
























































There’s a quiet crisis in healthcare analytics. Organizations are spending millions on AI models, disease registries, population health programs, and clinical research, and many of them are doing it on fundamentally broken data foundations. Not broken in the way that crashes dashboards. Broken in the way that silently skews results, misclassifies patients, and produces findings that feel credible but aren’t.

Why “good enough” data is costing healthcare researchers, registries, and AI teams far more than they realize
The problem has a name: the clinical data accuracy gap. And it starts with a decision that most teams make without even realizing it.
The Default That’s Sabotaging Healthcare Analytics
When a research team, registry program, or AI initiative spins up, they almost always do the same thing: pull from structured EHR fields. Diagnosis codes, medication lists, procedure codes, lab results. It’s organized, queryable, and familiar. It also represents a surprisingly small slice of what clinicians actually document.
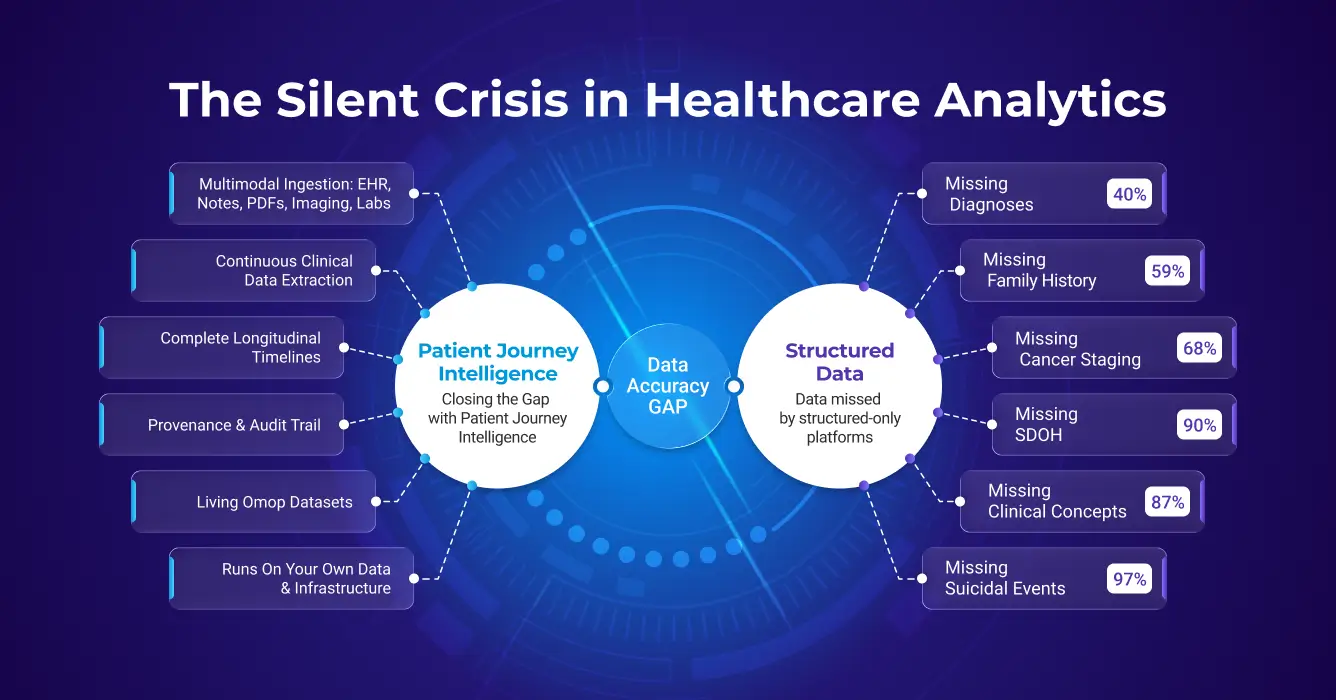
Here’s what the peer-reviewed literature tells us about what structured data is missing:
Diagnoses: Close to 40% of clinically important inpatient diagnoses appear only in free-text notes, never making it to a structured problem list. Run a cohort query on structured codes alone and you could be excluding nearly half the patients who actually have the condition you’re studying.
Family history: Clinicians document family history in unstructured notes for roughly 59% of patients. Structured fields? Around 5%. That’s a 12-fold gap, and it makes genetics studies and risk models built on structured family history almost systematically unreliable.
Social determinants of health: Models that analyze clinical notes can identify over 90% of patients facing housing insecurity, food insecurity, or transportation barriers. ICD code-based approaches? A small minority. Social factors are extensively documented in notes, but they are literally invisible to structured queries.
Oncology: Cancer staging data is missing from structured EHR fields in more than 68% of encounters. Biomarker data, ER/PR/HER2 status, gene mutations, PD-L1 expression, often isn’t in structured fields at all, despite being routinely documented in pathology reports and oncology notes.
Medications: Between 60% and 70% of medication histories contain at least one error. Over 90% of patients have at least one discrepancy between their structured medication list and what’s documented in clinical notes and discharge summaries.
Suicidality: Only 3% of patients with documented suicidal ideation and 19% with documented suicide attempts have a matching ICD code. Structured surveillance systems are effectively blind to more than 80% of documented high-risk psychiatric events.
And perhaps the most striking number of all: 87% of clinical concepts extracted from patient records have no matching structured counterpart. The information exists, it’s just locked in free text.
This is the structured-only trap. And most secondary use platforms are stuck inside it.
Why This Happens and Why It Persists
It’s not that research teams don’t know clinical notes matter. It’s that extracting and integrating unstructured text, across decades of patient encounters, multiple EHR systems, scanned PDFs, imaging metadata, and specialty databases, is genuinely hard and expensive to do well.
So, teams scope to what’s tractable. Structured EHR data. Maybe some claims. The result is a patient representation that’s incomplete by construction, even before a single analysis runs.
The irony is that structured codes were designed for billing and administrative classification, not clinical nuance. A diagnosis code for “diabetes” tells you nothing about glycemic control, medication adherence, disease trajectory, or complications. Clinical notes say things like: “HbA1c 11.2%, poorly controlled, recurrent DKA admissions, non-adherent to insulin.” That’s where the actual signal for outcomes lives. And it’s inaccessible if your data pipeline stops at structured fields.
How Secondary Use Platforms Stack Up and Where They Fall Short
A handful of major platforms have tried to solve the secondary use problem at scale. They each bring real value, and they each have meaningful limitations when it comes to data accuracy.
TriNetX’s federated model gives researchers real-time access to EHR data across 220+ healthcare organizations globally, with participating institutions harmonizing their data to TriNetX’s common model. For federated cohort queries, that’s genuinely powerful. TriNetX also offers an NLP add-on service, available since 2017, that extracts clinical facts from physician notes, radiology reports, and discharge summaries, with negation handling and mapping to standard terminologies. However, this NLP capability is a supplementary service applied within TriNetX’s own federated environment, not a reusable pipeline you own or control.
The limitation: TriNetX solves federated access to network data. The pipeline fragmentation problem within your own institution, across your own systems, for your own internal analytics, registries, and AI programs, remains yours to solve.
Flatiron is arguably the most rigorous oncology-specific real-world data platform in the market. It combines structured EHR data with manual and semi-automated abstraction from clinical notes, pathology reports, and other sources, specifically for cancer care. The resulting datasets have strong biomarker, staging, and treatment data for oncology use cases.
The tradeoff is scope and scalability. Flatiron’s curation model is expensive and fundamentally labor-intensive; it works well for specific oncology indications where manual abstraction is worth the investment, but doesn’t scale to a full enterprise-wide secondary use foundation. And outside oncology, Flatiron isn’t the right fit.
IQVIA is the largest real-world data company in the world by any meaningful measure: 88,000 employees, operations in over 100 countries, $16 billion in annual revenue, and one of the most extensive RWD assets ever assembled. Their E360 Real World Data Platform brings together over one billion de-identified patient records spanning claims, EHRs, patient registries, and specialty datasets into a single self-service analytics environment for epidemiology, outcomes research, and clinical development. For global life sciences organizations, IQVIA’s scale, geographic breadth, and end-to-end service model, from clinical trial design through commercialization, is unmatched.
IQVIA has also invested meaningfully in NLP and healthcare AI. Their healthcare-grade AI positioning emphasizes text mining and NLP integration across their evidence-generation workflows, and a 2025 partnership with NVIDIA positions them to accelerate domain-specific AI agents across literature synthesis, clinical data review, and site identification.
Where the accuracy gap analysis applies is familiar: IQVIA’s E360 platform, like most large federated RWD systems, is primarily built on claims and structured EHR data harmonized to standard terminologies. NLP enrichment exists as a service layer and through curated therapeutic-area datasets, but it is applied to IQVIA’s proprietary global dataset rather than deployed as an enterprise capability on your institution’s own records. The platform is designed to answer sponsored research questions on IQVIA data, not to transform a health system’s fragmented internal data into a continuously updated, multimodal secondary use foundation with full provenance. For organizations that need the latter, an in-house capability that enriches their own patient records, maintains living longitudinal timelines, and supports internal registries, AI development, and quality programs, IQVIA’s model is a data access relationship, not a data infrastructure solution.
Komodo Health, Healthcare Map & MapLab
Komodo Health operates what it calls the Healthcare Map, a longitudinal, de-identified dataset covering 330+ million U.S. patient journeys, built primarily from a large open- and closed-claims foundation. Komodo’s strength is breadth and speed. Accessing 330 million de-identified patient journeys with pre-built analytics templates is a genuine differentiator for commercial life sciences teams doing Health Economics and Outcomes Research (HEOR), disease burden analysis, treatment pattern research, and market analytics. The conversational AI layer (MapAI) makes exploratory querying accessible to non-technical users.
The limitation from a data accuracy standpoint is the same one that affects all claims-first platforms: insurance claims data was designed for billing, not clinical documentation. Claims records don’t capture what’s in clinical notes, the staging details, the biomarker results, the family history, the social determinants, the clinician’s reasoning. MapEnhance can link in EHR and lab data from third parties, but this is additive enrichment on a claims foundation, not deep NLP extraction from your institution’s own unstructured records. Additionally, because Komodo’s data is a licensed external dataset rather than your organization’s own patient records, it’s well-suited for life sciences research and market intelligence but less suited for internal clinical operations, registry automation, or AI model development on your own institutional data.
Merative (formerly IBM Watson Health, spun out in 2022) is home to one of the oldest and most cited real-world data assets in healthcare research: the MarketScan Research Databases, covering more than 250 million de-identified patient lives built from commercial insurance claims spanning over four decades. For HEOR teams, epidemiologists, and health economists studying treatment patterns, utilization, and costs across a commercially insured US population, MarketScan is a workhorse, trusted, longitudinal, and backed by deep methodological expertise.
The accuracy ceiling is clearly defined and, to Merative’s credit, openly documented. MarketScan is a pure claims database. Clinical notes are explicitly not available. Researchers work entirely with billing codes, diagnosis, procedure, and pharmacy claims, which means the full scope of the accuracy gap described in this post applies directly: no cancer staging, no family history, no SDOH, no symptom severity, no clinician reasoning, no negation handling. Stanford’s own MarketScan documentation flags it plainly: tumor stage, remission status, and other clinically rich data simply cannot be obtained from administrative claims. It’s a powerful tool for what it is, but what it is doesn’t include the 87% of clinical concepts that live in unstructured text.
Optum (part of UnitedHealth Group) is arguably the most sophisticated player in the commercial RWD space when it comes to acknowledging and partially addressing the unstructured data problem. Their Optum Labs Data Warehouse covers 300+ million de-identified lives combining commercial claims, Medicare FFS, EHR-derived data, and socioeconomic data. Crucially, Optum has invested in proprietary NLP capabilities: their Enriched Clinical Data products use NLP to extract disease-specific insights from clinical notes and radiology reports, and their Clinical Notes Lab gives researchers direct access to de-identified unstructured notes for their own model development.
This makes Optum a meaningfully different comparison than the others. They understand the problem, have built tooling around it, and offer NLP-enriched research cohorts for specific therapeutic areas. For life sciences companies conducting sponsored research with Optum’s datasets, this is a genuine differentiator over pure claims platforms.
The key limitations, however, are important to understand. Optum’s NLP is applied to their own proprietary licensed dataset, it is not deployed on your institution’s data. The enriched cohorts are disease-specific and research-ready, meaning Optum’s team has pre-processed them; you receive an output, not the underlying enrichment infrastructure. Standard terminology normalization (SNOMED CT, full RxNorm coverage), ML-based conflict resolution, comprehensive longitudinal timeline construction with assertion status, full provenance lineage down to source document, and continuous living updates on your own data are not part of what’s offered.
Veradigm (formerly part of Allscripts) is one of the more interesting comparisons in this space because, like Optum, they have made genuine investments in NLP — and are worth taking seriously on the unstructured data problem. Their Veradigm Network EHR Data covers 154 million de-identified patients drawn from 80+ ambulatory EHR systems, with a five-year longitudinal span across geographically and demographically diverse U.S. practices. Crucially, Veradigm applies proprietary NLP models across five billion clinical notes to extract structured clinical facts from unstructured text, reporting accuracy rates of 93% and higher. Their RWE Analytics Platform follows OMOP CDM standards, and they offer therapeutic-area-specific NLP-enriched cohorts covering cardiovascular, metabolic, immunology, and CNS indications.
For life sciences organizations doing sponsored research, Veradigm occupies a meaningful niche: more NLP depth than a pure claims vendor, focused specifically on the ambulatory primary care and specialty setting that often gets underrepresented in hospital-centric datasets.
The limitations are structurally similar to Optum’s. Veradigm’s NLP is applied to their own dataset — it is not a capability you deploy on your institution’s data. The enriched cohorts are pre-built for specific therapeutic areas; bespoke extraction outside those areas requires engaging Veradigm’s services team. The dataset is ambulatory-only, meaning inpatient encounters, hospital discharge summaries, and acute care records are not the core of the asset — a meaningful gap for conditions requiring inpatient context. And the same platform-vs-vendor distinction applies: Veradigm delivers enriched data products; they do not provide the infrastructure for a health system to build its own continuously updated, multimodal secondary use foundation with full provenance and living datasets.
Palantir Foundry occupies a distinct position in this landscape: it’s not a data vendor like TriNetX or Komodo, but a general-purpose data integration and AI platform that large health systems, government agencies, and life sciences organizations deploy on top of their own data. Its client list in healthcare is formidable, the NHS, the VA, CDC, NIH, Cleveland Clinic, Tampa General, and Pfizer, among them. Foundry’s ontology-driven architecture is purpose-built for unifying siloed data sources, and its AIP layer increasingly brings LLM-powered workflows to enterprise operations.
Where Foundry excels is as an integration and operational layer: connecting disparate systems, modeling data relationships, enabling governed self-service analytics, and building custom AI applications at scale. For organizations with strong data engineering teams that want a flexible platform to build on, it’s compelling.
The limitation from a secondary use accuracy standpoint is that Foundry is fundamentally a platform, not a pre-built clinical NLP/LLM enrichment engine. It can ingest and store unstructured clinical documents, and its semantic search can surface relevant text, but extracting structured clinical facts from notes with healthcare-grade precision (negation detection, assertion status, temporal reasoning, SNOMED normalization, entity deduplication) requires building that capability on top of Foundry, typically from scratch, using custom NLP pipelines. There is no out-of-the-box medical language model for clinical entity extraction, no automated terminology normalization to SNOMED CT or RxNorm, and no pre-built de-identification module. Every organization deploying Foundry for clinical secondary use must solve those problems itself, which is exactly the kind of per-project data accuracy work that a purpose-built platform like Patient Journey Intelligence is designed to eliminate.
PCORnet / i2b2 / OHDSI (OMOP CDM)
These are open, community-governed data standards and networks rather than commercial products. PCORnet harmonizes patient data across a large distributed research network. i2b2 is a widely deployed query framework for institutional clinical data repositories. OMOP CDM (the common data model underlying OHDSI) has become a de facto standard for observational research.
All of these provide powerful frameworks for structured data federation and research collaboration. But they share a core limitation: they are data standards and query infrastructure, not data enrichment engines. They don’t extract clinical facts from unstructured notes, normalize entity mentions to standard vocabularies from free text, or maintain living, continuously updated patient timelines with full provenance. Organizations building on these frameworks still need to solve the unstructured data problem separately, or accept the accuracy gap.
What Actually Closing the Accuracy Gap Requires
If you look at where structured-only approaches fail, a clear picture emerges of what a real solution needs to do. It’s not just about having more data, it’s about fundamentally changing how raw clinical data gets transformed into something trustworthy enough to build on.
Eight things are genuinely non-negotiable:
- Multimodal ingestion. Structured EHR fields, clinical notes, scanned PDFs, imaging metadata, labs, medications, procedures, claims, all of it, not just the easy parts.
- Healthcare-specific NLP. General-purpose language models fail on clinical text. Medical NLP that understands negation (“no evidence of”), uncertainty (“possible PE”), assertion status (confirmed vs. ruled-out vs. family history), and temporal reasoning achieves 85–95% precision on clinical extraction tasks, roughly 30% better than general AI tools on the same work.
- Terminology standardization. Every clinical concept is mapped to SNOMED CT, RxNorm, LOINC, and ICD-10-CM. Without this, the same condition appears in dozens of surface forms across systems, making accurate patient counts and cross-institutional research impossible.
- Clinical reasoning and conflict resolution. Real patient records are messy. The same patient may have conflicting documentation across systems. Intelligent deduplication, conflict resolution, and confidence scoring are required to produce a clean representation.
- Longitudinal timelines. Clinical questions are almost always time-dependent. Systems need to answer “when”, disease progression, treatment response, and time-to-event outcomes. Chronologically organized patient timelines with precise temporal context are essential.
- De-identification at 99%+ accuracy. Most secondary use requires removing PHI. Manual approaches are slow and error-prone. Automated, HIPAA-compliant de-identification using medical-specific models is the only scalable path.
- Provenance and auditability. Every derived clinical fact needs a traceable lineage back to the source document, with confidence scores and drill-down to supporting evidence. Regulatory compliance and research reproducibility depend on it.
- Continuous, living updates. Static snapshots go stale. Clinical data accumulates continuously. Patient journeys need to update automatically as new data arrives, so analytics and AI applications always operate on current information.
How Patient Journey Intelligence Addresses Each of These
Patient Journey Intelligence from John Snow Labs was built specifically to close this accuracy gap, not as a one-off research pipeline, but as a shared enterprise foundation that every downstream use case can build on.
Rather than each registry program, research team, or AI initiative solving the same data accuracy problems independently, Patient Journey Intelligence provides a single platform that ingests multimodal clinical data, extracts structured facts from unstructured text using healthcare-specific NLP, normalizes all concepts to standard vocabularies, reasons about conflicts and assertion status, and maintains living patient journeys with complete provenance.
Concretely:
- Multimodal clinical data integration across structured EHR fields, clinical notes, scanned PDFs, FHIR resources, imaging metadata, and claims through a unified pipeline
- Medical language models that extract diagnoses, medications, and clinical findings with 85–95% precision, including detection of negation, uncertainty, and temporal relationships
- Full vocabulary normalization to SNOMED CT, RxNorm, LOINC, ICD-10-CM, etc., enabling accurate patient counts and cross-institutional consistency
- AI-based conflict resolution with entity deduplication and distinction between confirmed diagnoses and ruled-out conditions
- Chronological patient timelines with temporal context for visits, diagnosis, procedures, medications, conditions, or clinical measures
- 99%+ accurate de-identification compliant with HIPAA and GDPR, with parallel identified and de-identified datasets kept semantically synchronized
- Complete lineage tracking from source document to OMOP representation, with confidence scores and audit trails supporting HIPAA requirements
- Continuous updates that keep patient journeys current as new data arrives, not quarterly snapshots that are obsolete before they’re analyzed
The result: instead of missing 40% of diagnoses, 81% of suicidality events, and 68% of cancer staging data, organizations build on patient representations that capture what actually happened, across all modalities, continuously updated, with full provenance.
👉 See here exactly how PATIENT JOURNEY INTELLIGENCE addresses the clinical data accuracy gap.
The Real Cost of Accepting the Clinical Data Accuracy Gap
Here’s the thing about the clinical data accuracy gap: it’s invisible until it isn’t. Cohorts look plausible. Models produce outputs. Registries submit their data. Everything appears to be working. The problem surfaces later, when a model trained on 60% complete patient records makes predictions that don’t hold up in validation, when a registry audit reveals systematic underreporting, when a payer questions cohort methodology that excluded half the qualifying patients.
The organizations winning in secondary use aren’t necessarily those with the most data. They’re the ones who’ve stopped treating data quality as something to fix later and started building it into the foundation.
The math is actually compelling. Right now, most secondary use initiatives spend roughly 80% of their effort on data wrangling for each new project. A proper data foundation flips that: 10% on integration (once) and 90% on the actual science, continuously, across every use case that follows.
Top 10 Secondary Use Data Platforms – Comparison Summary
| Capability | Structured EHR / claims data | Unstructured NLP extraction | Multimodal ingestion (PDFs, imaging) | Continuous living updates | Full provenance & auditability | 99%+ de-identification | Clinical conflict resolution | Longitudinal timeline completeness | Runs on your own institutional data | Primary use case |
|---|---|---|---|---|---|---|---|---|---|---|
| Patient Journey Intelligence |
 Strong |
Healthcare-specific NLP |
|
Automated |
End-to-end lineage |
|
ML-based |
96% completeness |
|
Secondary use platform for clinical data |
| TriNetX |
Strong |
 Limited |
 |
Network-dependent |
Partial |
|
|
Structured + targeted extractions from selected documents |
|
Clinical trial feasibility, epidemiology |
| Flatiron Health |
Strong |
Manual Oncology only |
Oncology – specific |
Manual refresh |
Partial |
|
Manual |
Oncology-scoped |
|
Oncology RWE |
| IQVIA E360 |
Strong (1B+ records globally) |
NLP service layer, Curated datasets |
Partial |
Periodic |
Partial |
|
|
Structured/claims-primary |
|
Global RWE, clinical development, commercialization |
| Komodo Health |
Claims-first, EHR via MapEnhance |
Not core capability |
Third-party linkage only |
Daily refresh |
Partial |
|
|
Claims only |
|
HEOR, commercial analytics |
| Merative MarketScan |
Claims only |
None |
|
Annual releases |
|
|
|
Claims only |
|
Payer/employer HEOR, cost research |
| Optum |
Strong Claims + EHR |
Disease-specific, Optum data only |
Partial |
Periodic |
Partial |
|
|
EHR + claims, NLP partial |
|
Life sciences RWE, NLP-enriched cohorts |
| Veradigm |
Strong Ambulatory EHR |
Veradigm data only, 93%+ accuracy |
OCR on faxes / attachment |
Periodic |
Partial |
|
|
Ambulatory EHR, NLP-enriched |
|
Ambulatory RWE, NLP-enriched EHR research |
| Palantir Foundry |
Strong |
Build-your-own pipelines |
Ingestion yes, extraction no |
Configurable pipelines |
Strong ontology lineage |
Custom implementation required |
|
Depends on custom build |
|
Data integration & AI operations |
| PCORnet / OHDSI |
Strong |
Not included |
|
Varies |
Varies |
Varies |
|
Structured only |
|
Observational research framework |
The Data Accuracy Gap Is Costing Your Research More Than You Know
Secondary use of clinical data has transformative potential for research, for population health, for AI, for registries, for drug development. But that potential is only realized if the data actually represents what happened to patients.
The clinical data accuracy gap isn’t a minor data quality issue. It’s a systematic problem that causes secondary use applications to miss nearly half of diagnoses, the vast majority of psychiatric risk signals, most cancer staging data, and over 90% of social determinants. Projects built on these incomplete foundations don’t just produce partial answers; they often produce wrong ones.
The platforms that have dominated secondary use to date: IQVIA, TriNetX, Flatiron, Komodo Health, Merative, Optum, Veradigm, PCORnet, OHDSI, and Palantir Foundry; each solves important problems. But they leave the core accuracy gap largely unaddressed. TriNetX, PCORnet/OHDSI, and Merative MarketScan focus on structured or claims-only data. Flatiron adds manual abstraction for oncology only. Komodo and IQVIA offer powerful longitudinal views at enormous scale, but are primarily structured and claims-primary in their foundations. Optum and Veradigm go furthest with NLP-enriched cohorts, but both apply that capability to their own licensed datasets rather than yours, in specific disease areas, without full provenance, clinical conflict resolution, or living updates on your institutional data. Palantir Foundry is a genuinely powerful integration platform, but clinical NLP, terminology normalization, and de-identification all have to be custom-built on top.
Patient Journey Intelligence was designed from the ground up to close that gap, for any therapeutic area, at enterprise scale, as a shared foundation that every downstream use case can build on, once.
👉 Ready to understand the full scope of what you might be missing? Read the complete technical breakdown of the data accuracy gap at Patient Journey Intelligence.
Patient Journey Intelligence is a platform from John Snow Labs, the AI company powering healthcare’s most complex language understanding challenges. Learn more at johnsnowlabs.com.



