
























































Visual question answering (VQA), an area that intersects the fields of Deep Learning, Natural Language Processing (NLP) and Computer Vision (CV) is garnering a lot of interest in research circles. A VQA system takes free-form, text-based questions about an input image and presents answers in a natural language format.
Unlike systems producing generic image captions, VQA systems need more detailed understanding of images and complex reasoning abilities to provide accurate and appropriate answers for a growing range of real-world use cases.
NLP is a particularly crucial element of the multi-discipline research problem that is VQA. This is because NLP technology enables the VQA algorithm to not only understand the question posed to it about the input image, but also to generate an answer in a language that the user (asking the question) can easily understand. Such understanding enables the user to derive useful insights from the image for their particular application.
What Kind of Visual Questions Can VQA Systems Answer?
Broadly, the goal of a VQA system is to understand the contents of an input image and present insights in human-understandable language using natural language processing. Moreover, it can potentially solve many kinds of computer vision and visual NLP tasks, which require computers and algorithms that are at least as intelligent as human beings. This is why VQA problems are widely accepted as “AI-complete” or “AI-hard”.
For example, the question “what is in the image?” is an object recognition task, whereas “are there any babies in the picture?” is an object detection task. Both are common VQA problems that lend themselves well to NLP and text-based answers. Similarly, other well-studied problems in NLP that are suitable for VQA are attribute classification tasks, and scene classification tasks. An example of the former is “what color is the bench?”, while “is it raining?” an example of the latter.
Other possible tasks and questions that VQA can answer are:
- Counting: “How many dogs are in the image?”

- Activity recognition: “Is the baby crawling?”
- Spatial relationships among objects: “What is between the bench in the bottom-right corner and the tallest tree with light green leaves?”
- Visual commonsense reasoning (VCR): “Why is the toddler crying?”
- Knowledge-based reasoning: “Is this a vegetarian curry?”





For all these task types, a trained VQA system can answer arbitrary questions about an image by following a systematic four-step process of image featurization, question featurization, joint feature representation, and answer generation. To do this, it reasons about the relationships of objects with each other and the overall scene. After analyzing the image and question, the system builds some kind of query and looks into an available public knowledgebase, also known as a VQA “dataset”, to get the answer and present it in human-readable format using NLP. In general, a reliable VQA system can perform reasoning over the content of an image and solve a broad variety of typical NLP and CV tasks for real-world applications.
What is a Visual Question Answering Dataset?
For visual question answering in Deep Learning using NLP, public datasets play a crucial role. The best datasets include a wide range of possibilities for both questions and images in real-world scenarios. The main function of a dataset is to help train a VQA algorithm so that if it is given an image and a natural language question related to that image, it can produce a correct and natural language answer as the output. The first VQA dataset was DAQUAR, released in 2014. DAQUAR is a small dataset that exclusively contains indoor scenes. After DAQUAR, several other datasets have been released to support different VQA applications.
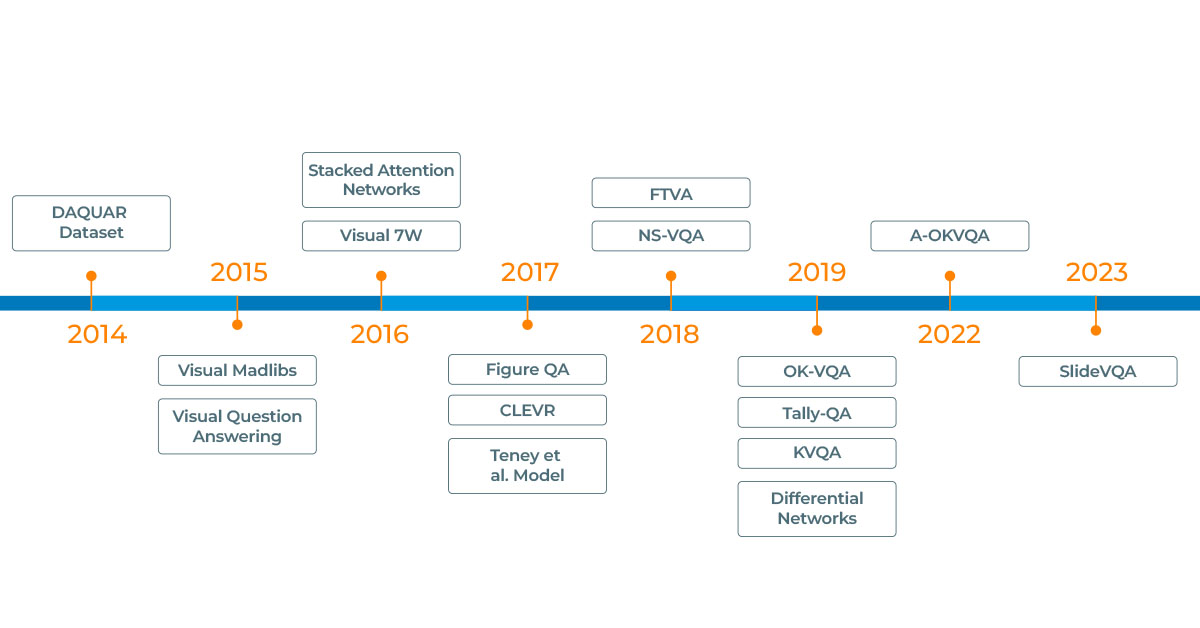
Three of the most popular datasets for VQA applications are:
VQA Dataset
The VQA Dataset contains open-ended questions about images and enables VQA algorithms to answer binary classification questions (“is the umbrella open?”), counting questions (“how many umbrellas are in the room?”), and open-ended questions (“who is carrying an umbrella?”) about an input image.

CLEVR dataset
This diagnostic dataset, published and maintained by Stanford University, contains a training set of 70K images and almost 700K questions, a validation set of 15K images and almost 150K questions, plus a test set of 15K images and almost 15K images. CLEVR can test a range of visual reasoning abilities of an AI system such as attribute identification, counting, comparison, spatial relationships, and logical operations.
 How many objects are circular in shape?
How many objects are circular in shape?What is to the right of the pink ball?
Are there an equal number of spheres and rectangular blocks?
FigureQA dataset
Microsoft’s FigureQA is a visual reasoning dataset of over one million question-answer pairs grounded in over 100K images. It introduces a new visual reasoning task for research, specifically for scientific-style figures like bar graphs, pie charts, and line plots.
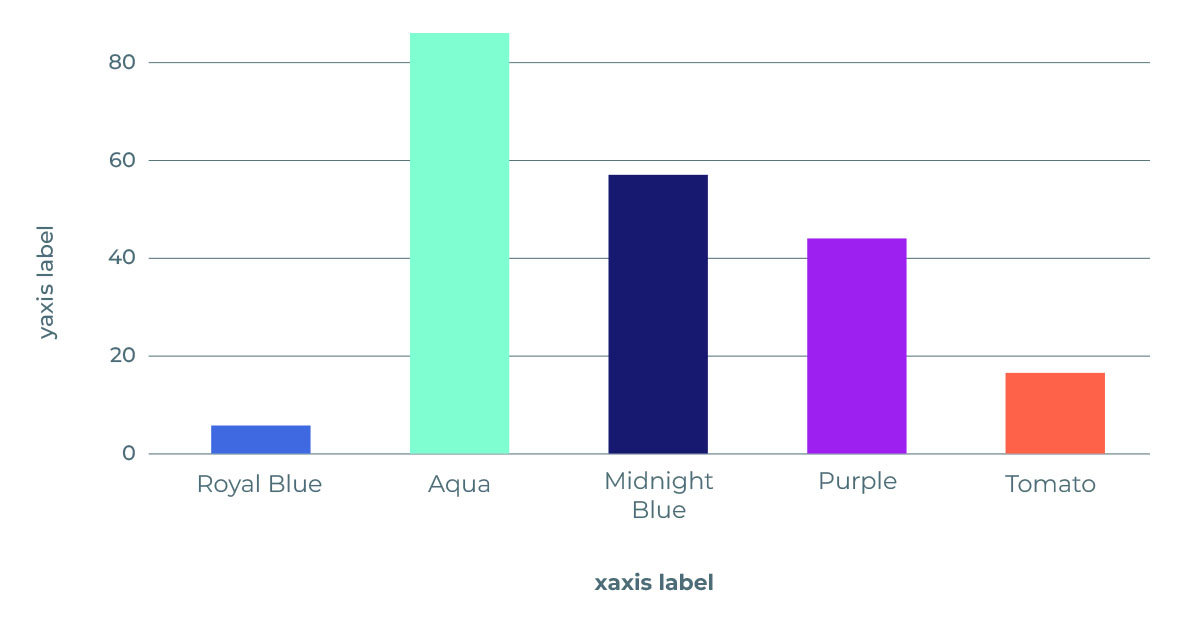
Is royal blue the minimum?
Is midnight blue more than purple?
Is aqua the maximum?
VQA Framework with Deep Learning
In order to resolve CV tasks, VQA systems require image recognition and NLP techniques as well as a publicly-available dataset to validate the task. VQA frameworks combine two Deep Learning architectures to deliver the final answer: Convolutional Neural Networks (CNN) for image recognition and Recurrent Neural Network (RNN) (and its special variant Long Short Term Memory networks or LSTM) for NLP processing. Unlike traditional RNN architectures, LSTM can solve VQA tasks because it can memorize important information and connect information to understand context – both of which are needed to solve NLP VQA problems and generate fairly accurate and human-understandable natural language answers.
In 2016, researchers from Germany’s Max Planck Institute for Informatics proposed a Deep Learning end-to-end architecture for VQA tasks called Ask Your Neurons. Its proposed neural architecture can provide fairly accurate answers to natural language questions about images.
The approach has a RNN at its core. Image information is encoded via a CNN, and the question and the visual representation are fed into a LSTM network. The CNN and LSTM are trained jointly to produce correct answers to questions about input images.
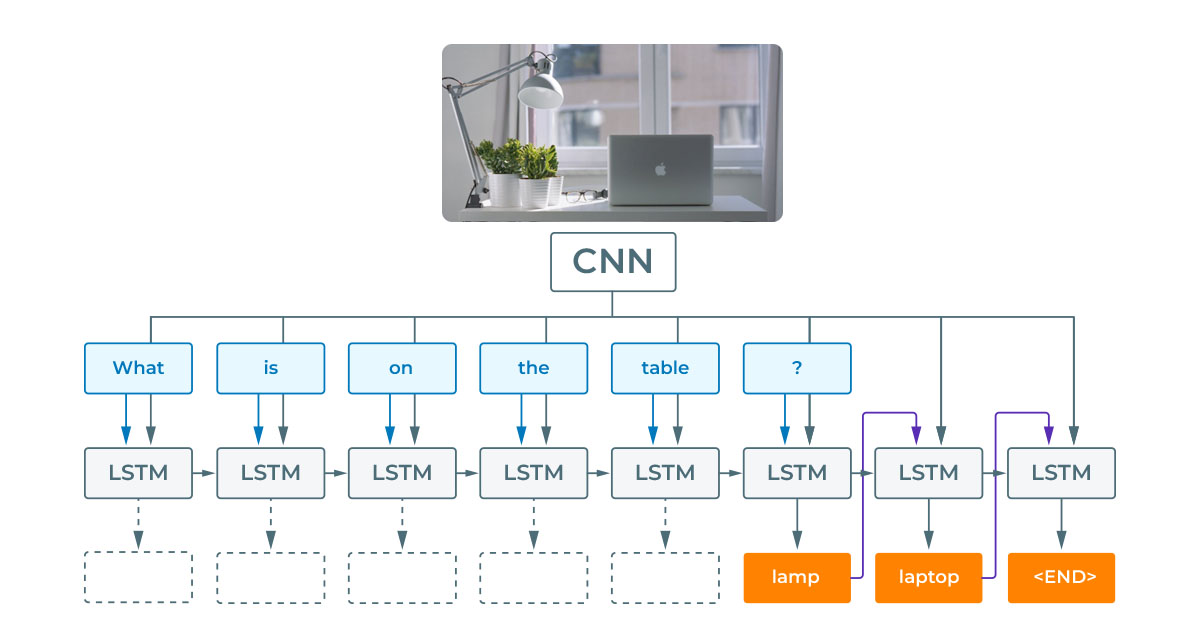
With Ask Your Neurons, the researchers showed that VQA can be achieved with a single RNN for question and image encoding and answering. However, a modular framework can also be designed where a question encoder is combined with a visual encoder to produce answers with an answer decoder.
Real-world Applications of VQA
VQA has many applications in real-world scenarios where visual content needs to be queried and understood and presented in a natural language to some end user. For example, VQA is useful for NLP-based image retrieval systems that can be used on eCommerce sites and apps to provide shoppers with more accurate results to their search queries. Similarly, VQA on online educational portals can help learners to interact with images and enhance their overall learning outcomes.
VQA can also aid visually-impaired individuals by providing information about digital or real-world images. For instance, a blind user could query an image on social media and get more insights about the scene it represents. The VQA system trained with an NLP library like Spark NLP will understand the user’s question, perform analysis on it, and then present the answer orally in a natural language the user understands (e.g. Spanish or Arabic).
Two other possible applications of VQA are self-driving cars and data analysis. For example, VQA can help the car understand and correctly act on a command like “Park up ahead behind the silver car and next to the parking meter”. In data analysis, VQA can help users to summarize available visual information, extract tables from documents and images, etc.
Conclusion
Visual question answering is a fast-growing, multi-disciplinary field with immense potential to resolve real-world problems using natural language processing and understanding. This explains why many practical applications have been discovered for VQA in just the last half decade.
That said, there are several shortcomings in existing VQA models and algorithms that must be addressed to truly bring the idea into the mainstream. For one, existing VQA benchmarks are insufficient to evaluate whether an algorithm has really solved a VQA problem. Also, larger datasets are needed to train, evaluate, and improve VQA algorithms. The datasets must also be less biased, both in images and in questions, since bias inhibits the ability of the algorithm to produce an accurate answer and solve the VQA problem.
The good news is that if the current pace of research and development continues, many more applications will emerge for visual question answering in Deep Learning in the near future. And NLP researchers and pioneers like John Snow Labs are helping to put VQA and NLP to good use for an increasing number of real-world challenges and applications. Exciting times lie ahead for VQA, CV, and NLP.




