
























































This post deals with Long-span clause extraction for Legal NLP using Q&A and Automatic Prompt generation. Natural Language Processing has had a very quick adoption in many different business verticals, as Banking, Financial Services, Insurance (BFSI). Other sectors are now experiencing that quick growth on the amount of AI applications under development. Worth to mention is the case of Healthcare, which is experience an AI revolution, specially in NLP (Natural Language Processing), after the creation of Healthcare-specific technologies, as Healthcare NLP. Legal vertical, however, has been historically more conservative on the application of AI. There are several reasons for that.
Challenges for AI in the Legal Vertical
Legal NLP is facing at least three challenges, which are specific to that business vertical:
- First, legal Sector works mainly with human (natural) language.
- Second, legal documents are naturally long, to prevent leaving room for wrong interpretations.
- Third, legal documents are complex to write, read and interpret, as they built on the top of many regulations. All use cases require SME / business experts, but the level of expertise required in legal use cases is above the average.
Fortunately, the situation is starting to change, as we have started to tackle all of those challenges:
- NLP is experiencing a golden age, with a continuous release of Transformer-based Language Architectures, able to capture different domains in Language Models. LegalBert is the best example of it.
- During the last couple years, many different approaches and technologies have come up to solve the problem of the lengthy documents and sentences. Some technologies are well known, as using big transformers (Longformers) able to work with up to 4096 tokens, instead of traditional Bert-based with a restriction of 512.
- Luckily, zero-code platforms as Annotation Lab have allowed legal experts to transfer knowledge to NLP models with a very low effort.
- Finally, with the latest research efforts, novel techniques have been proposed to cope with the original restrictions of, for example, classical NER approach, as Question Answering-based NER, Zero-shot Learning and Automatic Prompt generation. We will discuss them in this article.
With all of these technical advances, with Legal Services and documents being more and more digitalised and the big demand on Legal NLP in other verticals (as BFSI), we will be experience this NLP revolution in Legal soon.
Spark NLP
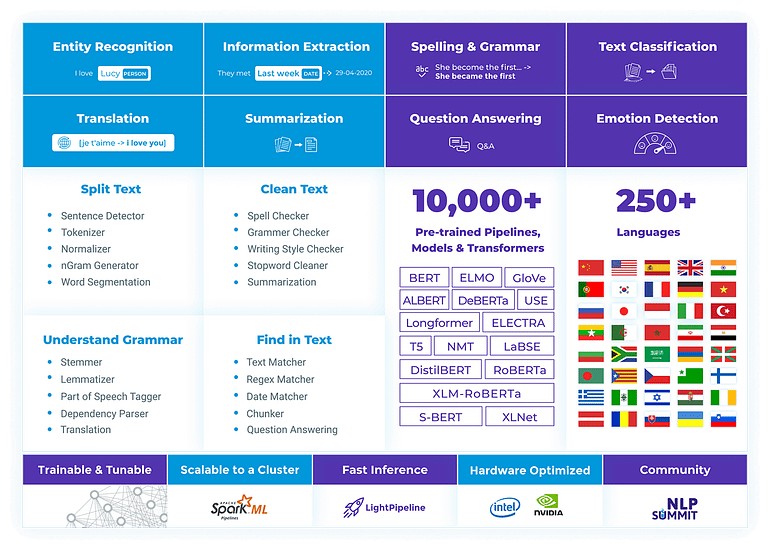
John Snow Labs Spark NLP is the only natively scalable NLP library, since it runs on the top of Spark Clusters. It’s core is Open Source, and it contains several domain-specific libraries to process Clinical, Bio, Healthcare, Finance and Legal domains.
These are some of their capabilities, empowered by the use of State of the Art Transformers and Language models:
- Information Extraction, including Name entity recognition and Pattern Matching;
- Part-of-Speech, Dependency Parsing;
- Binary, Multiclass and Multilabel Text Classification;
- Question & Answering;
- Machine Translation;
- Sentiment Analysis;
- … and even Image Classification with Visual Transformers!
Spark NLP
We have more than 10K pretrained models, available in our Model Hub, you can use out of the box. Demos are available as well showing more than 100 models in action.
Spark NLP for Legal
In John Snow Labs, we are happy to announce Spark NLP for Legal, one or our most recent additions to the Spark NLP ecosystem, and released all along with Spark NLP for Finance, Oct 3rd, 2022.
These licensed libraries work on the top of Spark NLP, which mean they are also scalable to clusters and include State-of-the-Art Transformer Architectures and models to achieve the best performance on Legal documents. 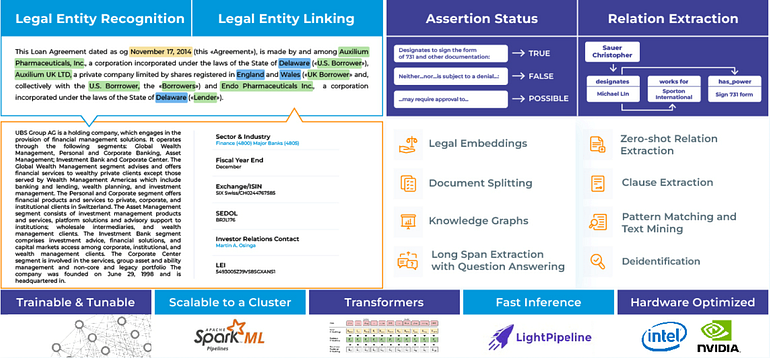
Legal NLP
Spark NLP for Legal, as well as NLP for Finance and Healthcare, is based on 4 main pillars:
- Domain-specific Named Entity Recognition (NER). We will be highlighting in the following sections the main challenge in Legal NER: the extraction of long-span / clause-based entities in legal documents, which traditional NER methods fail to extract.
- Entity-linking, to normalize NER entities and link them to public databases / datasources, as Edgar, Crunchbase and Nasdaq. By doing that, you can augment Company Names, for example, with externally available data about them.
- Assertion Status: to infer temporality (present, past, future), probability (possible) or other conditions in the context of the extracted entities
- Relation Extraction: to infer relations between the extracted entities. For example, the relations of the parties in an agreement.
In addition to that, we include Sentiment Analysis, Deidentification, Zero-shot Learning, Question & Answering and long-span extraction using Question & Answering.
Caveats of traditional NER on long chunks
NER, or Named Entity Recognition, is the NLP task aimed to extract small chunks of information which are relevant in the use case. Any kind of entity can be modeled by NER, as Organizations, People, Roles / Job Titles, Dates, Parties in an Agreement, Document Names, etc. Check a list of Legal NLP models available in Spark NLP for Legal documents.
Let’s consider the following sentence (yes, that’s one sentence in Legal documents!)
This INTELLECTUAL PROPERTY AGREEMENT (this “Agreement”), dated as of December 31, 2018 (the “Effective Date”) is entered into by and between Armstrong Flooring, Inc., a Delaware corporation (“Seller”) and AFI Licensing LLC, a Delaware limited liability company (“Licensing” and together with Seller, “Arizona”) and AHF Holding, Inc. (formerly known as Tarzan HoldCo, Inc.), a Delaware corporation (“Buyer”) and Armstrong Hardwood Flooring Company, a Tennessee corporation (the “Company” and together with Buyer the “Buyer Entities”) (each of Arizona on the one hand and the Buyer Entities on the other hand, a “Party” and collectively, the “Parties”).
Traditional Deep Learning approaches work well to extract entities as the document type (Intellectual Property Agreement), the Parties (Armstrong Flooring, AFI Licensing, AHF Holding…), the Aliases (“Seller”, “Buyer”, “Company”), Effective Date of the contract (December 31, 2018), etc. In Spark NLP for Legal, we have even trained Relation Extraction to group this entities together, as shown in the following figure and in the demo and model card in Spark NLP for Legal (NER, Relation Extraction). 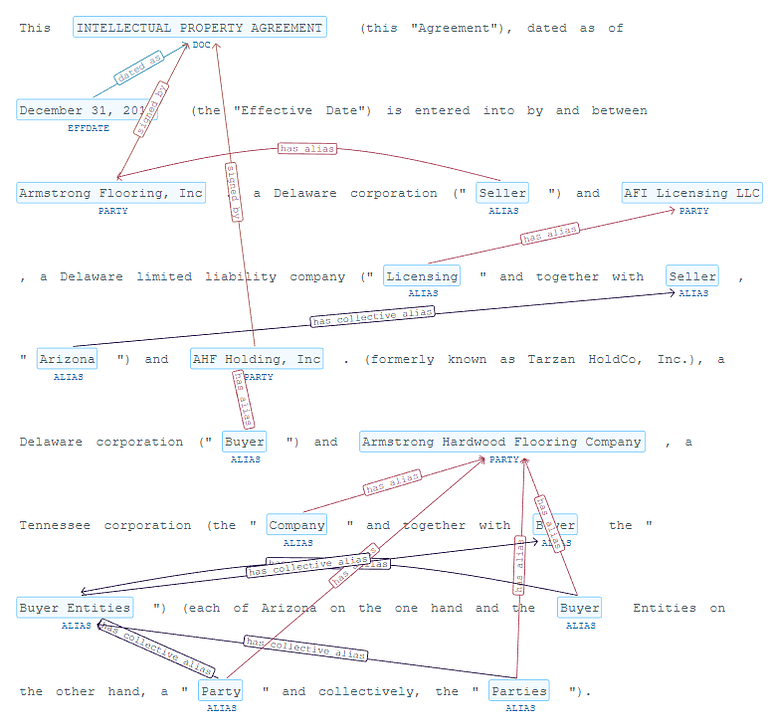
Spark NLP for Legal: NER and RE in agreements
However, traditional NER struggles when the text length of the entities starts to increase. Let’s suppose we have this sentence.
The Company will obtain, record and provide all necessary evidence of the Company’s ownership of the Supplier Assigned IP, including the execution of a Patent Assignment in the form of the attached Exhibit B.
It was clearly three parts:
- The subject (who): The Company
- The action (verb): will obtain, record, and provide
- the object (what): all necessary evidence of the Company’s ownership of the Supplier Assigned IP, including the execution of a Patent Assignment in the form of the attached Exhibit B.
Subject and action could be good candidates for a traditional Deep Learning NER. 
Subject and Action extraction with NER
But, what happens if, what I want to extract, is the object?
…all necessary evidence of the Company’s ownership of the Supplier Assigned IP, including the execution of a Patent Assignment in the form of the attached Exhibit B.
Two ideas may come across your mind, and some caveats.
- Text classification? Good for detecting the whole revelant paragraphs, for example, to carry out paragraph-level identification of clauses. But if you want to detect partial chunks of information in a sentence, then you will struggle.
- NER? Helpful to extract entities with small number of words, as the subject and the action. But it will struggle to extract the object, due to the amount and nature of the tokens.
In Spark NLP for Legal, we overcome this challenge using, instead of Traditional Token Classification Deep Learning approaches, a Question & Answering models and Automatic Question Generation. Sounds cool, isn’t it? Let’s see how this looks like in practice.
Long-span extraction with Question&Answering and Automatic Prompt Generation
Now, here is the trick you were looking for. Question & Answering models are able to find optimal answers to your questions. The only things that you need is:
- A good, domain-specific, question & answering model.
- A restricted context where the answer is present.
- A good prompt, or question.
Well, we have good news for you!
First, in Spark NLP for Legal, we have legal question & answering models which will help us in the task.
Second, you can carry out sentence / paragraph / section splitting using many different Tokenization and Splitting techniques, as described in this notebook. Also, filtering out paragraphs is very simple with our more than 300~ clause classification models. Discard all of those paragraphs which are not relevant for your use case!
Third, prompts. Ok, that’s the most interesting part. Prompt engineering or creation of proper inputs to Language or QA models is usually a manual task, which requires first manually type the questions to retrieve answer from the models. In our example, to retrieve the object, we may need to create the question: What will the Company obtain, record and provide? But it’s evidently impossible to create questions covering any combination of Company names and verbs.
Spark NLP tackles that task for you using Question & Answering models and Automatic Question Generation.
Question & Answering as the basis for information extraction
In Spark NLP, we use Question & Answering not only in the canonical way to answer questions about a text. We also use it to to carry our information extraction, as long-span extraction and Zero-shot NER.

Legal Zero-shot NER using prompts
Question & answering is an NLP task in charge of retrieving usually one answer to a question, giving a context. There are two common forms of question answering:
- Extractive: extract the answer from the given context.
- Abstractive: generate an answer from the context that correctly answers the question.
We already have:
- The whole paragraph we are processing as a context.
- An extractive, Q&A model for legal domain (from Models Hub).
The only thing left is:
- Generating a question.
Coming back to our problem. We needed the big text span in bold:
The Company will obtain, record and provide all necessary evidence of the Company’s ownership of the Supplier Assigned IP, including the execution of a Patent Assignment in the form of the attached Exhibit B.
That big span is the answer to the question: What the Company will obtain, record and provide? If we could create that question on the fly, to ask it to the model, we would retrieve the long span.
As we mentioned before, Company and will obtain, record and provide are small chunks of information you can infer with traditional NER or rule-based approaches. We have an NER model available which does that. You can also use PoS information (Verb) and syntactic dependencies to get the Subject with this pipeline or any other rules. The aim here is to accelerate the extraction of both Subject and Action to create a question.
If you have covered the small Subject and Action chunk extraction with any traditional approach, the only thing you need now is to use an Automatic Question Generator, included in Spark NLP for Legal.
Automatic Question Generation
We use a novel approach to automagically generate questions for querying Question & Answering model. It’s called Automatic Question Generator, and it’s available in Spark NLP for Legal.
There are two possible approaches we can follow:
- A rule-based approach. Consists in creating questions based on a pattern, for example: [WH-PRONOUN] [ACTION] [SUBJECT] [QUESTION MARK]. If we chose what as a wh-pronoun, we get What will obtain, record and provide the Company ? This may not sound like a natural English question, but the semantic is perfectly contained in the question nevertheless.
- A seq2seq question-generation module. Given the Subject and the Action, you can use finetuned models for question generation, as the one available in the Spark NLP repository. Just by providing the concatenation of SUBJECT + ACTION (Company will obtain, record and provide) you will get (What will the Company obtain, record and provide?). The advantage of this approach is that you leave the work to seq2seq models, which are trained on real data, and language sounds more natural. The disadvantage — you have less control on the generated output.
In this article, we will use the first approach — a Rule-base approach, to generate the questions, which will be sent to the Q&A model. This schema is illustrated in the picture below.

Automatic Question Generation and Question & Answering for long span extraction
The Automatic Question Generator, in it’s rule-based approach, includes some customization. You can add any word or words (usually wh-words, like what, when, to whom…), set the order of the entities you want to follow (subject — action or action-subject) or using or not a question mark in the end. For this use case, [WH-PRONOUN] [ACTION] [SUBJECT] [QUESTION MARK] just worked fine.
And that’s it! We came a long way to understand the length limitations of traditional NER, but the approach is simple — don’t use NER models for long chunks. Use Question&Answering and Automatic Question Generation and voilà, Q&A will do long-span extraction for you.
Final Pipeline and Notebook
This is how a complete Spark NLP pipeline would look like: 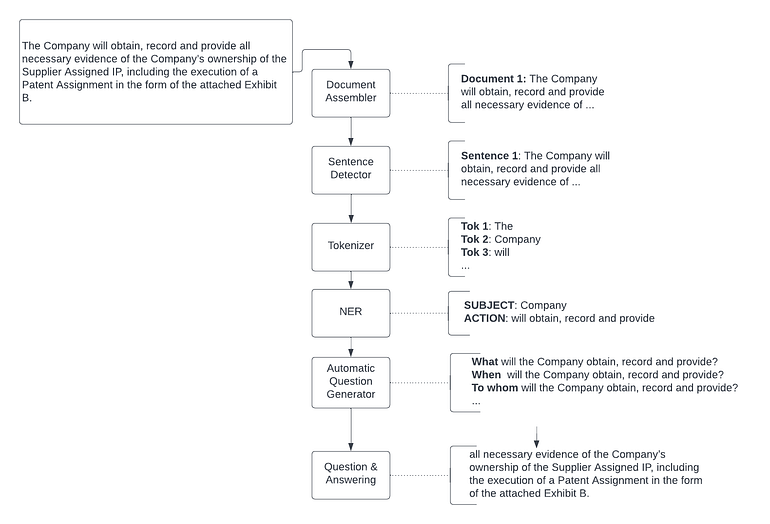
Complete Spark NLP for Legal pipeline
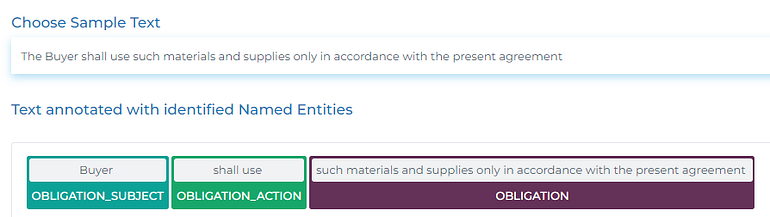
And this is an example of the approach in action with another example, in a Streamlit app.
References
- Spark NLP for Legal notebook
- Models Hub: NER for Subject, Action, Indirect Object (and it also extracts the Object if it’s not too lengthy)
- Models Hub: Legal
- Models Hub: Legal Q&A
- Spark NLP for Legal demos
- Spark NLP for Legal demos: clause extraction



