Generative AI Lab are a FREE tool covering the end-to-end process for data annotation, DL model training and testing, and model deployment. Its purpose is to offer a NO-CODE environment for domain experts to create high-quality training data for NLP DL models and to train such models on their own without the use of a data science team.
This blog post is the third part of a series of posts covering the concrete steps to follow when putting together annotation projects. Here, I illustrate how you can train a new model based on the annotations automatically generated using rules and manually corrected by human annotators. The use case is that of recipe data analysis for detecting ingredients, quantities, or cooking time and temperature.
You can check the first part of this tutorial to learn how to define dictionary and regex-based rules for data preannotation and the second part of this tutorial to learn how to set up annotation projects and correct rule-based predictions for preparing training data.
For this food processing example, I have used the 200 recipes available here. Those were preannotated using Contextual Parser rules and then manually corrected by a team of four annotators.
Train a custom DL Model
Once all documents were manually annotated, I trained a new custom model. From the tasks view, I select 20 tasks and tag them as test tasks. Those will be used for model testing. They will not be included in the model training dataset.
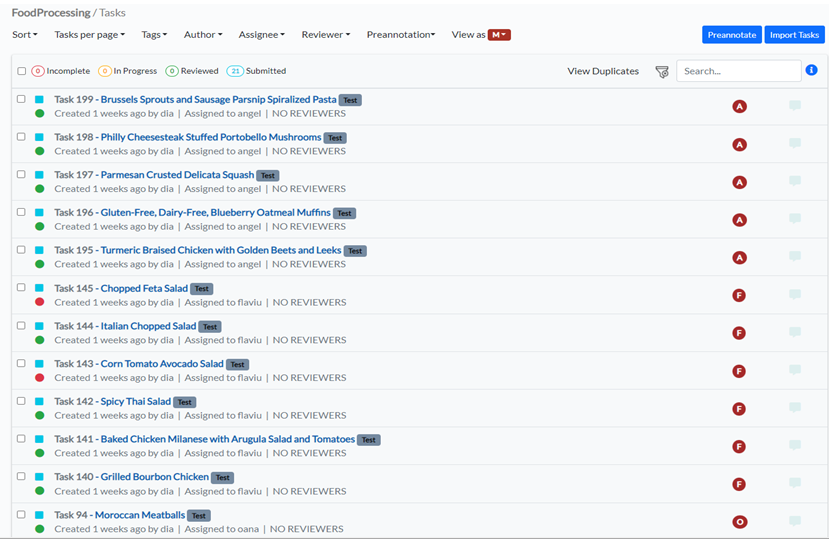
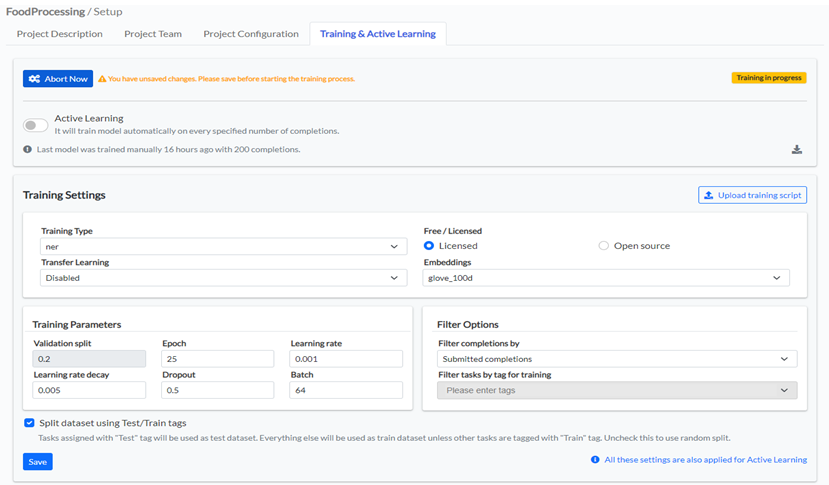
From the Project Setup page, Training & Active Learning tab, I choose the type of model I want to train, in this case, ner, and the embeddings I want to use for training – glove_100d. Given the fact that I do not have any pretrained model to use as a base model for fine-tuning, I disabled the Transfer Learning option. I choose the default training parameters and checked the Split dataset using Test/Train tags. The final step is to press the Train Now button.
At this point, the training will start and you can check the status by clicking on the Training (step x of 3) button. The log looks like in the bellow image. You can notice the precision, recall, and f1 score obtained on each epoch.
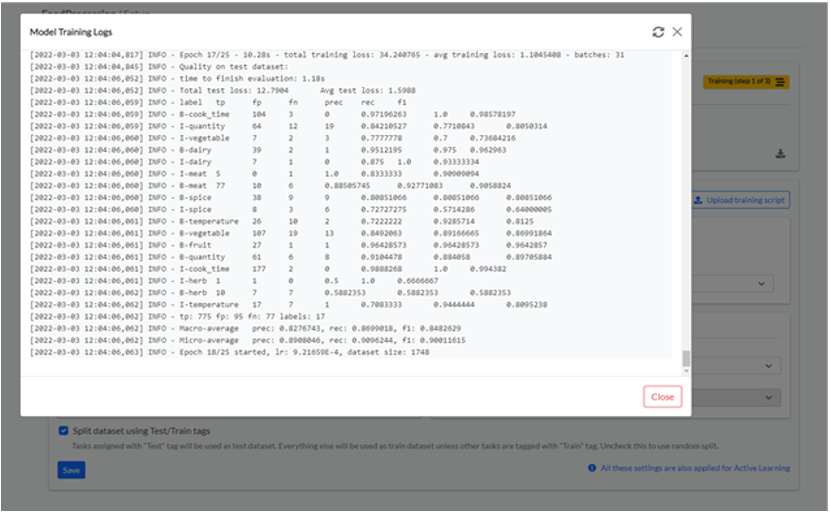
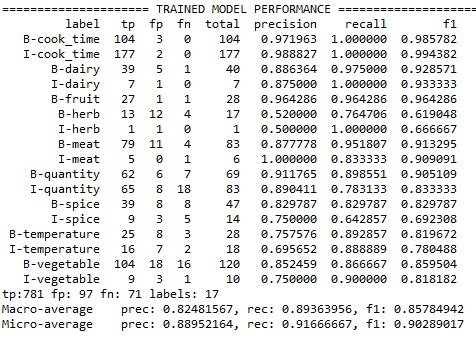
The accuracy matrix obtained for this model is:
What next?
In this series of blog posts, I illustrated all steps for putting together an annotation project, speeding annotation with rules, and training a new mode from scratch. If the first iteration does not deliver a model with the targeted accuracy you need to start investigating the quality of your annotations – check the rules, the IAA metrics via the Analytics page and try to improve the training data. Alternatively, you can annotate more data and experiment with other embeddings, or training parameters. Once you are satisfied with the obtained model you can deploy using the NLP Server. That process will be detailed in a follow-up blog.