























































We are happy to announce the Legal NLP 1.8.0 is out!
Legal NLP is a John Snow Lab’s product, launched 2022 to provide state-of-the-art, autoscalable, domain-specific NLP on top of Spark.
With more than 600 models, featuring Deep Learning and Transformer-based architectures, Legal NLP includes:
- Annotators to carry out Name Entity Recognition, Relation Extraction, Assertion Status / Understanding Entities in Context, Data Mapping to external sources, Deidentification, Question Answering, Table Question Answering, Sentiment Analysis, Summarization and much more, both training andinference!
- Zero-shotName Entity Recognition and Relation extraction;
- 600+ pretrained Deep Learning / Transformer-based models;
- Fully integration with Databricks, AWS or Azure;
- 33+ notebooks and 25+ demos ready to showcase its features.
- Full integration with NLP Lab (former Annotation Lab) for managing your annotation projects and train your legal models in a zero-code fashion.
- Compatiblity with Visual NLP, to combine OCR/Visual capabilities, as Signature Extraction, Form Recognition or Table detection, to Legal NLP.
25+ new Legal Language Models in different languages
Including Roberta base and Roberta large for Dutch, English, Irish, Maltese, Latvian, Lithuanian, Polish, Romanian, Greek, Hungarian, Bulgarian, Finnish, Czech, Croatian, Danish, Slovak, Sweedish among others.
New classification models
- legclf_nda_agreements: Binary classifier to detect if a document is an NDA agreement or not.
- legmulticlf_mnda_sections_other: Multilabel model which classifies NDA clauses into different classes, including
otheras a no class as a synonym to[]

- legclf_commercial_lease: Binary classifier which detects if a document is about a Commercial Lease or not.
- 15 binary, paragraph-level, classifiers to detect MNDAclauses as preamble, names of the parties, termination information, disclosure of confidential information, etc.
“legclf_names_of_parties_clauses”, “legclf_applic_law_clauses”, “legclf_preamble_clauses”, “legclf_def_of_conf_info_clauses”, “legclf_assignment_clauses”, “legclf_restricted_use_clauses”, “legclf_dispute_resol_clauses”, “legclf_remedies_clauses”, “legclf_exceptions_clauses”, “legclf_termination_clauses”, “legclf_return_of_conf_info_clauses”, “legclf_non_comp_clauses”, “legclf_non_solic_clauses”, “legclf_permitted_use_clauses”, “legclf_req_discl_clauses”
Improved classification models
- legmulticlf_mnda_sections: Multilabel model which classifies NDA clauses into different classes. Improved with more negative examples for reinforcing
[] or no class
New Large Relation Extraction models
- legre_contract_doc_parties_lg: Relation Extraction model which identifies the names of the parties, the document type and the alias/roles of companies in agreements. Improved with more data.
New T5-based legal summarization model
legsum_proposal:

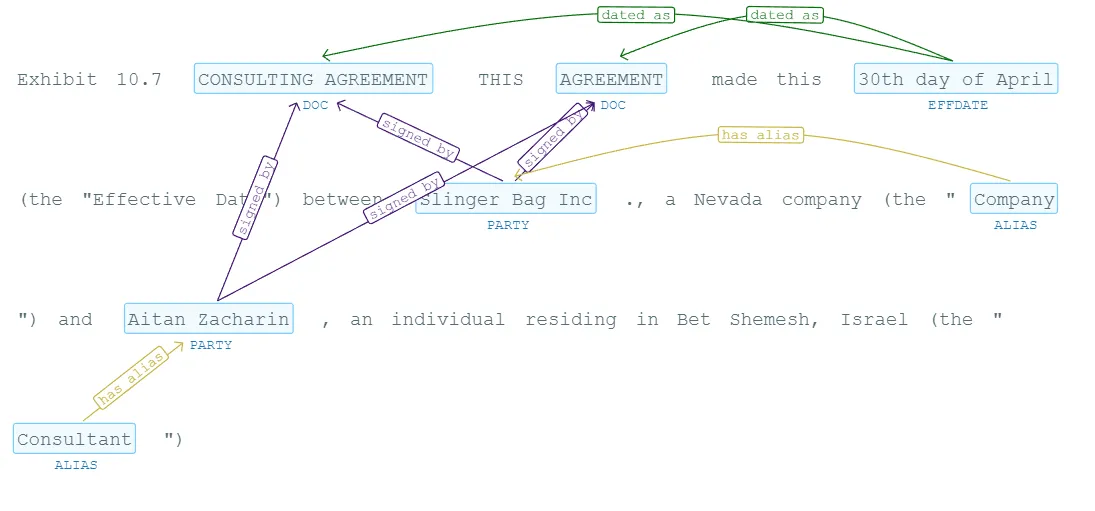
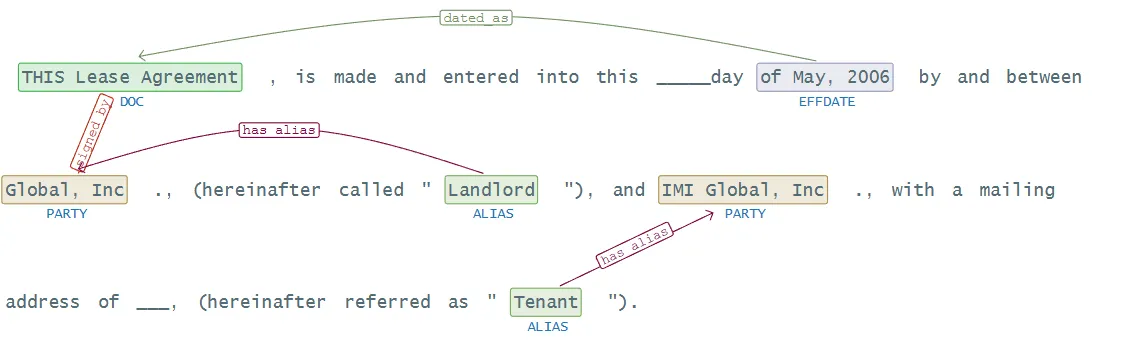
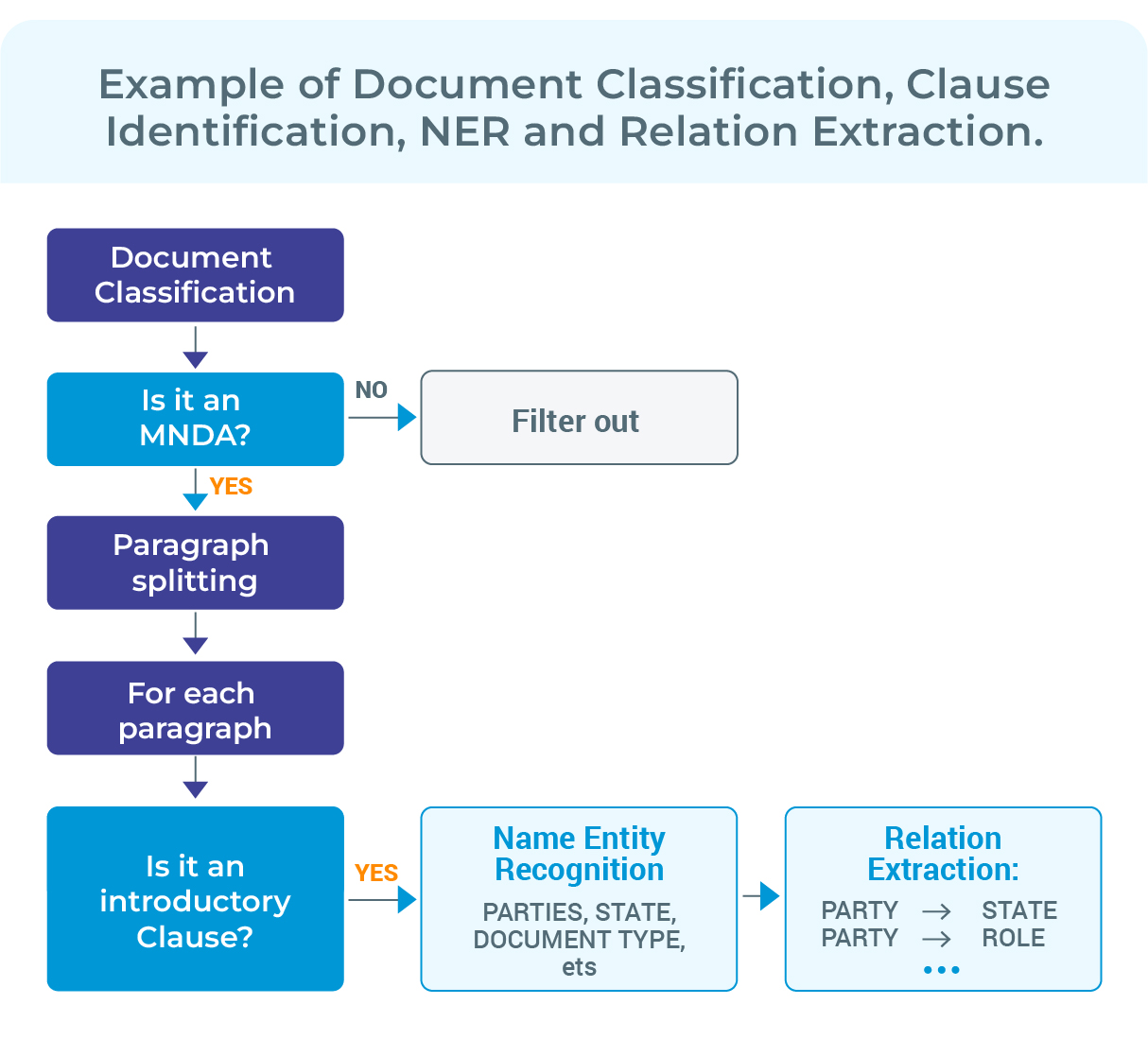
New Pretrained Pipeline with NER and RE for Parties of an Agreement
legpipe_re_contract_doc_parties_alias: We have prepared for you a pretrained pipeline, which includes all the necessary components to do NER and RE from introductory clauses, where a type of agreement is described all along with the effective date, its parties and roles of the parties.
legal_pipeline = nlp.PretrainedPipeline("legpipe_re_contract_doc_parties_alias", "en", "legal/models")
This pipeline consists of 10 components, including a Tokenizer, NER, PoS, Dependency Parsing, Relation Extraction, etc.
The results of applying it to this example text are the following:
New TF2.X Relation Extraction Template
Train Relation Extraction models, using our implementation of Span-Bert paper for TF2.X, with our new Relation Extraction training template.
This template is adapted for natural language processing for legal documents.
Fuzzy Matching in ChunkMappers
We call Chunk Mapping to the ability of mapping NER tags to additional information, available in any data source we may have.
For example, let’s suppose we use an NER model which extracts ORG and we detect Auxilium Pharmaceuticals as NER chunk. We can map that ORG to our SEC Edgar Chunk Mapper to get more information about that company.
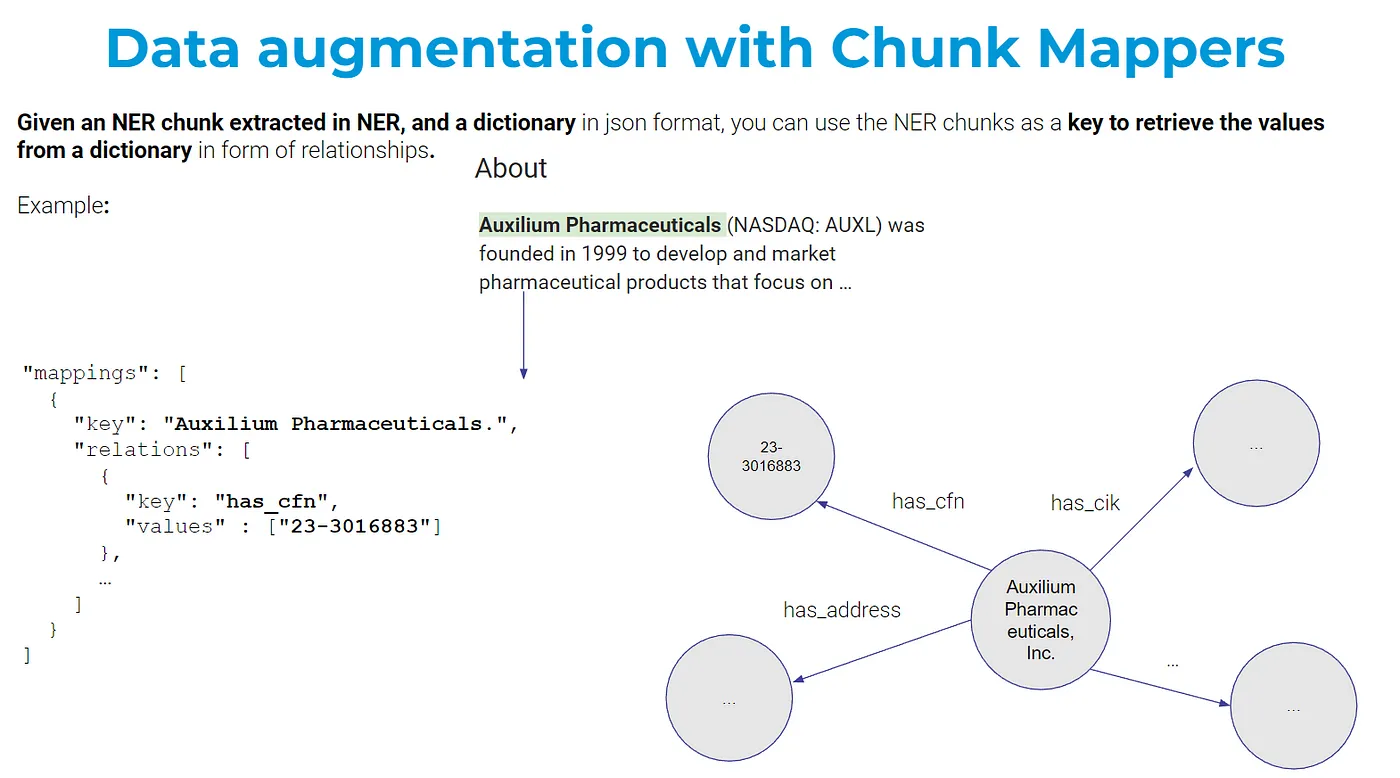
Before, ChunkMapping needed to have an exact match to map to additional sources of information, or use Entity Resolution (conversion / normalization) to do a similarity search and find the closest representation of what we extracted (Auxilium Pharmaceuticals) in Edgar (Auxilium Pharmaceuticals Inc.)
Now, we don’t need to worry about doing Entity Resolution: we offer fuzzyMatch in all of our ChunkMappers. This means: if you extract Auxilium Pharmaceuticals and in Edgar Chunk Mapper you have Auxilium Pharmaceuticals, Inc. you will be able to do the match without any issue.
Models fixed
- legner_orgs_prods_alias: Model to detect Organizations, Products and Aliases on Legal Texts. More data, reduced recall and false positives improving accuracy.
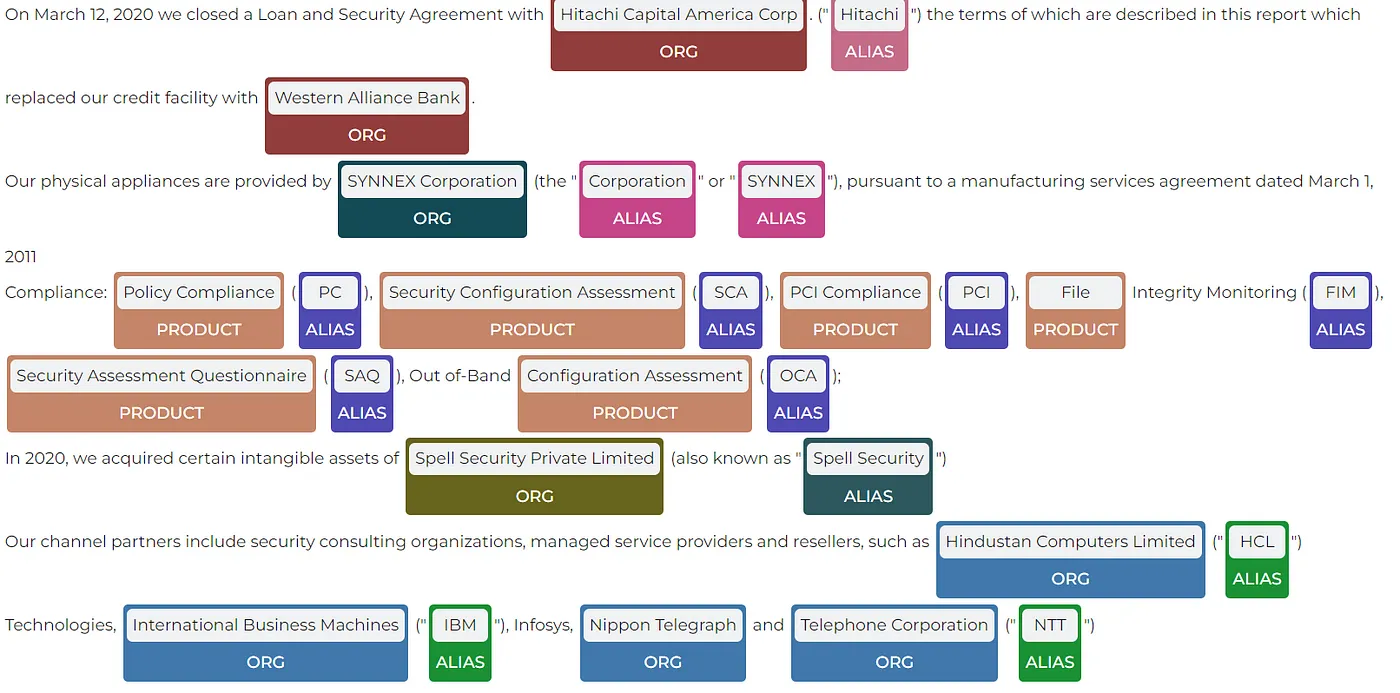
- legner_headers: Model to detect Headers and Subheaders in financial texts. Reduced recall and false positives improving accuracy.
New article
Check our Contract Understanding with Pretrained Pipelines article, to see Classification, NER and Relation Extraction in action using out-of-the-box, ready-to-use pretrained pipelines!
New notebooks folder
Our notebooks folder with examples about most of the features of Legal NLP is now available here.
How to run
Legal NLP is very easy to run on both clusters and driver-only environments using johnsnowlabs library:
!pip install johnsnowlabs
nlp.install(force_browser=True) nlp.start()
Fancy trying?
We’ve got 30-days free licenses for you with technical support from our legal team of technical and SME. Just go to https://www.johnsnowlabs.com/install/ and follow the instructions!




