
























































What will we learn in this article?
We will set up our own Databricks cluster with all dependencies required to run Spark NLP in either Python or Java.
This tutorial consists of the following simple steps :
- Create a Databricks cluster
- Setup Python dependencies for Spark NLP in the Databricks Spark cluster
- Setup Java dependencies for Spark NLP in the Databricks Spark cluster
- Test out our cluster
The NLP domain of machine learning has been continuously breaking records in many of the NLP related tasks like part-of-speech tagging, question answering, relation extraction, spell checking, and many more!
In particular a new breed of transformer-based models that can learn and leverage context in sentences to solve these problems and have been responsible for these breakthroughs.
All the text data in the world out there is like a giant pool of oil. NLP research provides us with methods for extracting value from these valuable oily pools of text. The code resulting from NLP research is usually not scalable, which leaves us with just a very tiny and inefficient oil pump for our oil…
This is where Spark NLP comes into play. It basically gives you a huge data pump which is highly scalable and efficient!
- Wouldn’t you like to play around these state of the art (SOTA) models in NLP?
- Don’t you want to save time setting up tediously your local environment to get your fingers on SOTA algorithms like Bert, Albert, ELMO, XLNet, and more?
- Should that all scale well with terabytes of data?
Then Spark-NLP is what you need!
What is Spark NLP and who uses it?
Spark NLP is an award-winning library running on top of Apache Spark distribution engine. It provides the first production-grade versions of the latest deep learning NLP research.

“The most widely used NLP library in the enterprise”
backed by O’Reilly’s most recent “AI Adoption in the Enterprise” survey in February

Widely used by fortune 500 companies
Why is Spark NLP so widely used?
It’s easy and fast to achieve results close to the SOTA in many of the NLP tasks using the latest deep learning NLP research methods which are provided by Spark NLP. All of this will be made scalable by leveraging Spark’s built-in distribution engine.
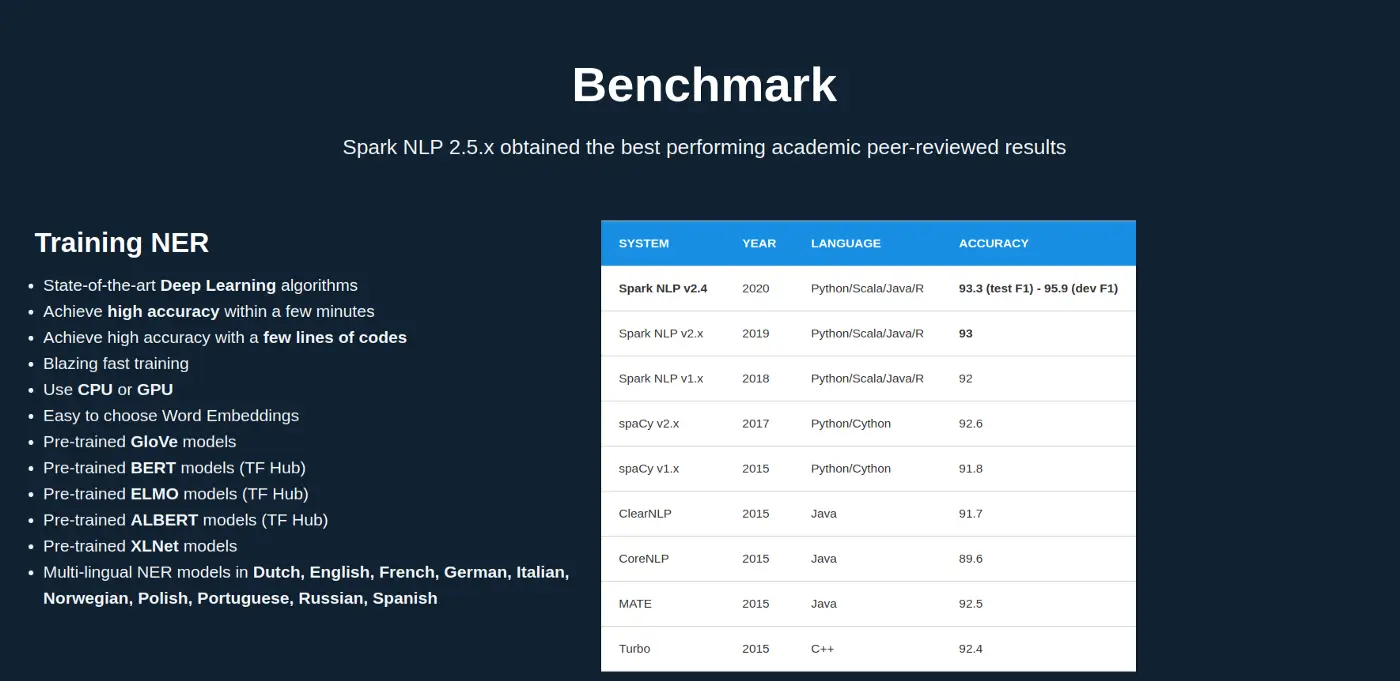
Easy and fast SOTA with Spark NLP

If you are thinking,
- How to get started with NLP in Python quickly
- How to set up a Spark-NLP Python Databricks cluster
- How to configure Databricks for Python and Spark-NLP
- I wanna be rich like an oil baron
You have come to the right place my NLP hungry friend!
In this little tutorial, you will learn how to set up your Python environment for Spark-NLP on a community Databricks cluster with just a few clicks in a few minutes! Let’s get started!
0. Login to Databricks or get an account
First login to your Databricks accounts or create one real quick. It’s completely free! https://community.cloud.databricks.com/
1. Create a cluster with the latest Spark version
Select the Clusters tab on the left side and click on create a new cluster. Make sure you select one of the currently supported Databricks runtimes which you can find here In This example we will be using the 6.5 runtime
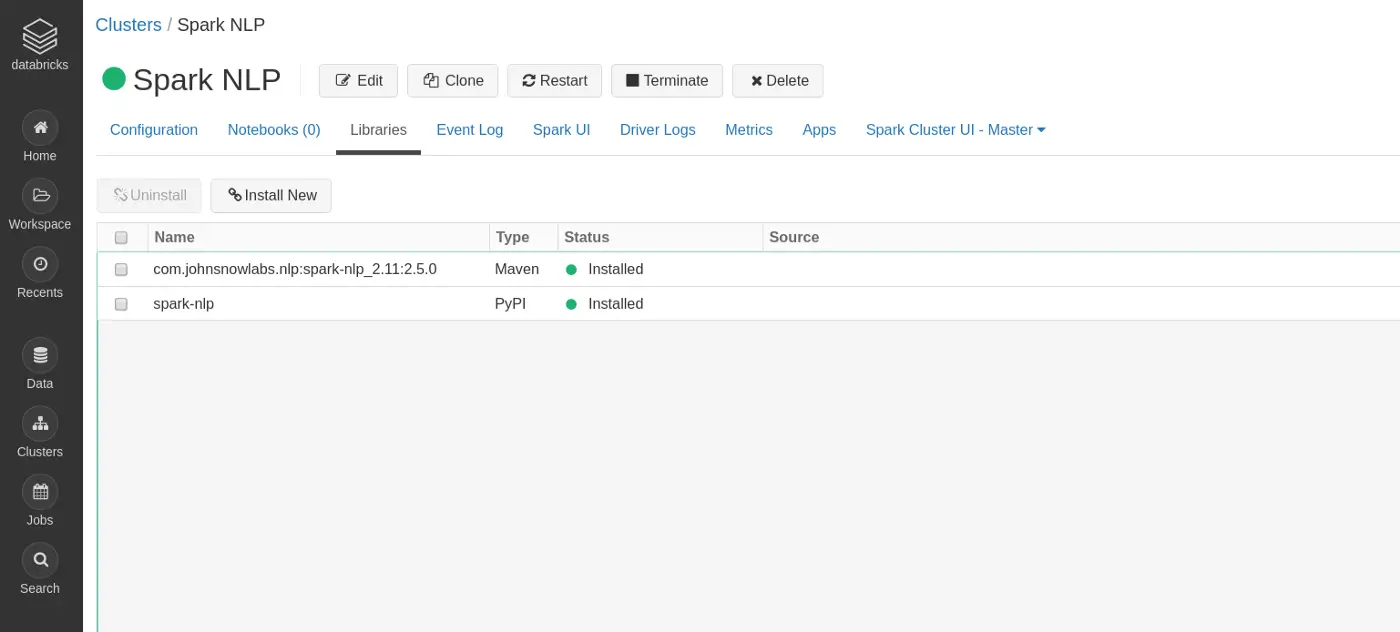
2. Install Python Dependencies to cluster
Select your newly created cluster in the clusters tab and then select the Libraries tab. In that menu click on Install New and select the PyPI tab.
3. Install Java Dependencies to cluster
In the same window as before, select Maven and enter these coordinates and hit install. These dependencies are required since even if you only want to run Spark NLP in Python it will invoke computations on the JVM which depend on the Spark NLP library.
You can get the latest MVN coordinates here, the <groupId:atifactId:version> format is expected.
That’s it for setting up your cluster! After a few moments, everything should look like this
4. Let’s test out our cluster real quick
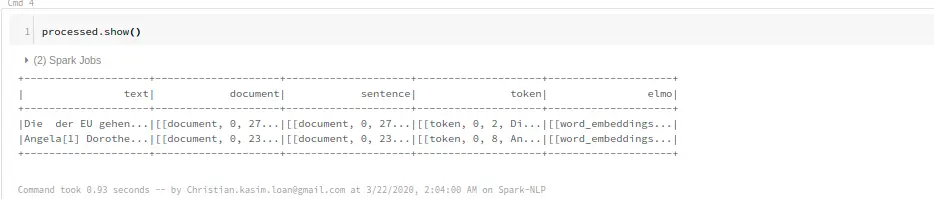
Create a new Python Notebook in Databricks and copy-paste this code into your first cell and run it. The following example demonstrates how to get token embeddings for raw input sentences
This is a fully-fledged state of the art pipeline which generates token embeddings with the official ELMO model which can be used for following downstream tasks.
from pyspark.sql.types import StringType
#Spark NLP
import sparknlp
from sparknlp.pretrained import PretrainedPipeline
from sparknlp.annotator import *
from sparknlp.base import *#If you need to set any Spark config
spark.conf.set('spark.serializer', 'org.apache.spark.serializer.KryoSerializer')#Create Dataframe with Sample data
dfTest = spark.createDataFrame([
"Spark-NLP would you be so nice and cook up some state of the art embeddings for me?",
"Tensorflow is cool but can be tricky to get Running. With Spark-NLP, you save yourself a lot of trouble.",
"I save so much time using Spark-NLP and it is so easy!"
], StringType()).toDF("text")#Basic Spark NLP Pipelinedocument_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document") \sentence_detector = SentenceDetector() \
.setInputCols(["document"]) \
.setOutputCol("sentence")tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")elmo = ElmoEmbeddings.pretrained() \
.setInputCols(["token", "document"]) \
.setOutputCol("elmo") \
.setPoolingLayer("elmo")nlpPipeline = Pipeline(stages=[
document_assembler,
sentence_detector,
tokenizer,
elmo,
])nlp_model = nlpPipeline.fit(dfTest)
processed = nlp_model.transform(dfTest)
processed.show()
Congratulations!
You are now ready for Spark-NLP in your Databricks cluster and enjoy the latest and most scalable NLP models out there!
Conclusion
Spark NLP is easy to set up, reliable and fast! It always provides the latest SOTA models in NLP shortly after they are released.
What we have learned
- How to set up a Spark-NLP Python Databricks cluster
- How to set up a Spark-NLP Scala Databricks cluster
- How to set up a Spark-NLP working environment
- How to get started with Spark-NLP in Python
- How to configure Databricks for Python and Spark-NLP
- How to get started with Spark-NLP easy and quickly
Next Steps:
If this got your appetite started for more NLP and Spark in Python, Scala, Java or R you should next head to these Spark-NLP tutorials:
- Introduction to Spark NLP: Foundations and Basic Components (Part-I)
- Introduction to: Spark NLP: Installation and Getting Started (Part-II)
- Spark NLP 101 : Document Assembler
- Spark NLP 101: LightPipeline
- Spark NLP workshop repository
- Spark NLP NER
- Applying Context Aware Spell Checking in Spark NLP
- Spark NLP Youtube Channel
Setting up Spark NLP on Databricks allows for scalable natural language processing, which can be leveraged to enhance Generative AI in Healthcare and power a Healthcare Chatbot, enabling faster, more efficient patient interactions and improving healthcare delivery.



