
























































NLP Lab 5.7 marks a significant update in the management of images containing text and scanned PDF documents with enhanced support for Visual OCR Pipelines. The Visual OCR Pipelines significantly enhance PDF and image document handling and ensure accurate, consistent, and precise text extraction. This improves the OCR results on imported PDF and/or image tasks for NER and text Classification projects.
This new release demonstrates our continuous commitment to delivering advanced tools for text analysis and document processing tailored to address our users’ evolving needs. Detailed descriptions of this new feature are provided below.
Supported Pipelines and Usage Instruction
NLP Lab version 5.7 introduces a set of seven Visual OCR Pipelines, each tailored for specific purposes, providing users with versatile options to address diverse document processing needs:
- mixed_scanned_digital_pdf
- mixed_scanned_digital_pdf_image_cleaner
- mixed_scanned_digital_pdf_skew_correction
- image_printed_transformer_extraction
- pdf_printed_transformer_extraction
- image_handwritten_transformer_extraction
- pdf_handwritten_transformer_extraction
These pipelines offer a comprehensive set of tools, each optimized for specific scenarios, providing flexibility and precision in processing various document types in OCR projects within the NLP Lab.
User Guide
To enable OCR functionality and perform OCR tasks, follow these steps:
- Go to the Task Import Page.
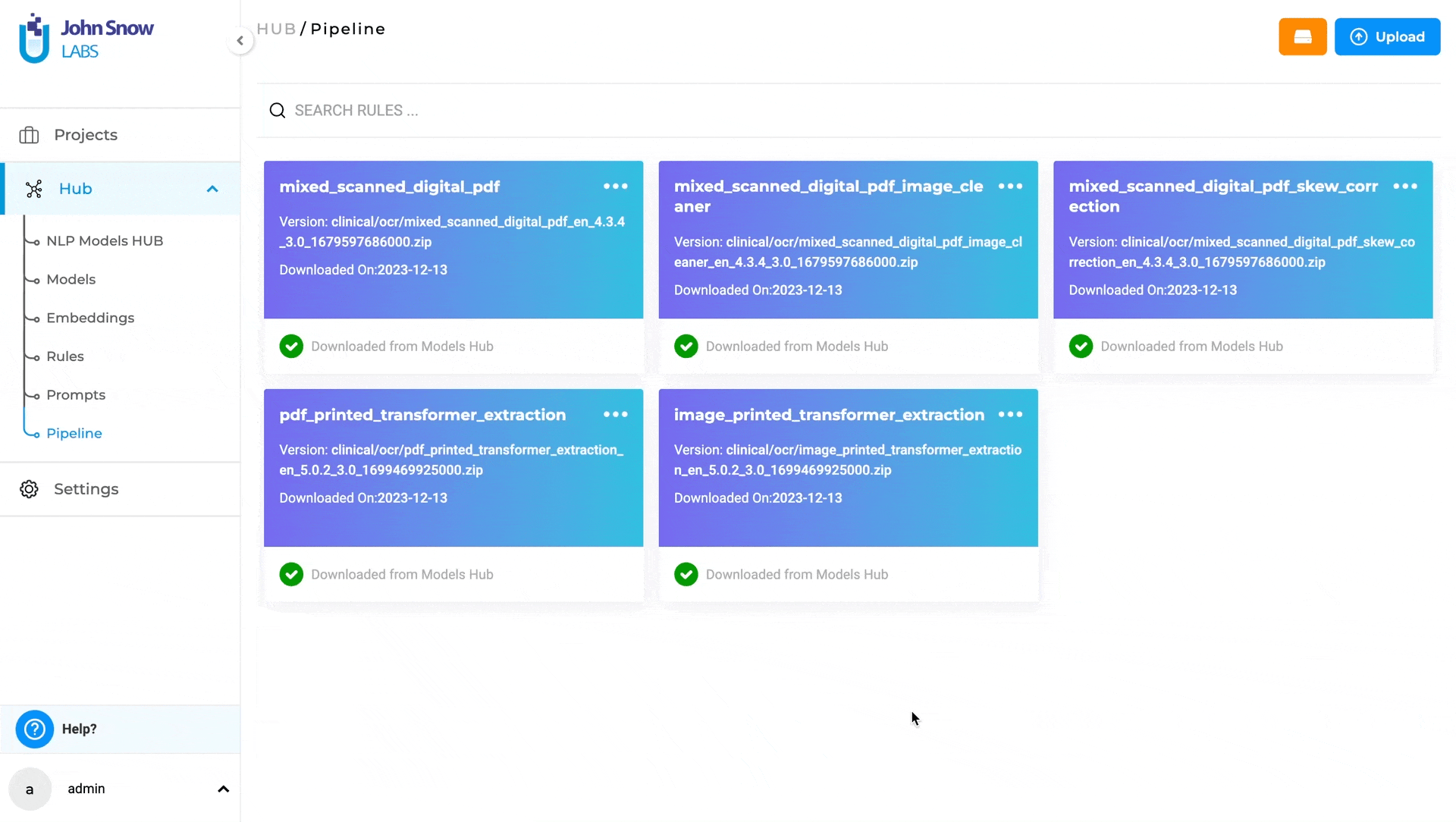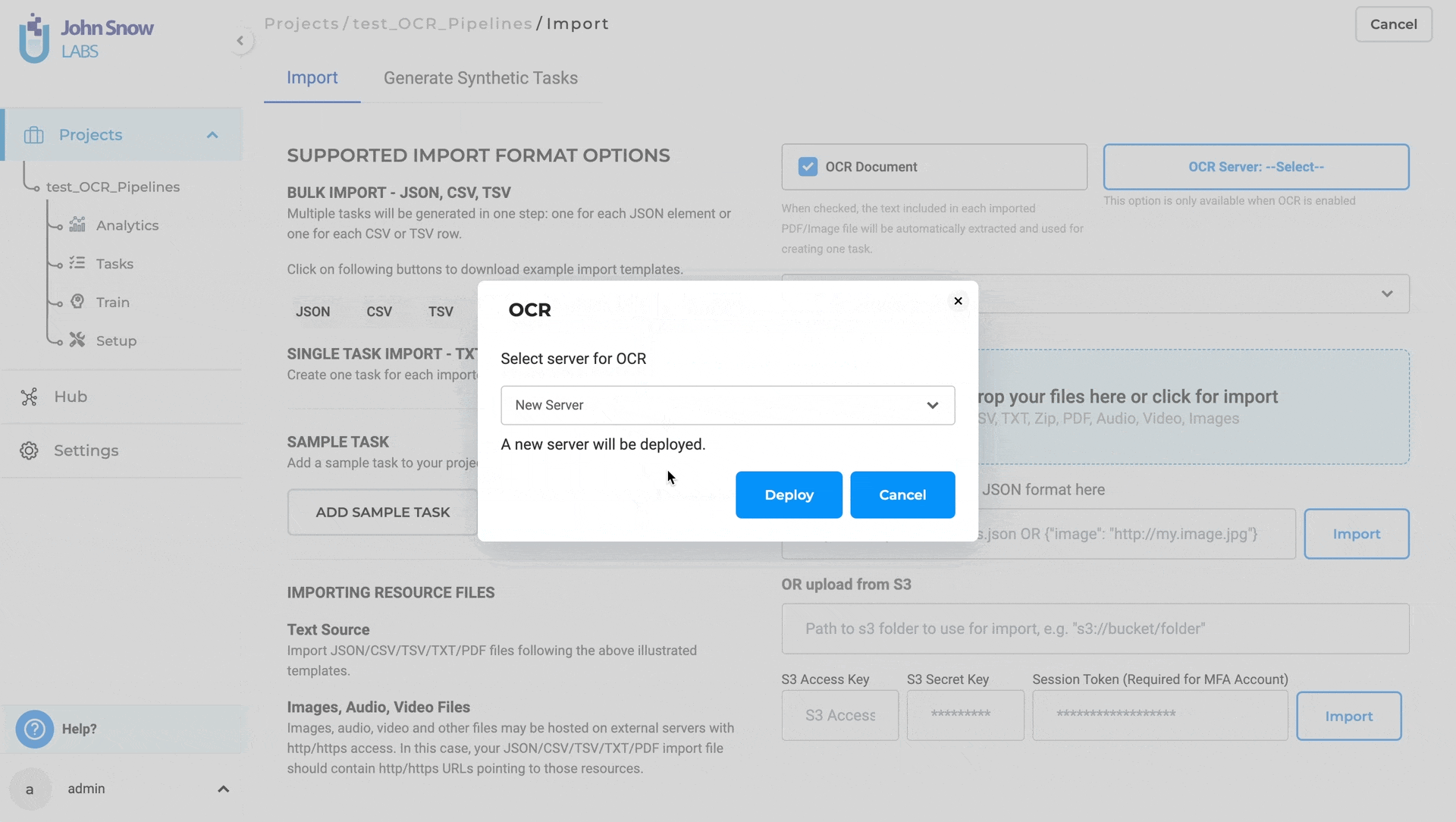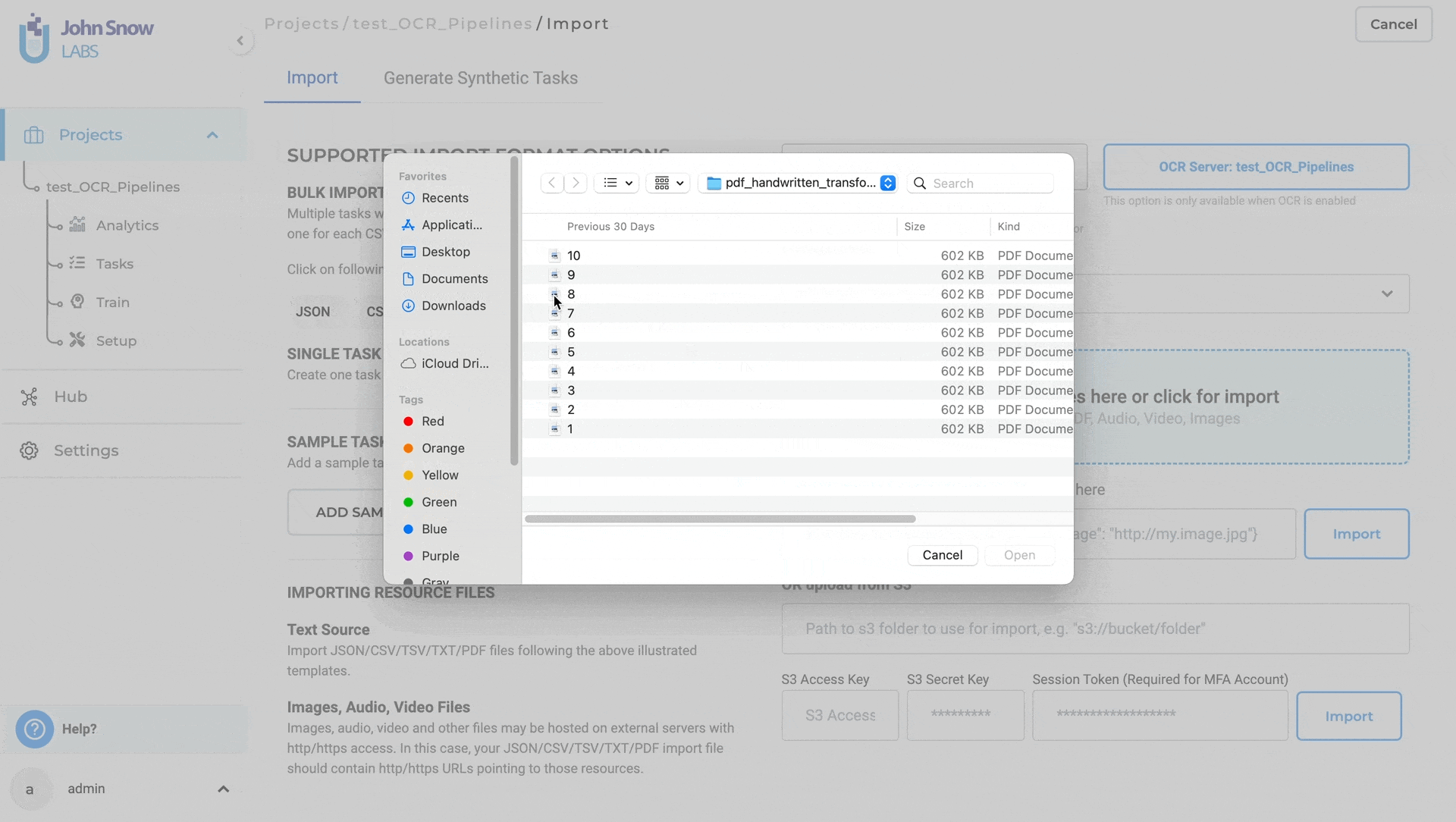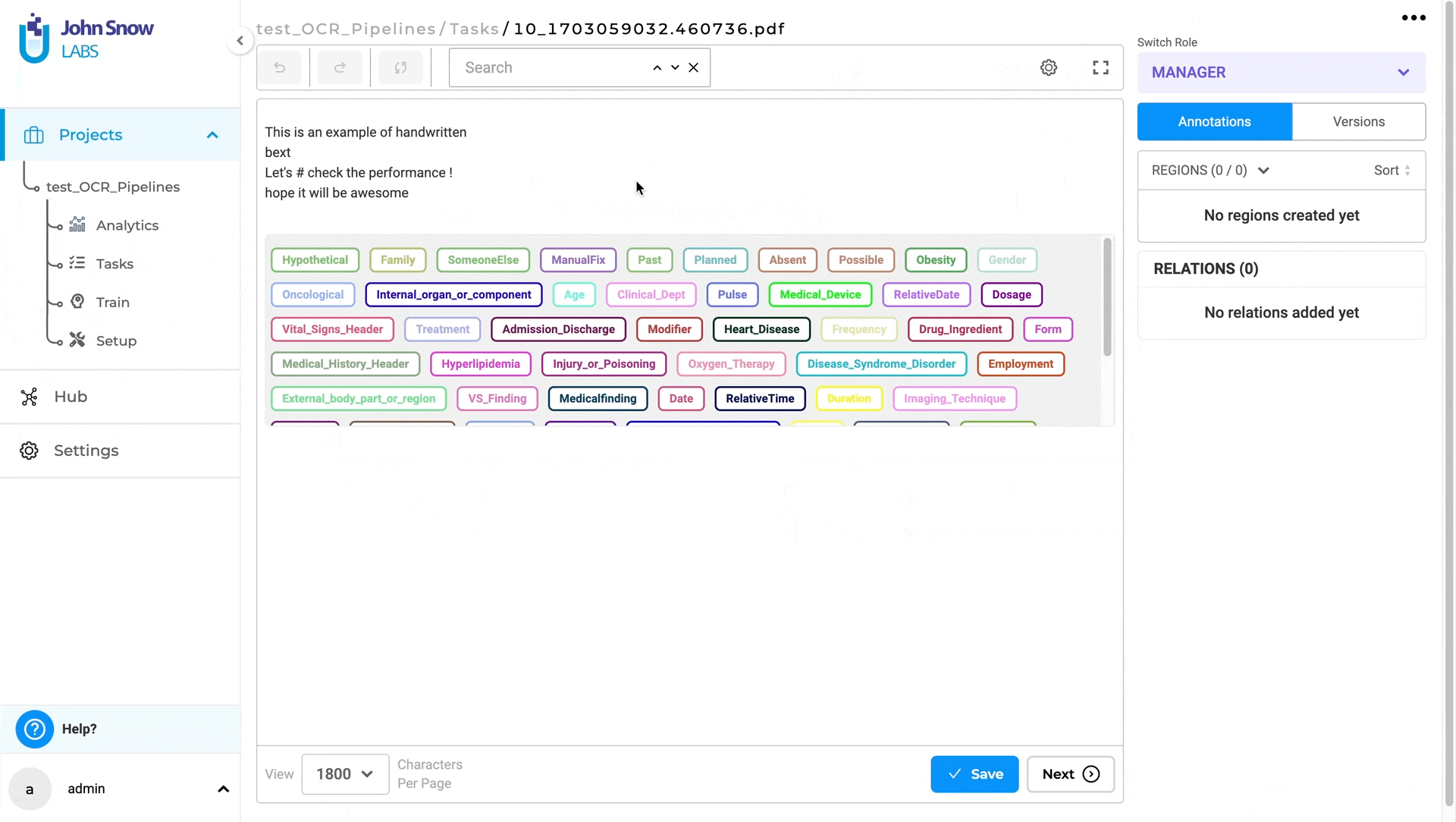
- Activate the “OCR Document” Checkbox and deploy an OCR server.
- Select OCR Pipeline.
- Once the OCR server is ready, choose the desired OCR pipeline from the dropdown menu. This allows you to configure the processing settings for your OCR task.
- Import your OCR files with support for both individual files and multiple files in a zipped format.
Note: Pipelines are automatically downloaded when selected from the import page, even if they haven’t been previously downloaded from the Models Hub. These steps streamline the process of enabling OCR, deploying a server, selecting a pipeline, and importing OCR files, facilitating efficient OCR document handling within the given context.
Current Limitations and Future Optimizations
Currently, task importing via dedicated OCR pipelines may take longer than using the default OCR import option. This aspect is earmarked for optimization in the subsequent releases.
These enhancements aim to improve the user experience in NLP Lab by making it more accessible and powerful. While implementing these improvements, the familiar user interface and core functionalities are retained to ensure a seamless transition for users.
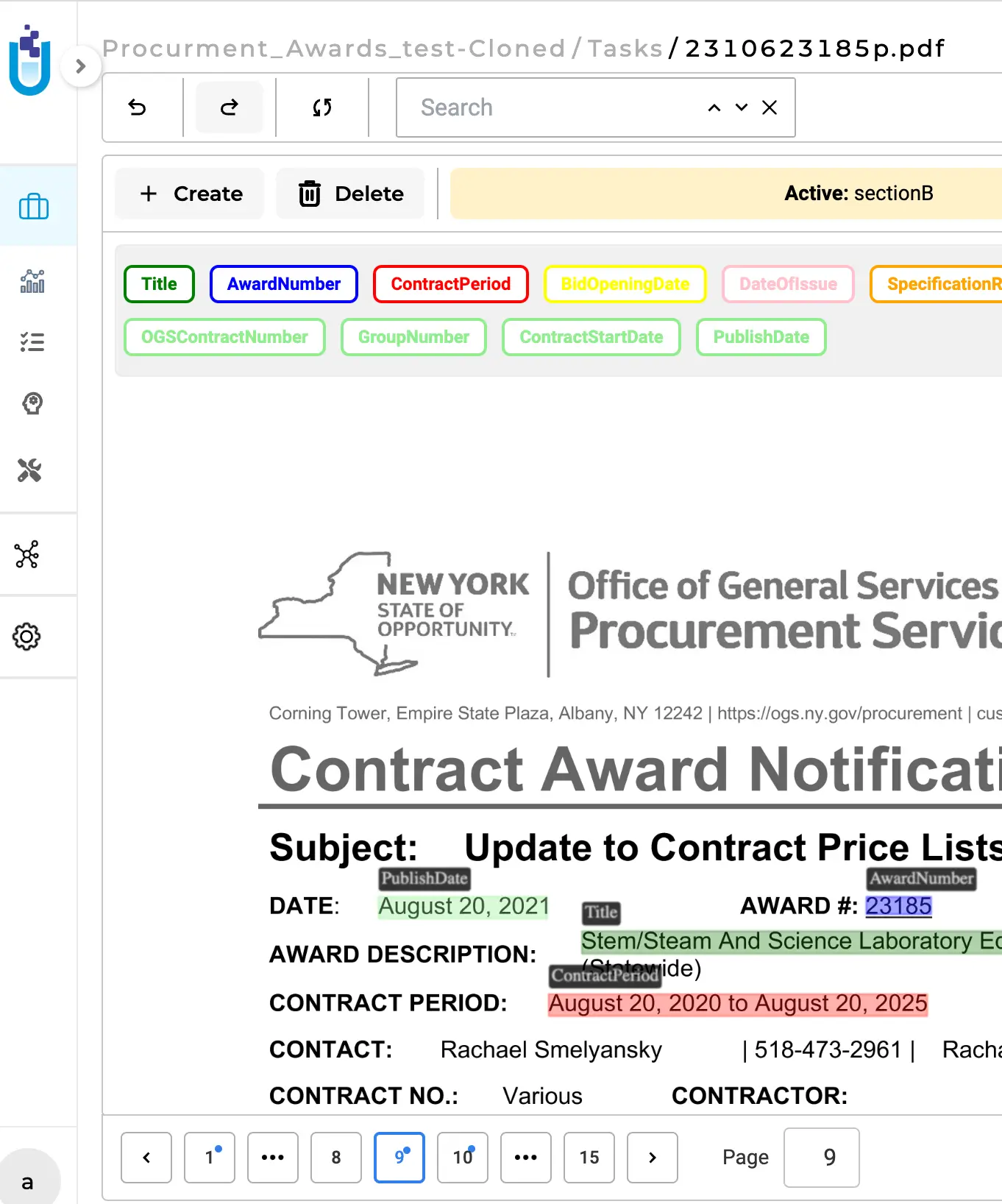
Multi-page Visual NER improvements
Users can now effortlessly locate relevant pages of a multipage document task, simplifying the process of finding relevant information. This improvement allows annotators to swiftly navigate to the next relevant page for the visual Named Entity Recognition (NER) task, eliminating the need to visit each page manually.
Note: when using a section-based configuration project, if a section rule matches and, therefore, a section is identified as a positive match for a specific page of a multipage document or if a user manually assigns a specific page as a relevant section, that page will be designated/identified by the application as a relevant page and visually marked as such. All other pages are considered irrelevant.
Getting Started is Easy
The NLP Lab is a free text annotation tool that can be deployed in a couple of clicks on the AWS, Azure, or OCI Marketplaces or installed on-premise with a one-line Kubernetes script.
Get started here: https://nlp.johnsnowlabs.com/docs/en/alab/install
Start your journey with NLP Lab and experience the future of data analysis and model training today!





