We first created a test suite with LangTest and ran it on our initial model. We then fine-tuned our model with LangTest’s augmented dataset, which contains challenging sentences covering different text input aspects. We finally ran the test suite again on our augmented model and compared the results with the initial model. We found that our augmented model performed significantly better on some of the tests. We focused on the robustness of the model, but you can check the tutorial notebook to see how bias can be evaluated and enhanced in a similar way. In the end, LangTest is a powerful tool that can help you evaluate and enhance your NLP models with ease and confidence. You can try it out yourself by following the instructions in the notebook or visiting the Getting Started page on langtest.org.
Further Reading and Resources
- LangTest docs: langtest.org
- LangTest GitHub: GitHub
- Tutorial Notebook: Colab
- Other Products: Visual NLP, FinTech NLP, Legal NLP




