As healthcare organizations increasingly rely on unstructured data like clinical notes, pathology reports, and discharge summaries, de-identifying patient information becomes mission-critical. Whether for research, AI training, or compliance, healthcare providers must ensure Protected Health Information (PHI) is removed at scale and with precision. Two solutions often considered for this task are John Snow Labs’ Medical Text De-identification and Microsoft Presidio. While both are powerful tools for identifying and redacting sensitive data, they serve very different use cases — and their effectiveness in healthcare settings diverges sharply.
As healthcare organizations increasingly rely on unstructured data like clinical notes, pathology reports, and discharge summaries, de-identifying patient information becomes mission-critical. Whether for research, AI training, or compliance, healthcare providers...
In today’s hyper-connected world, every organization is a data company, whether they realize it or not. From hospitals and banks to startups and SaaS platforms, sensitive data flows through every...
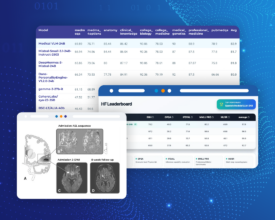
Introduction In the evolving landscape of artificial intelligence for healthcare, John Snow Labs continues to demonstrate exceptional leadership with the release of the very first Medical Vision-Language Model (VLM). This model,...
GLiNER and OpenPipe Shine on General Texts but Miss Over 50% of Clinical PHI — Compared to Less Than 5% Misses by Solutions Like John Snow Labs It’s often assumed...
Why Is the Shift from Knowledge Recall to Clinical Reasoning Crucial in Healthcare AI? John Snow Labs has been at the forefront of healthcare AI, consistently developing state-of-the-art language models...




































































 See More
See More