This article explores the distinctive features, performance benchmarks, and potential applications of this specialized medical AI model, demonstrating how JSL continues to push the boundaries of what's possible in healthcare AI.
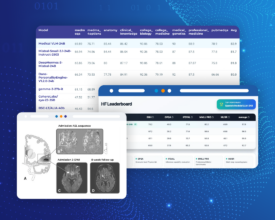
Introduction In the evolving landscape of artificial intelligence for healthcare, John Snow Labs continues to demonstrate exceptional leadership with the release of the very first Medical Vision-Language Model (VLM). This model,...
John Snow Labs, the AI for healthcare company, today announced it has won a 2025 Oracle Customer Excellence Award in the AI category for North America. The Oracle Customer Excellence...
In industries where strict regulatory standards govern operations, achieving full auditability and operational transparency is critical—not optional. Generative AI Lab addresses these critical requirements with a powerful set of enhancements...
Human-in-the-Loop (HITL) validation is critical to ensuring AI model outputs meet the highest standards of accuracy, compliance, and usability. Generative AI Lab is purpose-built to empower annotation teams to validate...
This document compares the core capabilities, strengths, and limitations of OpenAI’s large language models (LLMs) with John Snow Labs’ Medical Terminology Server (TS), focusing on terminology mapping use cases in healthcare...




































































 See More
See More