Happy New 2021! We are excited to welcome the new year with the release of Spark NLP 2.7. This has been one of the biggest releases we have ever done, and we are proud to share it with the open-source AI community!
In this release, we are bringing support to state-of-the-art Seq2Seq and Text2Text transformers. This includes new annotators for Google T5 (Text-To-Text Transfer Transformer) and MarianMNT for Neural Machine Translation – with over 646 new pre-trained models and pipelines.
This release also comes with refactored and brand-new models for language detection and identification. They are more accurate, faster, and support up to 375 languages.
The 2.7 release has over 720+ new NLP pretrained models and pipelines while extending our support of multi-lingual models to 192+ languages such as Chinese, Japanese, Korean, Arabic, Persian, Urdu, and Hebrew.
As always, we would like to thank our community for their feedback and support.
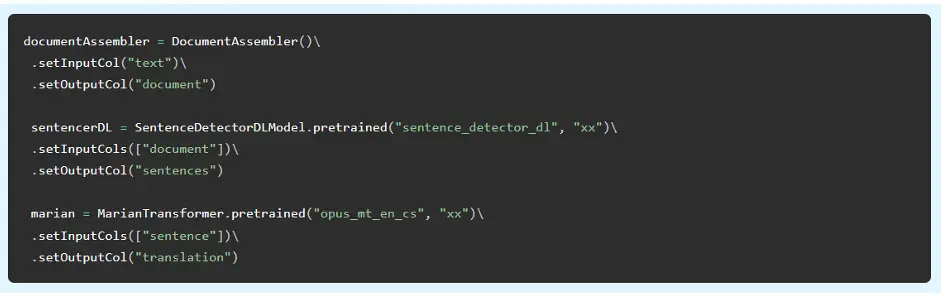
Translation with MarianNMT
This release introduces the MarianTransformer annotator for machine translation based on MarianNMT models. Marian is an efficient, free Neural Machine Translation framework mainly being developed by the Microsoft Translator team (646+ pretrained models & pipelines in 192+ languages).
This provides you with fast, scalable, production-grade, free & open-source machine translation – with just a few lines of code. Here is an example of translating English to Czech:
Translation with T5
The new T5Transformer annotator for Text-To-Text Transfer Transformer (Google T5) models achieves state-of-the-art results on multiple NLP tasks such as Translation, Summarization, Question Answering, and Sentence Similarity. Here is an example of how you automatically translate English to Marathi:

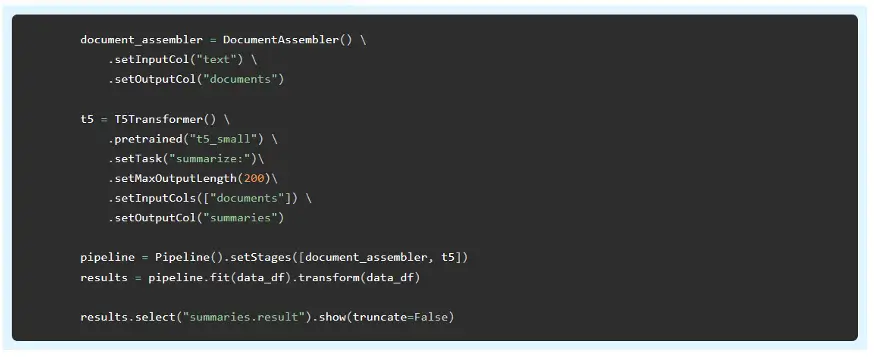
Summarization
The same T5Transformer can also provide state-of-the-art summarization. Here is an example of building a customized Spark NLP pipeline that gets this done:
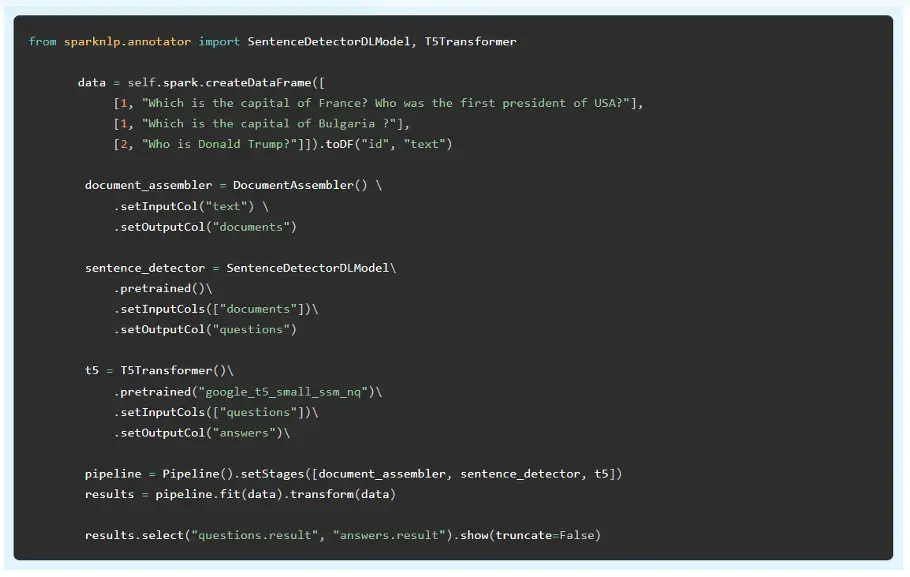
Closed-Book Question Answering
This is a text-to-text model trained by Google on the colossal, cleaned version of Common Crawl’s web crawl corpus (C4) data set and then fined tuned on Wikipedia and the natural questions (NQ) dataset. The model can answer free text questions, such as “Which is the capital of France?” without relying on any context or external resources:

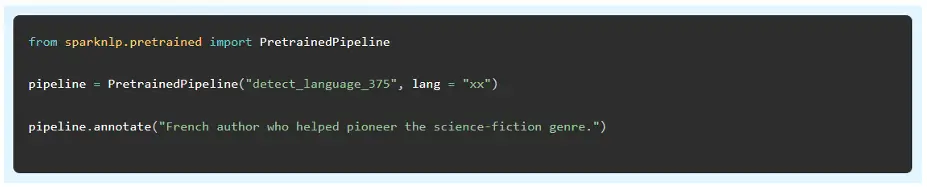
Detecting 375 Languages
This release introduces brand new language detection and identification models. The new LanguageDetectorDL is faster, more accurate, and supports up to these 375 languages:

This is all it takes to use this pre-trained functionality:
Supporting 192 Languages – with new Asian, African, and right-to-left Languages
Spark NLP now comes with pre-trained models & pipelines for 192 human languages. Beyond adding and updating models for many languages, this release introduces code changes and new algorithms for supporting a broader range of languages.
Right-to-left languages – Arabic, Farsi, Urdu, and Hebrew – and now fully supported. For example, for Hebrew there are now pre-trained models for lemmatization, part-of-speech tagging, stop word removal, translation, named entity recognition (NER), as well as pre-trained word embeddings. The Spark NLP Demo Hub has new published apps that show NER in Hebrew, Arabic, Farsi, Turkish, and Japanese:

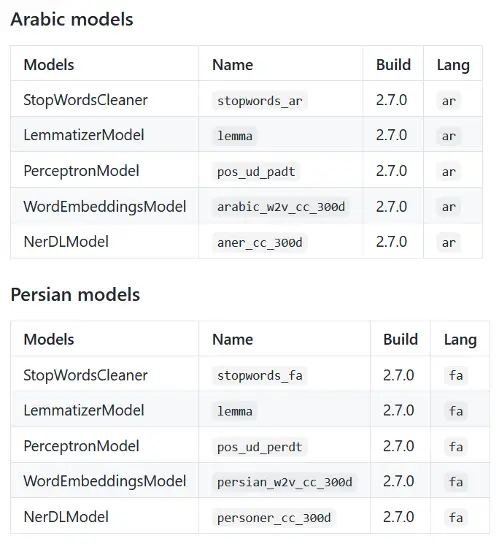
These are the new models for Arabic and Farsi:
addition to the new pre-trained models, multiple code enhancements make it easier to add support for new languages and train your own models for analyzing domain-specific text:
- Added support for new multi-lingual models in UniversalSentenceEncoder annotator
- Added support to Lemmatizer to be trained directly from a DataFrame instead of a text file
- Added training helper to transform CoNLL-U into Spark NLP annotator type columns
Word Segmentation for Chinese, Japanese, and Korean
This release introduces the new WordSegmenter annotator: a trainable annotator for word segmentation of languages without rule-based tokenization.
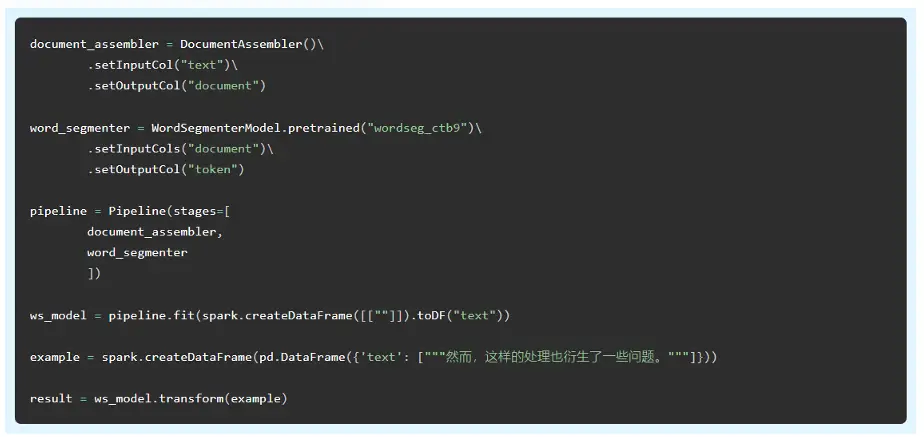
For Mandarin Chinese, WordSegmenterModel (WSM) is based on a maximum entropy probability model to detect word boundaries in Chinese text. Chinese text is written without white space between the words, and a computer-based application cannot know a priori which sequence of ideograms form a word. Many natural language processing tasks such as part-of-speech (POS) and named entity recognition (NER) require word segmentation as a initial step.
We trained this model on the Chinese Penn Treebank version 9 data set. Here is an example of how the models are used. Note that both fit() and transform() are available, for training and inference respectively.

Document Normalizer
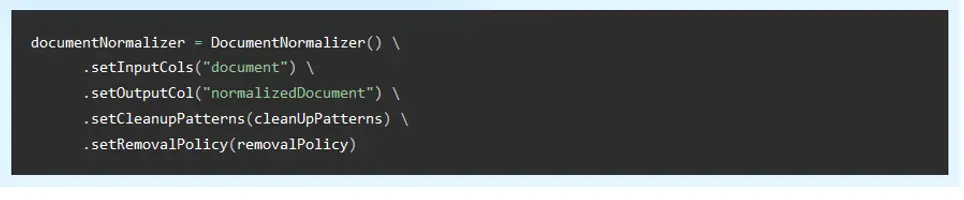
The new DocumentNormalizer annotator cleans content from HTML or XML documents, applying either data cleansing using an arbitrary number of custom regular expressions, or data extraction following the provided parameters. It’s highly useful when processing crawled web pages. Here’s how it’s used as part of a Spark NLP pipeline:
Spark NLP Display – a library for visualizing text annotations
The new sparknlp-display natural language processing Python library is an open-source library for visualizing the annotations generated with Spark NLP. It currently offers out-of-the-box support for these annotations:
- Dependency Parser
- Named Entity Recognition
- Entity Resolution
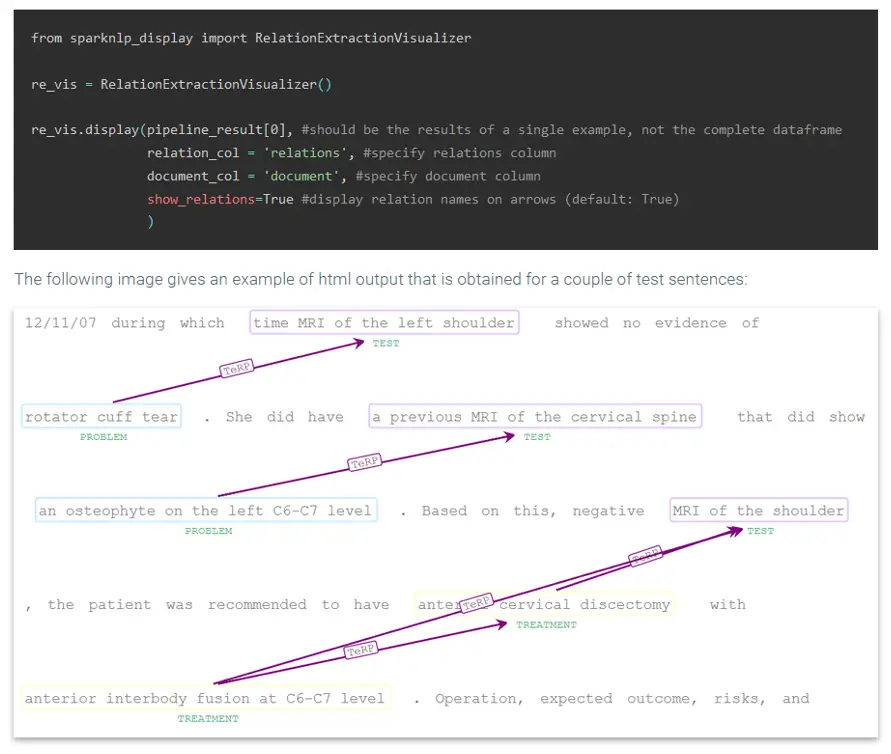
- Relation Extraction
- Assertion Status
The ability to quickly visualize the entities, relations, assertion statuses, etc. generated using Spark NLP is a very useful feature for speeding up the development process as well as for explaining the obtained results. Getting all of this in a one-liner is extremely convenient – especially when running Jupyter notebooks which offers full support for HTML visualizations.
The visualisation classes work with the outputs returned by both Pipeline.transform() function and LightPipeline.fullAnnotate(). Here is an example of visualizing relationships between named entities:
By leveraging the advancements in Generative AI in Healthcare, these visualizations can significantly enhance the effectiveness of Healthcare Chatbots, allowing them to better understand and respond to user queries in multiple languages with higher precision.
Get it & Put it to good use!
Spark NLP 2.7 is free, open source, and available now along with updates documentation & examples:
Spark NLP in Action: Live Demos & Notebooks
Happy New Year!