Use pretrained models, segment texts into words, and train custom word segmenter models with Python.
TL; DR: Some Asian languages don’t separate words by white space like English, and NLP practitioners need to tokenize the texts using word segmentation (WS) models. Spark NLP has pretrained models for WS and the capability to train new ones based on labeled data.
Spark NLP as a Chinese Word Segmenter
Word Segmentation is an NLP task for languages that don’t have white space between their words, for example, Chinese, Japanese, Thai, and Korean. Take this Chinese sentence as an example:
今天我很高兴
The words 今天 (today), 我 (I), 很 (very), and 高兴 (happy) don’t have any separation between them, and processing this sentence in a programmatically way can be hard. For these kinds of languages to perform NLP tasks, we need to be able to tokenize the sentences into their parts.
Common ways to do that include splitting the sentence character (or ideogram) by character, without taking into consideration that words can be formed with more than one of them. Another way is to use Word Segmentation (WS) models, which can be based on dictionaries or machine learning models to identify which subset of ideograms form the words to split them.
In this post, we are going to explore how to perform word segmentation using Spark NLP.
About Spark NLP
Spark NLP refers to open-source libraries. This library is maintained by John Snow Labs company. It is based on Apache Spark and Spark Machine Learning. The annotations provided by Spark NLP for ML-pipelines are accurate, simple, and performant and can be scaled easily in a distributed environment.
It has been released in 2017. Since then, Spark NLP has evolved into a full-scaled NLP tool that provides:
- a unified NLP solution for all client’s needs;
- The NLP library most commonly utilized in the industry for 5 years in a row;
- The most scalable, rapid, and highly accurate library in the history of natural language processing technology;
- Transfer learning and implementing in NLP research the best and latest SOTA models and algorithms.
Spark NLP offers over 12,000 pre-trained pipelines and models in more than +250 languages including Asian languages (such as Chinese, Japanese, Korean, and Thai), which are really challenging to process. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.

Spark NLP modules
Spark NLP processes the data using Pipelines, a structure that contains all the steps to be run on the input data:
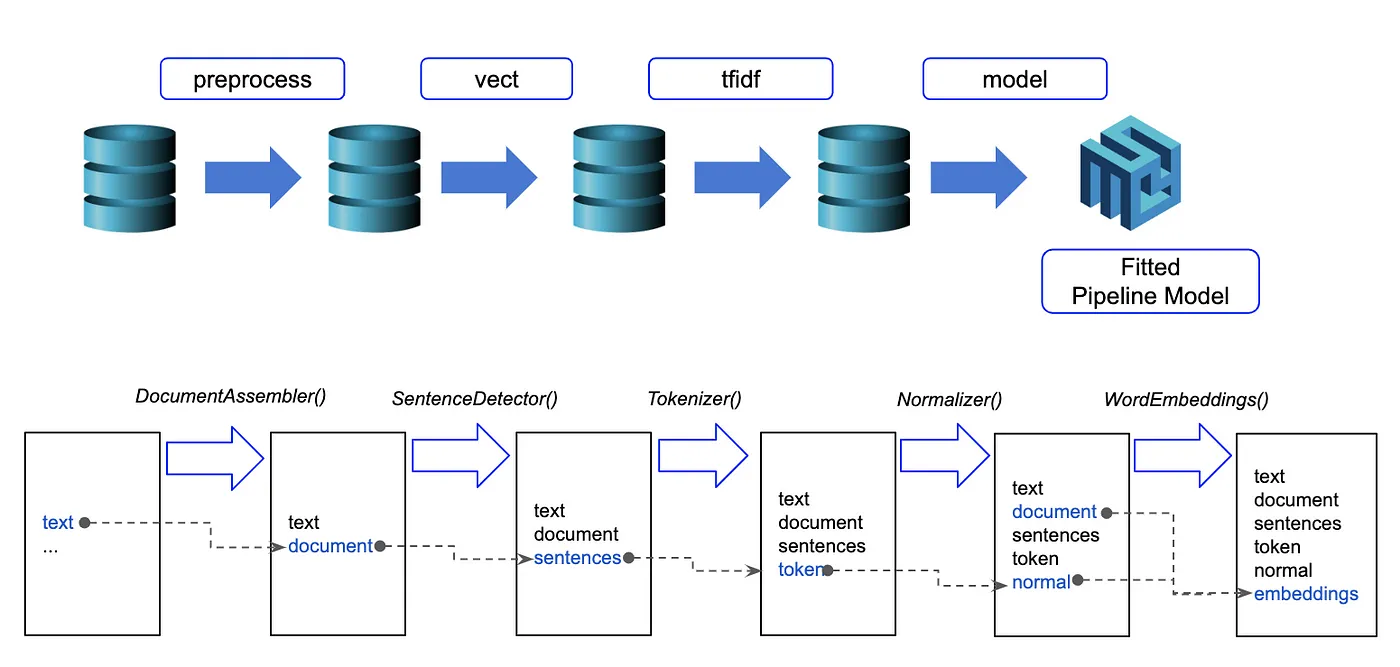
Spark NLP pipelines
Each step contains an annotator that performs a specific task, such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
Spark NLP Installation
To set up Spark NLP in Python, simply use your preferred package manager (conda, pip, or other). For example:
pip install spark-nlp
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp
spark = sparknlp.start()
Features of Chinese word segmentation with Spark NLP
Spark NLP currently has pretrained models for Chinese, Japanese, Korean, and Thai. Let’s use an example in Chinese:
我们都很喜欢自然语言处理!
In this example, the words are 我们 (we, composition of two ideograms), 都 (all, only one ideogram), 很 (very, only one ideogram), 喜欢 (like, composition of two ideograms), 自然语言处理 (NLP, composition of six ideograms) which can be split further down to 自然 (Natural), 语言 (Language), and 处理 (Processing).
The annotator to perform WS using pretrained models in Spark NLP is the WordSegmenterModel. This annotator uses DOCUMENT annotations as input and outputs TOKEN annotations. For a list of available models, check NLP Models Hub. The pipeline consists of only two stages, the document assembler that creates the DOCUMENT annotation from raw texts and the WordSegmenterModel stage to split the text into words.
To use pretrained models in Spark NLP, simply use the .pretrained() method of the desired annotator, and pass as parameters the name of the model to use and the language the model was trained in. In our example, we will use the model called wordseg_ctb9 which was trained on the Chinese Treebank version 9 dataset. You can explore other available models in the NLP Models Hub.
from sparknlp.base import DocumentAssembler
from sparknlp.annotator import WordSegmenterModel
from pyspark.ml import Pipeline
import pyspark.sql.functions as F
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
# Model trained on the Chinese Treebank 9 dataset
word_segmenter = (
WordSegmenterModel.pretrained("wordseg_ctb9", "zh")
.setInputCols(["document"])
.setOutputCol("words_segmented")
)
pipeline = Pipeline(stages=[document_assembler, word_segmenter])
We then can transform the pipeline into a PipelineModel to make predictions. Since we only have pretrained stages, we can just fit the pipeline in empty data:
# Create an empty data frame with column `text`
empty_df = spark.createDataFrame([[""]]).toDF("text")
model = pipeline.fit(empty_df)
Now we can apply the model to our example sentence, which needs to be in a spark data frame.
# Chinese example
example_sentence = r"我们都很喜欢自然语言处理!"
example_df = spark.createDataFrame([[example_sentence]]).toDF("text")
# Make predictions
result = model.transform(example_df)
result.select(
F.explode("words_segmented.result").alias("word")
).show()
+----+ |word| +----+ |我们| |都 | |很 | |喜欢| |自然| |语言| |处理| |! | +----+
We can see that the model split Natural Language Processing into its parts and didn’t consider it as one word. This can happen to unfamiliar words or technical words which were not present or very scarce in the training data, so depending on your needs, choosing which model to use can have a significant impact.
Splitting words with one line of code
In October 2022, John Snow Labs released the open-source johnsnowlabs a library that contains all the company products, open-source and licensed, under one common library. This simplified the workflow, especially for users that work with more than one of the libraries (e.g., Spark NLP + Healthcare NLP). This new library is a wrapper on all of John Snow Labs’ libraries, and can be installed with pip:
pip install johnsnowlabs
Please check the official documentation for more examples and usage of this library. To perform Chinese word segmentation, we can simply run:
nlp.load("zh.segment_words.ctb9").predict("我们都很喜欢自然语言处理!")
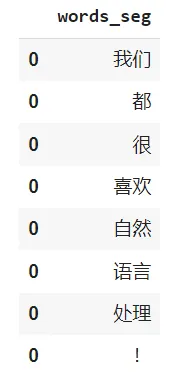
Result from the one-liner word segmenter model
NOTE: When using only the johnsnowlabs library, make sure you initialize the spark session with the configuration you have available. Since some libraries are licensed, you may need to set the path to your license file. If you are only using the open-source library, you can start the session with spark = nlp.start(nlp=False). The default parameters for the start function include using the licensed Healthcare NLP library with nlp=True, but we can set that to Falseand use all the resources of the open-source libraries such as Spark NLP, Spark NLP Display, and NLU.
The pretrained models are useful for most applications, but in some cases, they don’t fit the practitioner’s needs. If this happens, you can also train a new one!
Training a new WordSegmenterModel
To train a new model, we need to use the WordSegmenterApproach annotator. The implemented in Spark NLP model is a modification of the following reference paper:
Chinese Word Segmentation as Character Tagging (Xue, IJCLCLP 2003)
It is a machine-learning model that uses labeled data to learn in a supervised manner. The training data is a text file in the same format used to train Part-of-Speech (POS) models, meaning that each ideogram/character is tagged with a label and the characters are separated by a delimiter.
We will use the following as training data to train a simple Korean Word Segmenter model (character and tag are separated by | and characters-tag are separated by white space):
우|LL 리|RR 모|LL 두|MM 는|RR 자|LL연|MM 어|MM 처|MM 리|MM 를|RR 좋|LL 아|MM 합|MM 니|MM 다|RR !|LR
Where the labels are:
LL: The beginning of the wordMM: Middle part of the wordRR: The end of the wordLR: A word formed of only one character
We will save this example in a text file:
with open("train_data.txt", "w", encoding="utf8") as f:
f.write("우|LL 리|RR 모|LL 두|MM 는|RR 자|LL 연|MM 어|RR 처|LL 리|MM 를|RR 좋|LL 아|MM 합|MM 니|MM 다|RR !|LR ")
To read this kind of dataset, you can use the helper class POS available in the sparknlp.training module.
from sparknlp.training import POS train_data = POS().readDataset(spark, "train_data.txt") train_data.show()
+-----------------------------+--------------------+--------------------+
| text| document| tags|
+-----------------------------+--------------------+--------------------+
|우 리 모 두 는 자 연 어 처...|[{document, 0, 32...|[{pos, 0, 0, LL, ...|
+-----------------------------+--------------------+--------------------+
The POS class creates a spark data frame with the text, document, and tags columns. They contain, respectively, the raw text, the DOCUMENT annotation, and the POS annotation of the corpus. The WordSegmenterApproach needs information on these columns is to train the model, so we need to set them as the input and POS columns:
wordSegmenter = (
WordSegmenterApproach()
.setInputCols(["document"])
.setOutputCol("token")
.setPosColumn("tags")
.setNIterations(10)
.setFrequencyThreshold(1) # Since our data is very small
)
pipeline = Pipeline().setStages([documentAssembler, wordSegmenter])
Then, to train the model we fit it into the training data:
pipelineModel = pipeline.fit(train_data)
Done, we have our brand-new Word Segmenter model. Let’s see how to use it in practice. We will use the LightPipeline to make predictions directly on strings instead of using spark data frames. You can learn more about this class in this link and in this previous post.
lp = LightPipeline(pipelineModel)
lp.annotate("우리모두는자연어처리를좋아합니다!")
{
"document": ["우리모두는자연어처리를좋아합니다!"],
"token": ["우리", "모두는", "자연어", "처리를", "좋아합니다", "!"]
}
The results from Light Pipelines are a dictionary if only one string was passed or a list of dictionaries if a list of strings is used.
That’s it! Now you know how to train a new Word Segmenter model, as well as how to use a pretrained one!
Conclusion
In this post, you learned about word segmentation and how to perform this NLP task using pretrained models in Spark NLP. You also learned how to train a new model using labeled data and are ready to segment words in Chinese, Japanese, Korean, or Thai.
References
- Documentation: WordSegmenter
- Python Docs: WordSegmenter
- Scala Docs: WordSegmenter
- For extended examples of usage, see the Spark NLP Workshop repository.
- LightPipeline post