
























































Natural Language Processing (NLP) is changing the way the legal sector operates. According to a report, the NLP market size is expected to reach $27.6 billion by 2026.
 Organizing documents, and looking for specific information in huge amounts of documents can be frustrating for lawyers and their clients. NLP understands and predicts law, converts unstructured text into a meaningful format that computers can understand and analyze. It streamlines and improves legal work, extracts insights from legal documents, and supports legal decision-making.
Organizing documents, and looking for specific information in huge amounts of documents can be frustrating for lawyers and their clients. NLP understands and predicts law, converts unstructured text into a meaningful format that computers can understand and analyze. It streamlines and improves legal work, extracts insights from legal documents, and supports legal decision-making.
Significance of NLP in Legal industry
Legal research is the method of identifying and retrieving information necessary to support decision making. The basic steps involved in legal research are:
- Gathering the facts and identifying the legal issue
- Finding primary sources of law to support the legal argument
- Confirming that the laws used as reference are relevant
It takes so long to conduct thorough research for legal processes. Natural Language Processing shortens the timelines and streamlines the research process. It searches for specific keywords, and helps lawyers make decisions faster.
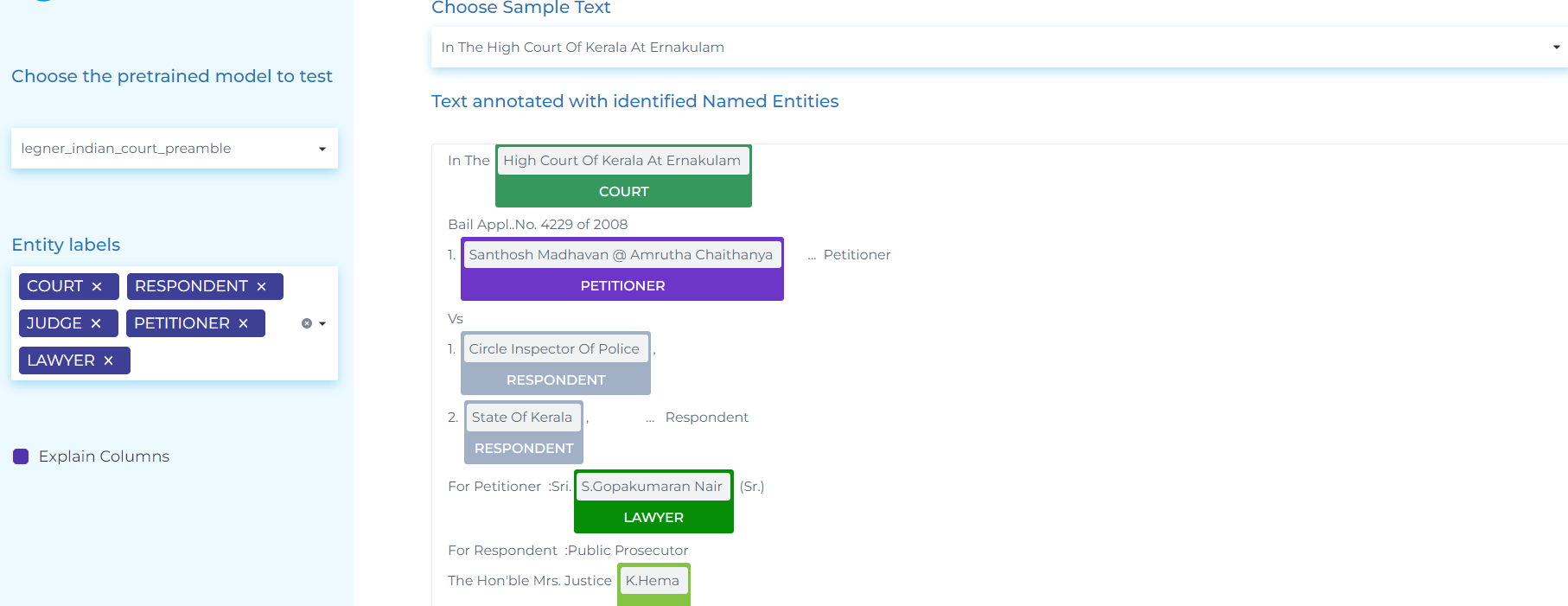
 NLP can automatically identify and extract important named entities from legal documents, such as parties, locations, and dates. This can be useful in tasks such as contract analysis, due diligence, and document retrieval. NLP can analyze the sentiment or tone of legal documents, such as court opinions or briefs. This can help lawyers understand the attitudes of judges or opposing counsel, identify key arguments, and make more informed strategic decisions.
NLP can automatically identify and extract important named entities from legal documents, such as parties, locations, and dates. This can be useful in tasks such as contract analysis, due diligence, and document retrieval. NLP can analyze the sentiment or tone of legal documents, such as court opinions or briefs. This can help lawyers understand the attitudes of judges or opposing counsel, identify key arguments, and make more informed strategic decisions.
NLP also helps lawyers avoid errors while document drafting, and protects their reputation and clients. It provides the following benefits:
- Understands and drafts contracts
- Ensures accurate word choice and syntax
- Creates templates based on a given agreement/law
- Saves lawyers’ time

Recognizing Legal Entities with Legal NLP
NLP recognizes various legal entities and directs researchers to where specific phrases appear in lengthy court decisions. By recognizing entities, the attorneys can quickly decide which cases are not relevant, and move on to the next case.
Named Entity Recognition
Named Entity Recognition is an NLP technique used to identify and classify named entities in unstructured text. It is also called Entity Extraction, Chunking, or Identification. An entity refers to a word or a series of words that refers to the same thing. In the legal domain, named entities of interest can include:
- Judges
- Case parties
- Case numbers
- Court names
- References to laws, etc.
NER Working
The NER model works by:
- Detecting a named entity
- Categorizing the entity
The first step detects a word/string of words that form an entity. The second step classifies the entities based on categories. For instance, people, organization, location, time, etc., are entity categories.
NER Main Tasks
The notable tasks of NER in the Legal space are given below.
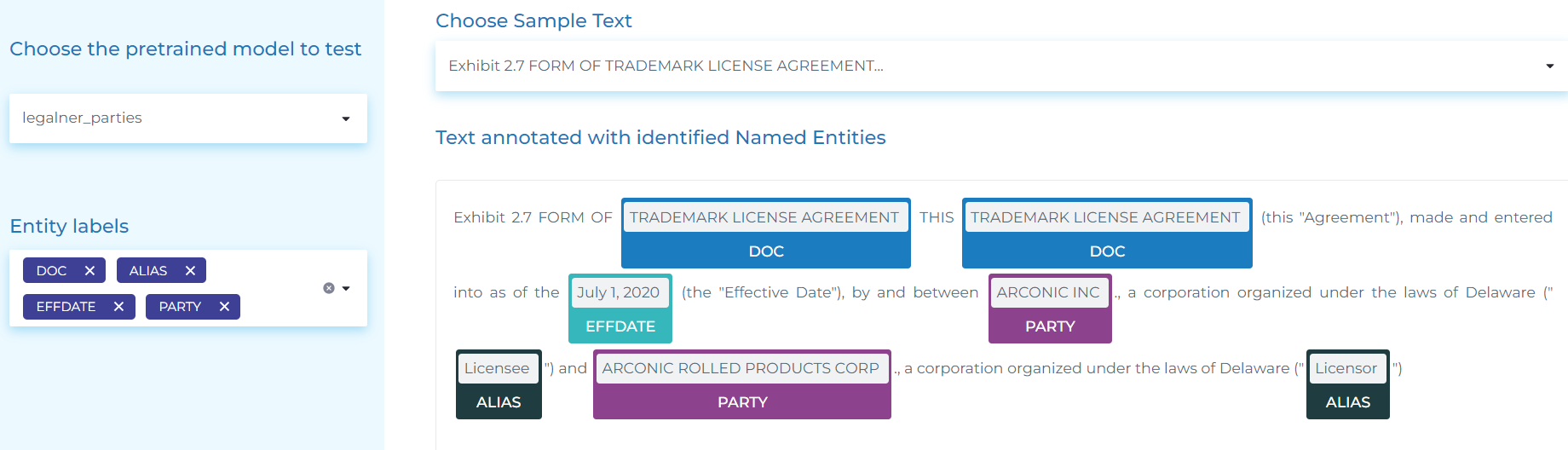
- Extracting DOC (Document Type), PARTY (An Entity signing a contract), ALIAS (the way a company is named later on in the document) and EFFDATE (Effective Date of the contract).

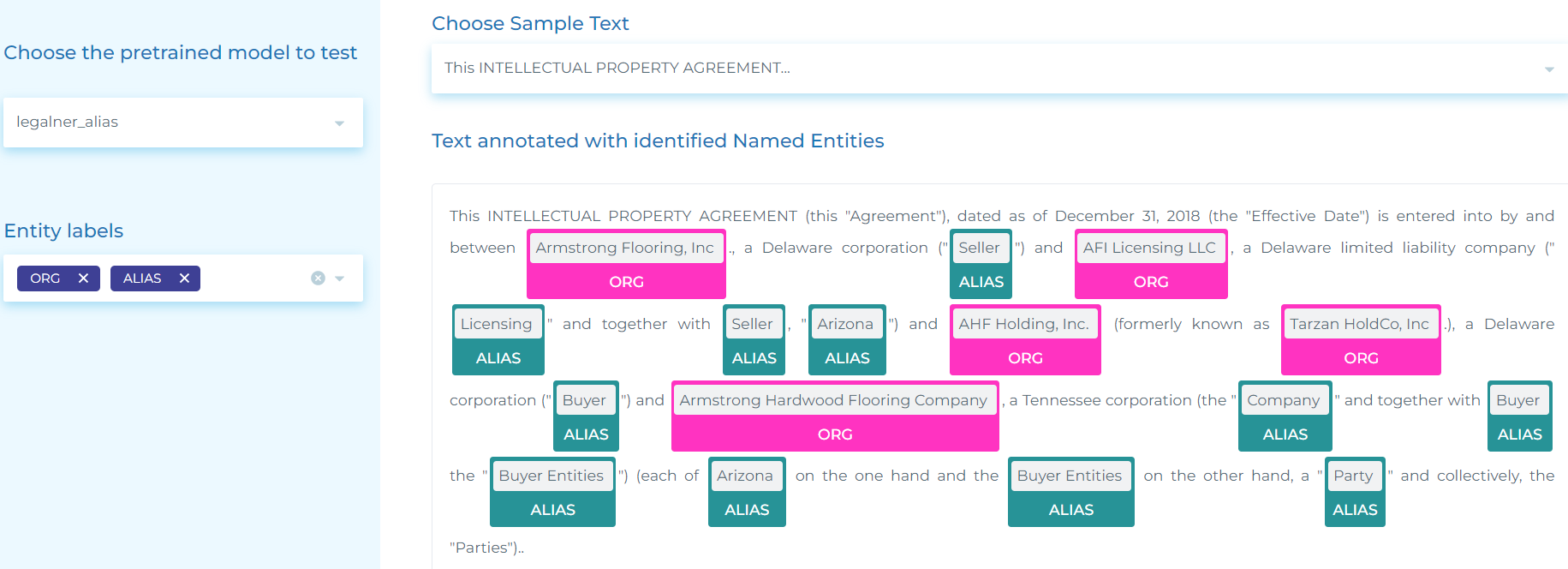
- Identifying ORG (Companies), their ALIAS (other names the company uses in the contract/agreement) and company PRODUCTS.

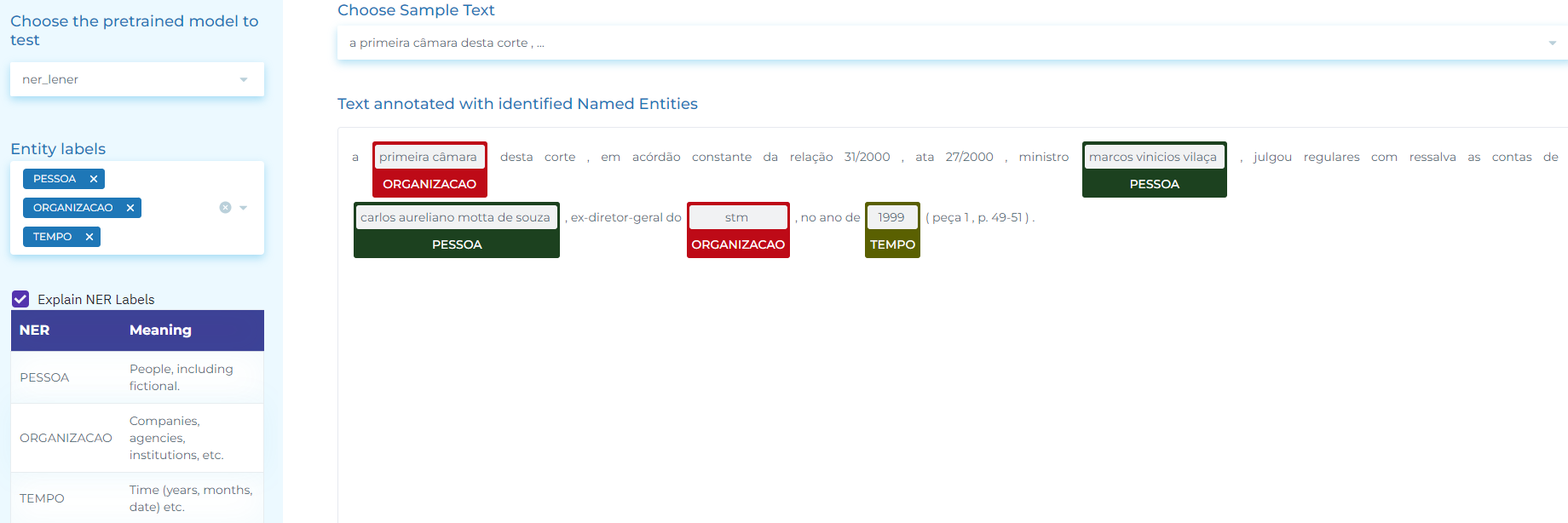
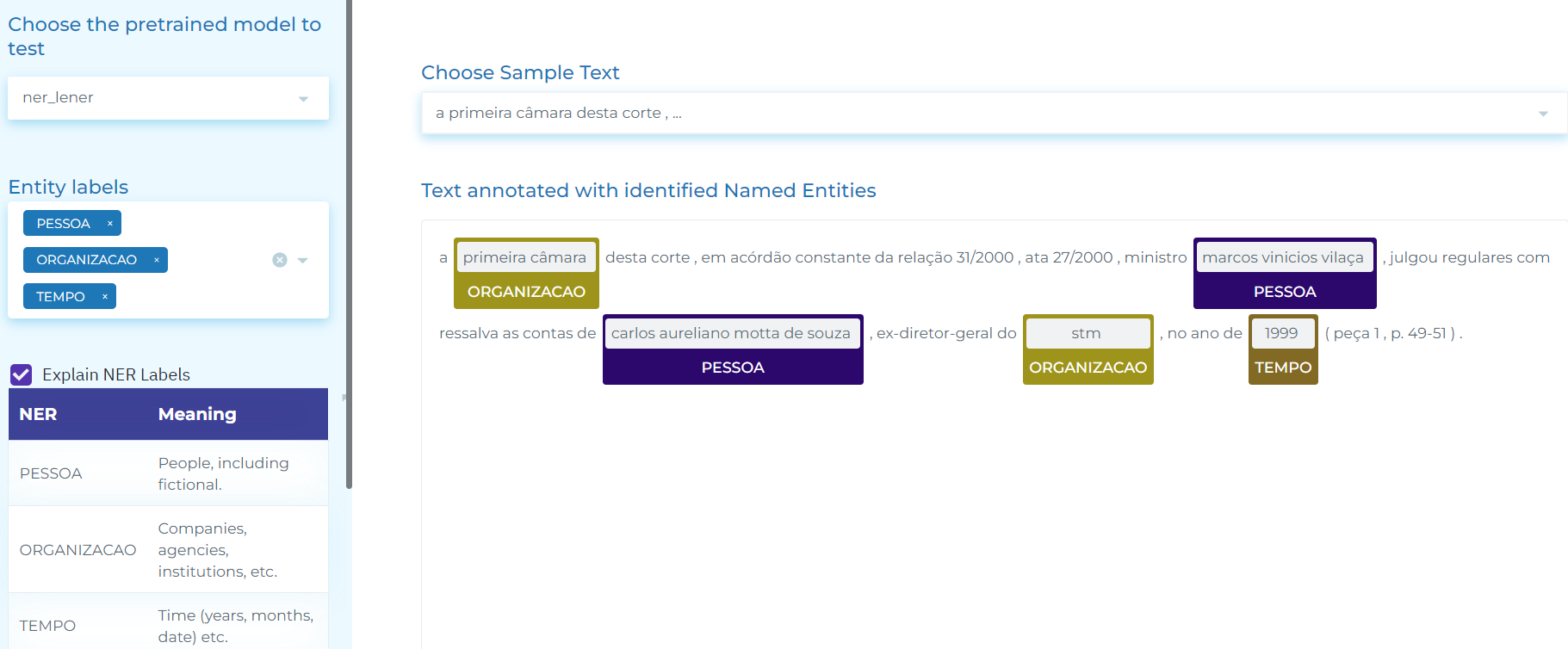
- Automatically identifying entities such as Organization, Jurisprudence, Legislation, Person, Location, and Time, etc. in (Brazilian) Portuguese legal text.

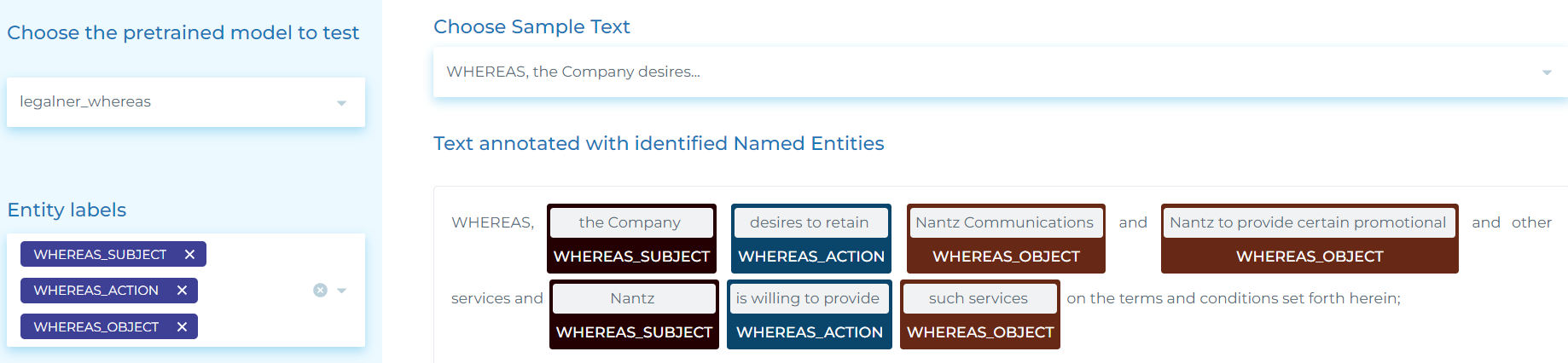
- Detecting “Whereas” clauses and extract, from them, the SUBJECT, the ACTION and the OBJECT.

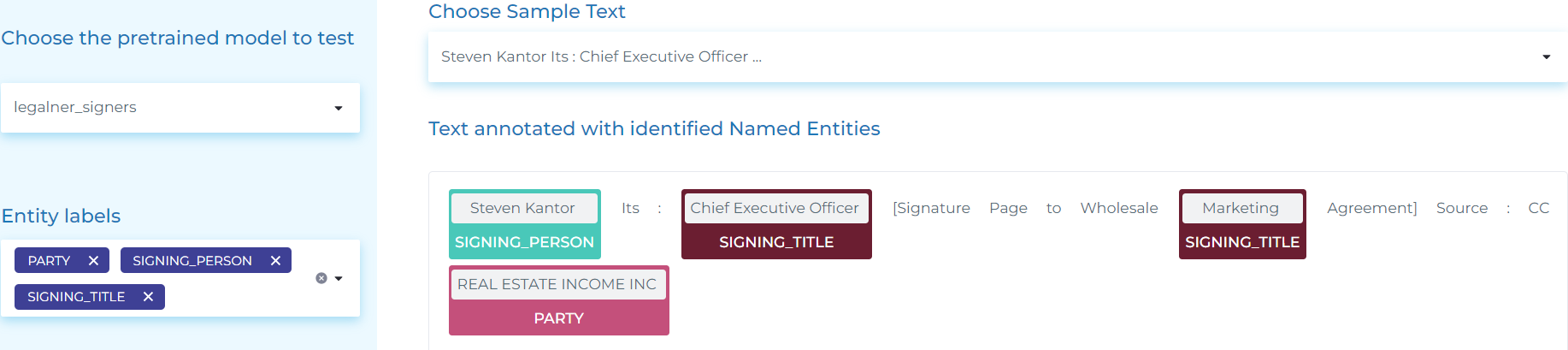
- Extracting SIGNING_PERSON (People signing a document), SIGNING_TITLE (the roles of those people in the company) and PARTY (Organizations).

- Detecting legal entities in German and Portuguese – Automatically identifying entities such as persons, judges, lawyers, countries, cities, landscapes, organizations, courts, trademark laws, contracts, etc. in German and (Brazilian) Portuguese legal text.


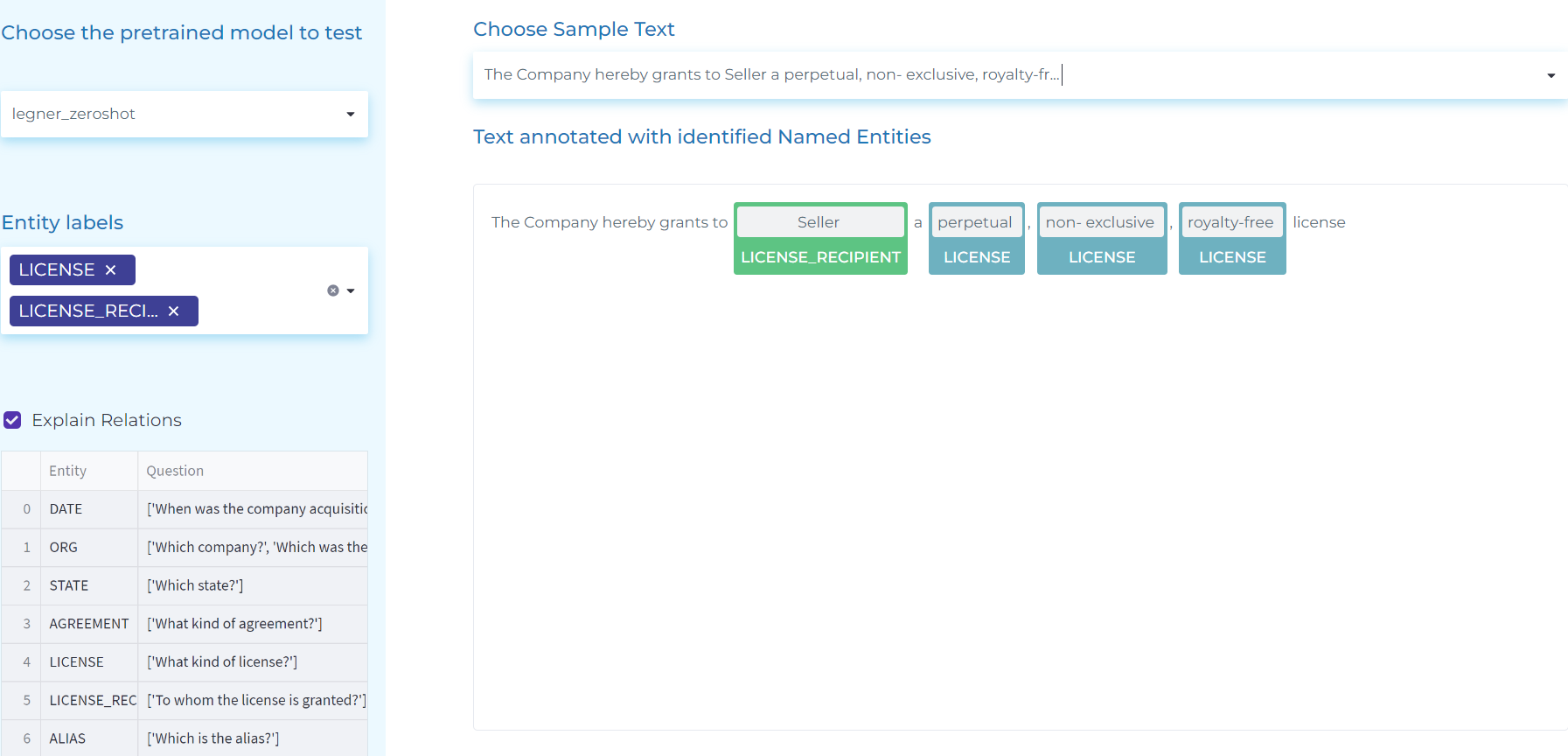
- Carrying out Legal Zero-Shot Named Entity Recognition.

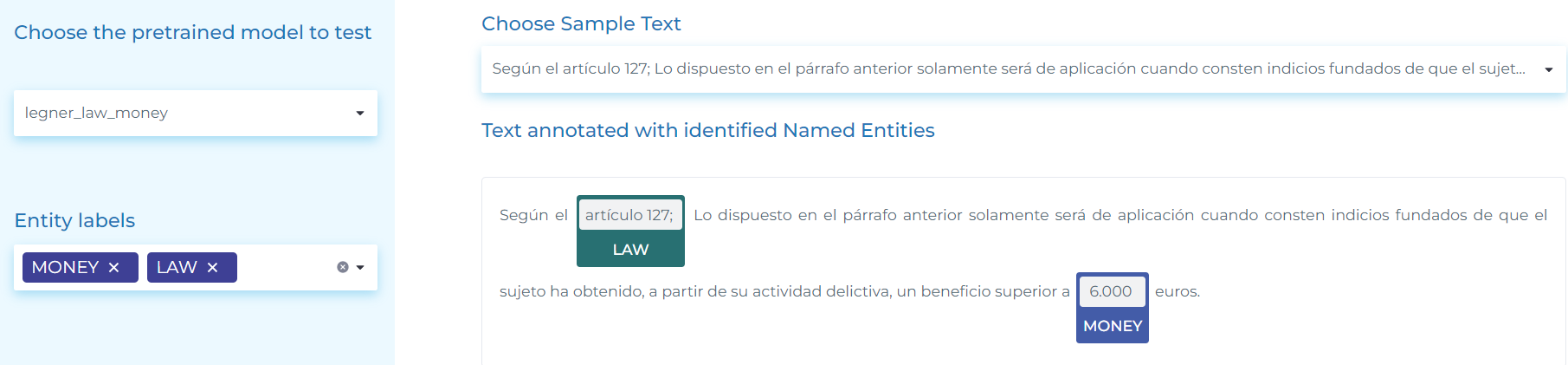
- Detecting law and money entities in Spanish.

- Extracting entities from Indian Court Preamble and Judgement documents LAWYER, JUDGE, COURT, WITNESS, RESPONDENT, PETITIONER etc.

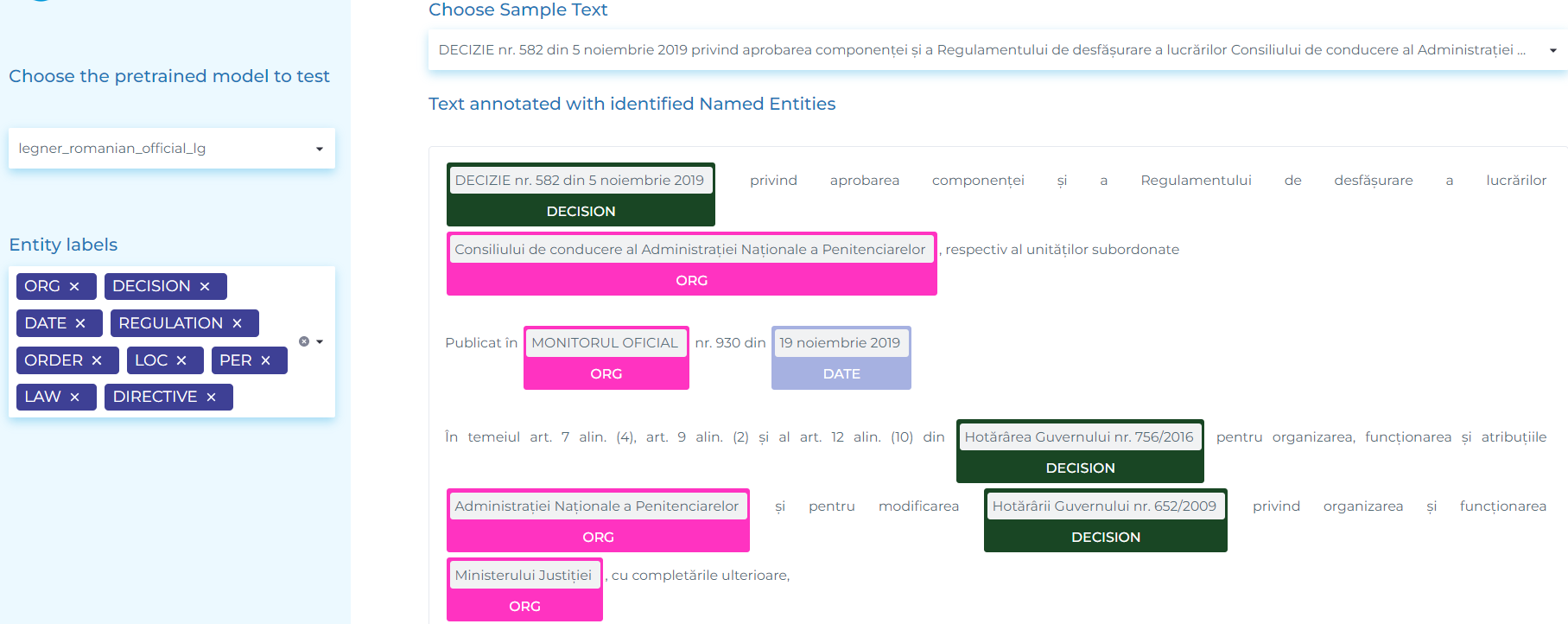
- Extracting the standard four entities (ORG, PER, LOC, DATE) and more 10 entities (DECISION, DECREE, DIRECTIVE, EMERGENCY_ORDINANCE, LAW, ORDER, ORDINANCE, REGULATION, REPORT and TREATY) from Romanian official documents.


Potential Risks of NLP in Legal
Below are the potential risks of using Natural Language Processing in the Legal industry.
Human Bias
NLP models are trained on voluminous amounts of text data, and they may include human bias, specifically about race and gender. This type of bias is difficult to audit and may go undetected.
Assume a law enforcement agency uses an NLP model to identify potential criminals based on social media posts. The agency trains the model on a large dataset of social media posts and associated criminal activity, with the goal of identifying patterns that suggest a person may be involved in criminal activity. However, the training data used to train the model may be biased against certain social/racial groups. For instance, the dataset may include a disproportionate number of posts from individuals identified as Black or Hispanic, even though these groups are not more likely to engage in criminal activity than other groups.
Consequently, the NLP model may learn to associate certain language patterns, such as the use of specific or slang keywords, with criminal activity. These language patterns may be more common among certain social or racial groups as the training data is biased. Thus, the model will falsely/inaccurately identify individuals from these groups as potential criminals.
This type of bias can have serious consequences in the legal domain. If law enforcement agencies rely on biased NLP models to identify potential criminals, they may more likely target individuals from certain social or racial groups, leading to potentially discriminatory practices.
Impact on Environment
Huge servers are required to train and run large language models. They consume a lot of electricity and have significant carbon emissions. For example, the recent GPT-3 model from OpenAI reportedly required the use of over 300 GPUs to train, which consumed a significant amount of electricity.
This high energy consumption leads to a large carbon footprint and contributes to climate change. For instance, the carbon footprint of training GPT-3 has been estimated to be equivalent to that of running a car for about 125,000 miles.
Furthermore, the disposal of GPUs and old servers can be problematic. They contain hazardous materials that may negatively impact the environment if not disposed of properly. Therefore, it is important for companies and organizations to consider the environmental impact of using large servers for NLP tasks and take steps to minimize this impact, such as using renewable energy sources or optimizing algorithms to reduce energy consumption.
Significant Costs
Large corporations can fund large language models, and can develop models that are better suited to their agendas, but small companies cannot afford the costs of training such large models. For instance, the original ChatGPT model was trained on a dataset of over 40GB of text data, and required hundreds of GPUs running for several days to complete the training process.
The cost of training such large language models can be a potential barrier to entry for small law firms that may not have access to large amounts of training data and the financial resources to invest in the necessary computational infrastructure. This can create a competitive disadvantage for small law firms, as they may not be able to leverage the benefits of NLP in the same way as larger firms.
Suppose a large law firm has access to well-trained language models that quickly and accurately analyze legal documents, identify potential issues, and generate summaries. This can give the firm a significant advantage over smaller firms that do not have access to the same resources, as it can provide faster and more accurate analysis to its clients, allowing it to win more business. In contrast, a small law firm that cannot afford to train such models may rely on slower and less accurate manual processes, making it less competitive in the marketplace.
Conclusion
Legal NLP is a John Snow Lab’s product that provides state-of-the-art accuracy, and a broad set of out-of-the-box models for common tasks.
With more than 600 models, featuring Deep Learning and Transformer-based architectures, Natural language Processing for Legal includes:
- Integration with Databricks, AWS and Azure
- Relation extraction and Zero-shot Named Entity Recognition
- 600+ pre-trained Deep Learning / Transformer-based models;
- Annotators to carry out Relation Extraction, Named Entity Recognition, Assertion Status, Deidentification, Question Answering, Sentiment Analysis, Summarization, and much more
- 33+ notebooks and 25+ demos ready to showcase its features.
- Compatibility with Visual NLP
- Full integration with NLP Lab (former Annotation Lab) for managing annotation projects and training legal models in a zero-code fashion.




