






















































Unleash the Potential of Your Texts with Powerful Keywords Extraction Using NLP and Python

TL; DR: Keyword extraction is the process of automatically extracting the most important words and phrases from a document or text. Using Spark NLP, it is possible to accurately extract keywords from any text.
Extracting keywords is a technique in natural language processing (NLP) that involves automatically identifying the most important words or phrases in a document or corpus. Keywords you get from a text can be used in a variety of ways, including:
- Document indexing: Keywords extracted from a text can be used to index the document, making it easier to search for and retrieve relevant information.
- Document summarization: Keywords can be used to summarize the main topics or themes of a document, helping users quickly understand its content without having to read the entire document.
- Content categorization: Keywords can be used to categorize documents based on their content, allowing users to easily find documents on specific topics.
- Content tagging: Keywords can be used to tag documents with relevant labels or metadata, making it easier to organize and manage large collections of documents.
- Search engine optimization: Keywords can be used to optimize web content for search engines, helping to improve its visibility and ranking in search results.
Extracting keywords from texts has become difficult for individuals and organizations as the complexity and volume of information have grown. The need to automate this task so that text can be processed promptly and adequately has led to the emergence of automatic keyword extraction tools. NLP and Python libraries help in the process.
NLP in Healthcare: Transformative Trends in 2025-2026
Beyond general applications of keyword extraction, the healthcare sector is experiencing unique advancements that are reshaping how NLP delivers value to patients and providers
The Explosive Growth of Healthcare NLP Market
The healthcare NLP market experienced remarkable expansion in 2025, reaching $7.76 billion and demonstrating unprecedented momentum with compound annual growth rates exceeding 25%. This explosive growth reflects the healthcare industry’s urgent need to process vast amounts of unstructured clinical data efficiently. Text summarization emerged as the fastest-growing NLP technique, addressing the critical challenge of information overload faced by healthcare professionals who must synthesize insights from clinical notes, research papers, and patient records. Organizations are increasingly leveraging keyword extraction and document summarization to transform mountains of medical literature and patient data into actionable insights, enabling faster clinical decision-making and improved patient outcomes.
(Source: Precedence Research; MarketsandMarkets).
Large Language Models Revolutionizing Clinical Practice
Throughout 2025, large language models demonstrated promising applications across clinical decision support, medical education, diagnostics, and patient care. Some advanced models have outperformed junior medical trainees in specific medical knowledge assessments, while showing variable performance across different medical specialties and clinical tasks. These developments are reshaping how healthcare professionals interact with medical knowledge, with Large Language Models (LLMs) assisting in rapid processing and interpretation of electronic health records, imaging results, and complex patient data. However, clinicians face growing challenges in determining the most suitable algorithms to support their work amid rapid LLM development, necessitating careful evaluation frameworks and clinical validation protocols before widespread deployment.
Multimodal AI and EHR Automation Advances
The path towards 2026 involves solidifying generative AI capabilities while pioneering agentic and multimodal intelligence within frameworks emphasizing responsible AI deployment and local validation. AI tools became capable of automating routine documentation tasks, with NLP systems reading unstructured clinical text and automatically transforming it into structured, analyzable information for the first time. Advanced medical coding platforms using AI and NLP have shown high accuracy in ICD-10 code assignment and significant efficiency gains in clinical workflows, with large-scale ambient AI scribe deployments already supporting over 7,000 physicians and 2.5 million patient encounters in real-world settings. These automation advances are reducing administrative burden on healthcare providers, improving coding accuracy for billing and compliance, and enabling more time for direct patient care, a critical development as healthcare systems worldwide face increasing demands and workforce shortages.
(Sources: npj Digital Medicine; Journal of Medical Internet Research).
How to extract keywords from text with NLP & Python
Keyword extraction can be done using a variety of techniques, including statistical methods, machine learning algorithms, and natural language processing tools.
Yake! is a novel feature-based system for multi-lingual keyword extraction, which supports texts of different sizes, domain or languages.
Unlike other approaches, Yake! does not rely on dictionaries nor thesauri, neither is trained against any corpora. Instead, it follows an unsupervised approach which builds upon features extracted from the text, making it thus applicable to documents written in different languages without the need for further knowledge. This can be beneficial for a large number of tasks and a plethora of situations where access to training corpora is either limited or restricted.
YAKE!‘s algorithm rests on text statistical features extracted from single documents. Each extracted keyword will be given a keyword score greater than 0 (the lower the score better the keyword).
In this post, you will learn how to perform NLP keyword extraction using the YakeKeywordExtraction annotator, Spark NLP, and Python.
Let us start with a short Spark NLP introduction and then discuss the details of extracting keywords from a text with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotation for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
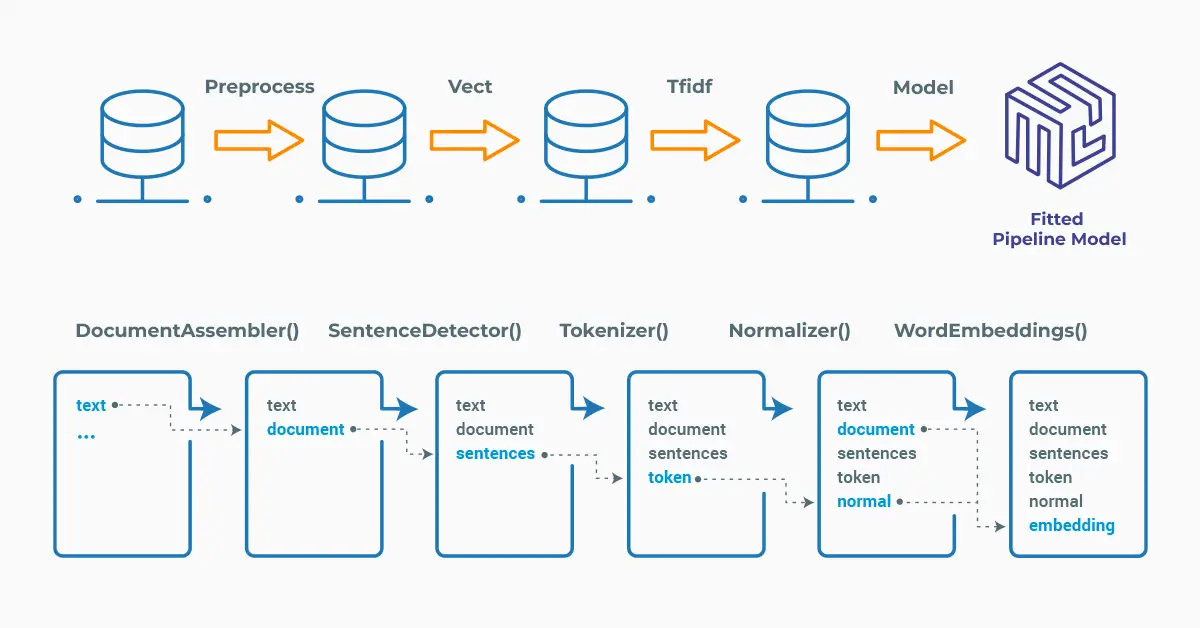
Spark NLP pipelines
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
How do you set up Spark NLP for keyword extraction
To install Spark NLP and extract keywords in Python, simply use your favorite package manager (conda, pip, etc.). For example:
pip install spark-nlp pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
Defining the Spark NLP Pipeline
The YakeKeywordExtraction annotator expects TOKEN as input, and then will provide CHUNK as output. Thus, we need the previous steps to generate those annotations that will be used as input to our annotator.
Spark NLP has the pipeline approach and the pipeline will include the necessary stages.
YAKE! algorithm makes use of the position of a sentence and token. Therefore, to use the annotator, the text should be first sent through a Sentence Detector and then a Tokenizer.
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline
from sparknlp.annotator import (
SentenceDetector,
Tokenizer,
YakeKeywordExtraction
)
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
# Step 2: Sentence Detection
sentenceDetector = SentenceDetector() \
.setInputCols("document") \
.setOutputCol("sentence")
# Step 3: Tokenization
token = Tokenizer() \
.setInputCols("sentence") \
.setOutputCol("token") \
.setContextChars(["(", ")", "?", "!", ".", ","])
# Step 4: Keyword Extraction
keywords = YakeKeywordExtraction() \
.setInputCols("token") \
.setOutputCol("keywords") \
# Define the pipeline
yake_pipeline = Pipeline(stages=[document, sentenceDetector, token, keywords])
# Create an empty dataframe
empty_df = spark.createDataFrame([['']]).toDF("text")
# Fit the dataframe to get the
yake_Model = yake_pipeline.fit(empty_df)
How can LightPipeline simplify keyword extraction
LightPipeline is a Spark NLP specific Pipeline class equivalent to Spark ML Pipeline. The difference is that its execution does not hold to Spark principles, instead it computes everything locally (but in parallel) in order to achieve fast results when dealing with small amounts of data. This means, we do not input a Spark Dataframe, but a string or an Array of strings instead, to be annotated.
light_model = LightPipeline(yake_Model) text = ''' google is acquiring data science community kaggle. Sources tell us that google is acquiring kaggle, a platform that hosts data science and machine learning competitions. Details about the transaction remain somewhat vague , but given that google is hosting its Cloud Next conference in san francisco this week, the official announcement could come as early as tomorrow. Reached by phone, kaggle co-founder ceo anthony goldbloom declined to deny that the acquisition is happening. google itself declined 'to comment on rumors'. kaggle, which has about half a million data scientists on its platform, was founded by Goldbloom and Ben Hamner in 2010. The service got an early start and even though it has a few competitors like DrivenData, TopCoder and HackerRank, it has managed to stay well ahead of them by focusing on its specific niche. The service is basically the de facto home for running data science and machine learning competitions. With kaggle, google is buying one of the largest and most active communities for data scientists - and with that, it will get increased mindshare in this community, too (though it already has plenty of that thanks to Tensorflow and other projects). kaggle has a bit of a history with google, too, but that's pretty recent. Earlier this month, google and kaggle teamed up to host a $100,000 machine learning competition around classifying YouTube videos. That competition had some deep integrations with the google Cloud platform, too. Our understanding is that google will keep the service running - likely under its current name. While the acquisition is probably more about Kaggle's community than technology, kaggle did build some interesting tools for hosting its competition and 'kernels', too. On kaggle, kernels are basically the source code for analyzing data sets and developers can share this code on the platform (the company previously called them 'scripts'). Like similar competition-centric sites, kaggle also runs a job board, too. It's unclear what google will do with that part of the service. According to Crunchbase, kaggle raised $12.5 million (though PitchBook says it's $12.75) since its launch in 2010. Investors in kaggle include Index Ventures, SV Angel, Max Levchin, Naval Ravikant, google chief economist Hal Varian, Khosla Ventures and Yuri Milner ''' light_result = light_model.fullAnnotate(text)[0]
We can show the results in a Pandas DataFrame by running the following code:
keys_df = pd.DataFrame([(k.result, k.begin, k.end, k.metadata['score'], k.metadata['sentence']) for k in light_result['keywords']],
columns = ['keywords','begin','end','score','sentence'])
keys_df['score'] = keys_df['score'].astype(float)
# ordered by relevance
keys_df.sort_values(['sentence','score']).head(100)
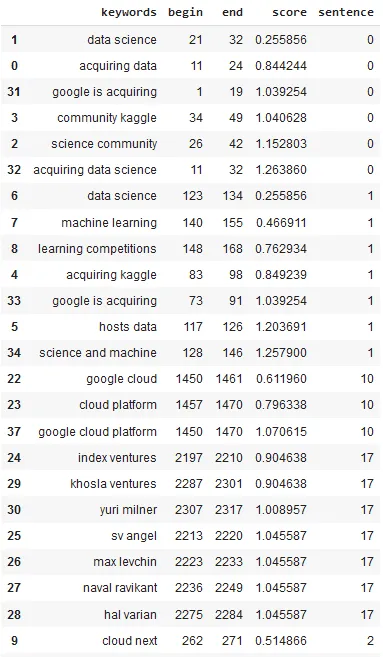
Extracted keywords
We will not discuss the details here, but we have a notebook about the details of the keyword extraction process. also, you can check YakeKeywordExtraction page for the annotator parameters, which involves details to the natural language processing keyword extraction. The parameters will help you to:
- Define the minimum and maximum number of words in a keyword,
- Total number of keywords to be extracted from the text,
- Define a list of stopwords (to be ignored during extraction),
- Define a threshold to filter the extracted keywords.
Highlighting Keywords in a Text
In addition to getting the keywords as a dataframe, it is also possible to highlight the extracted keywords in the text.
In this example, a dataset of 7537 texts were used — samples from the PubMed, which is a free resource supporting the search and retrieval of biomedical and life sciences literature.
! wget -q https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/pubmed/pubmed_sample_text_small.csv
df = spark.read\
.option("header", "true")\
.csv("pubmed_sample_text_small.csv")\
df.show(truncate=50)

Sample texts from the PubMed database
In this case, instead of using the LightPipeline, we use transform to get predictions from the dataframe of PubMed documents (df).
# Fit and transform the dataframe to get the predictions
result = yake_pipeline.fit(df).transform(df)
result = result.withColumn('unique_keywords', F.array_distinct("keywords.result"))
def highlight(text, keywords):
for k in keywords:
text = (re.sub(r'(\b%s\b)'%k, r'\1', text, flags=re.IGNORECASE))
return text
highlight_udf = udf(highlight, StringType())
result = result.withColumn("highlighted_keywords",highlight_udf('text','unique_keywords'))
for r in result.select("highlighted_keywords").limit(20).collect():
display(HTML(r.highlighted_keywords))
print("\n\n")
You may prefer to get a visual result instead of a dataframe and you will get a nice result of texts, with the highlighted keywords.

Highlighted keywords in text 1

Highlighted keywords in text 2
For additional information, please consult the following references.
- Documentation YakeKeywordExtraction
- Python keyword extraction: Docs about are here
- Scala Docs: YakeKeywordExtraction
- For extended examples of usage, see the Spark NLP Workshop repository.
- Reference Paper: YAKE! Keyword extraction from single documents using multiple local features
What Are the Key Takeaways from Keyword Extraction with Spark NLP and Python?
Keywords extraction is the NLP technique that involves identifying and extracting the most important words or phrases from a piece of text. The extracted keywords can be used to summarize the content of the text, to identify the main topics and themes discussed in the text, or to facilitate information retrieval.
YakeKeywordExtraction is a keyword extraction technique implemented in Spark NLP. Yake is a novel feature-based system for multi-lingual extracting keywords from a text, which supports texts of different sizes, domain or languages.
FAQ
- Why is keyword extraction important in healthcare NLP?
Keyword extraction helps clinicians and researchers quickly identify critical medical concepts from unstructured data such as clinical notes, radiology reports, and patient histories. This accelerates information retrieval, supports diagnostic decision-making, and improves patient outcomes. - What were the key advancements in keyword extraction in 2025?
In 2025, healthcare NLP advanced through multimodal keyword extraction (combining text with images, genomics, and wearable data), federated learning to preserve patient privacy, and the first successful pilots of real-time clinical deployment that reduced triage time in emergency care. - How does federated learning improve keyword extraction in medicine?
Federated learning allows hospitals and research institutions to collaboratively train keyword extraction models without centralizing sensitive patient data. This ensures compliance with privacy laws like GDPR and the EU AI Act while maintaining model accuracy across distributed datasets. - Can Spark NLP handle large-scale multilingual healthcare data?
Yes. Spark NLP supports a wide range of languages and offers a large collection of pretrained pipelines and models, enabling accurate keyword extraction and other NLP tasks for diverse medical datasets. - What trends can we expect in healthcare NLP by 2026?
By 2026, real-time NLP will be a core feature of clinical systems, enabling physicians to receive instant keyword insights during consultations. This evolution is expected to improve diagnostic alignment, reduce time to treatment, and support scalable adoption of AI in hospitals.




