
























































In the ever-evolving landscape of natural language processing, the prowess of language models in comprehending and responding to myriad queries is undeniably crucial. Today, we embark on a journey into the realm of robustness testing, a pivotal arena where the capabilities of Language Models (LLMs) face rigorous evaluation against the formidable OpenBookQA dataset. As the demand for language models to exhibit linguistic mastery and a nuanced understanding of diverse knowledge domains grows, OpenBookQA emerges as a litmus test, challenging LLMs to navigate the intricate interplay between language and real-world facts.
Dataset Overview
OpenBookQA, authored by Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal, is a significant addition to question-answering datasets. First introduced in 2018 through their paper, “Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering,” presented at the EMNLP conference, this dataset reshapes the landscape of language model evaluation. Comprising 5,957 elementary-level science questions thoughtfully divided into training, development, and test sets, OpenBookQA challenges participants to navigate a small “book” containing 1,326 core science facts. This unique design goes beyond traditional evaluations, demanding a seamless integration of specific and common knowledge. You can find OpenBookQA on Hugging Face, allowing researchers and enthusiasts to explore the intricate interplay of language and knowledge.
How LangTest Utilizing OpenBookQA Dataset?
LangTest helps evaluate LLM models with respect to various benchmark datasets; on top of that, we can apply a wide variety of tests, including robustness, bias, accuracy, and fairness, to ensure the delivery of safe and practical models.
OpenBookQA is one of the benchmark datasets within LangTest and has been meticulously restructured in a jsonl format, forming a critical component in LLM evaluations. Langtest provides two data splits, test and test-tinyf or OpenBookQA Dataset featuring 500 and 50 multiple-choice elementary-level science questions, respectively.
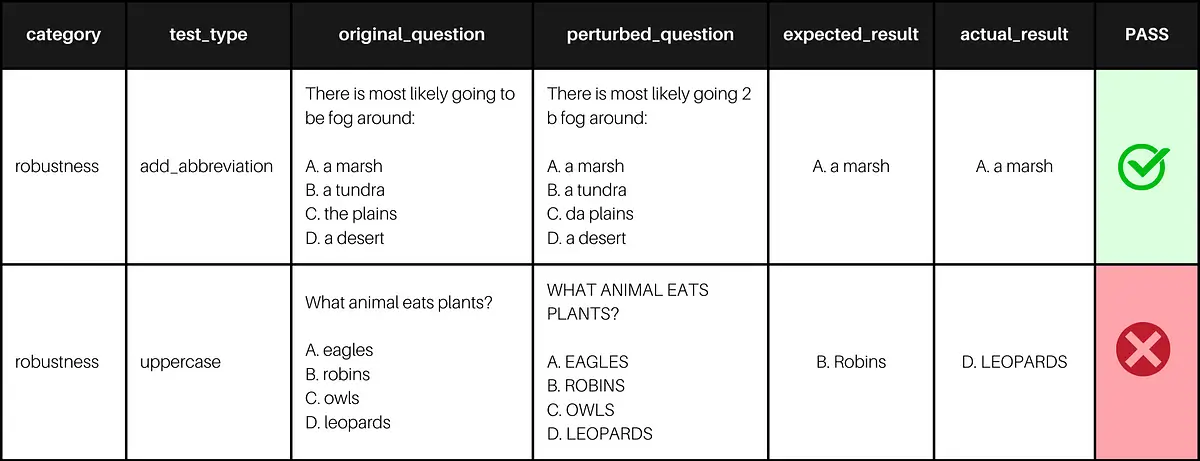
Example of generated results for the text-davinci-003 model from OpenAI on the OpenBookQA dataset
In the evaluation process, we start by fetching original_question from the dataset. The model then generates an expected_result based on this input. We introduce perturbations to the original_question to assess model robustness, resulting in perturbed_question. The model processes these perturbed inputs, producing an actual_result. The comparison between the expected_result and actual_result is conducted using the LLM as Matrix. Alternatively, users can employ metrics like String Distance or Embedding Distance to evaluate the model’s performance in the Question-Answering Task within the robustness category. For an in-depth understanding of how Large Language Models are tested for question-answering using LangTest, refer to this insightful article: Testing the Question Answering Capabilities of Large Language Models.
Robustness Benchmarks for Language Models on OpenBookQA Dataset
In this section, we’ll delve into the performance of various Language Models (LLMs) on the OpenBookQA dataset, focusing specifically on the robustness category. Our objective is to compare the pass rates of these LLMs across a spectrum of robustness tests, shedding light on their ability to navigate real-world challenges.
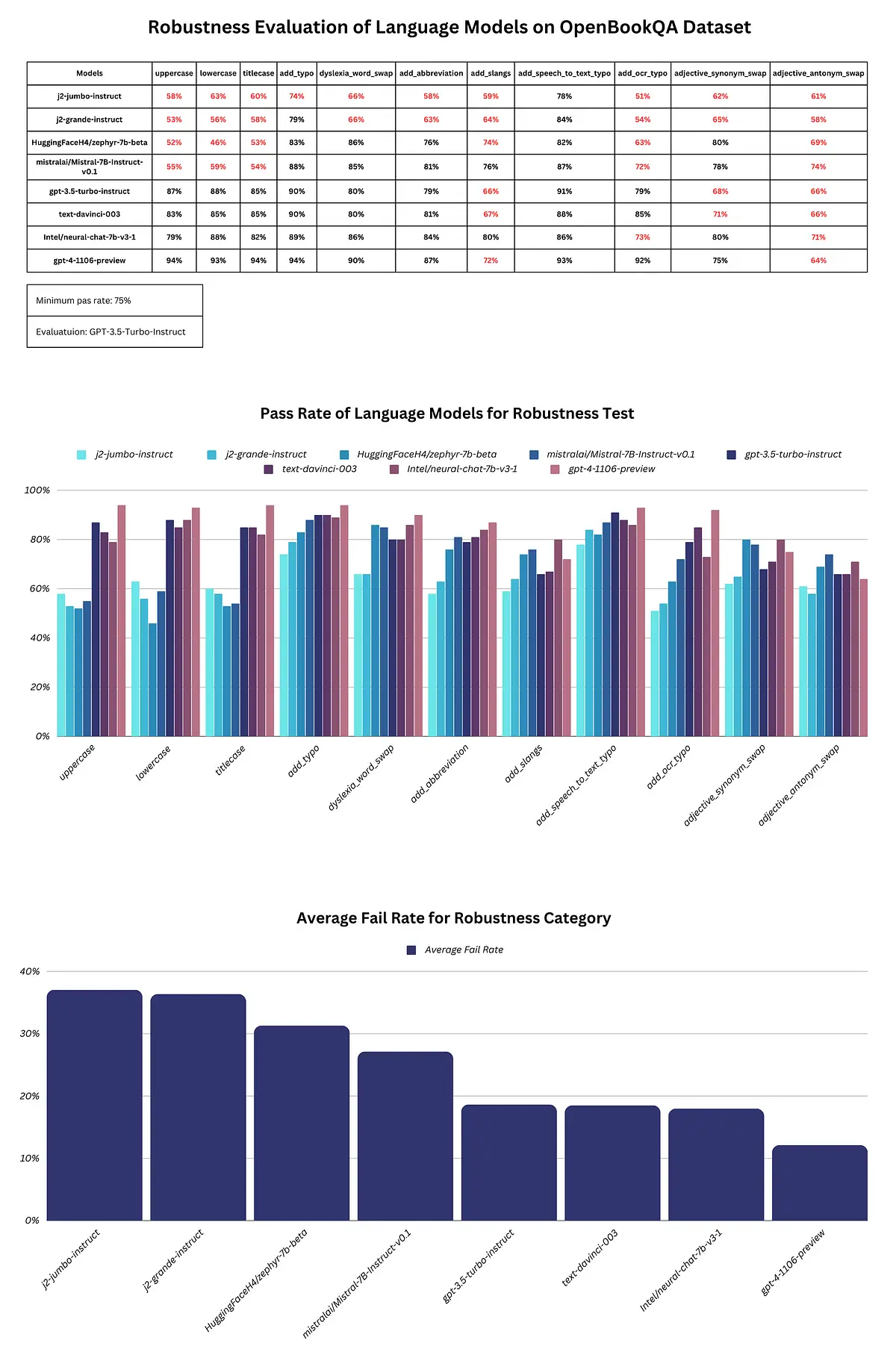
Report
For our evaluation metric, we employ the LLM as Matrix, a two-layer method where the comparison between the expected_result and actual_result is conducted.

evaluation metric
Layer 1: Checking if the expected_result and actual_result are the same by directly comparing them.
actual_results.lower().strip()==expected_results.lower().strip()
However, this approach encounters challenges when weak LLMs fail to provide answers in alignment with the given prompt, leading to inaccuracies.
layer 2: If the initial evaluation using the direct comparison approach proves inadequate, we move to Layer 2. Here, we employ a more robust Language Model (LLM) to evaluate the model’s response.
This two-layered approach ensures a comprehensive evaluation, addressing limitations posed by weaker LLMs and enhancing the accuracy of the assessment.
In this case, we opted for the GPT-3.5-Turbo-Instruct model due to its favorable pricing compared to alternatives such as GPT-4 Turbo and text-davinci-003, recognizing the imperative need to strike a balance between cost and accurate evaluation.
The report highlights significant variations in the performance of language models. Notably, j2-jumbo-instruct and j2-grande-instruct consistently underperformed in various tests, while all models struggled in the adjective_antonym_swap test. On the positive side, gpt-3.5-turbo-instruct, text-davinci-003, Intel/neural-chat-7b-v3–1 and gpt-4–1106-preview showcased competitive performances.
However, mistralai/Mistral-7B-Instruct-v0.1 and HuggingFaceH4/zephyr-7b-beta faced challenges in uppercase, lowercase, titlecase, add_slangs, add_ocr_typo, and adjective_antonym_swap tests. This indicates the need for further improvements to ensure these models can reliably and consistently perform across a diverse range of real-world conditions.
References
- LangTest Homepage: Visit the official LangTest homepage to explore the platform and its features.
- LangTest Documentation: For detailed guidance on how to use LangTest, refer to the LangTest documentation.
- Research Paper — Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
- Benchmark datasets: Benchmark Datasets in LangTest for Testing LLMs.
- Notebook: Access the notebook used in the analysis.




