
























































NLP Lab 5.7 marks a significant milestone in the realm of natural language processing with the introduction of advanced Relation Extraction (RE) model training features. In this release, users will discover a suite of powerful functionalities designed to enhance efficiency, collaboration, and customization. The new RE model training feature focuses on augmenting the capabilities for text analysis, offering an intuitive and flexible approach to building and managing custom RE models.
This new release demonstrates our continuous commitment to delivering advanced tools for text analysis and document processing tailored to address our users’ evolving needs. Detailed descriptions of all new features and improvements are provided below.
Training Relations Extraction (RE) Model
We are excited to announce that NLP Lab 5.7 offers training features for Relation Extraction (RE) models. This new feature is augmenting our offerings for text analysis, providing users with a robust set of tools for building and managing custom RE models. Key benefits include:
- Customizable RE Model Development: Tailor RE models to your specific needs for text analysis, expanding the breadth of Model Training and Active Learning within the NLP Lab.
- Optimization of Downstream Tasks: Apply trained RE models in pre-annotation workflows to significantly minimize manual labeling workload, thus expediting project timelines.
- Fostering Collaboration and Knowledge Sharing: Reuse models across projects, facilitating knowledge transfer and enhancing task performance.
- Efficient Model Management: Effortlessly download, upload, and publish trained RE models for collaborative use and broader community access through the Models Hub.
Note: The RE model training feature is accessible exclusively for NER text projects. It becomes available when a NER text project is created and the Relation section is configured, activating the “re” option in the Training Type dropdown.
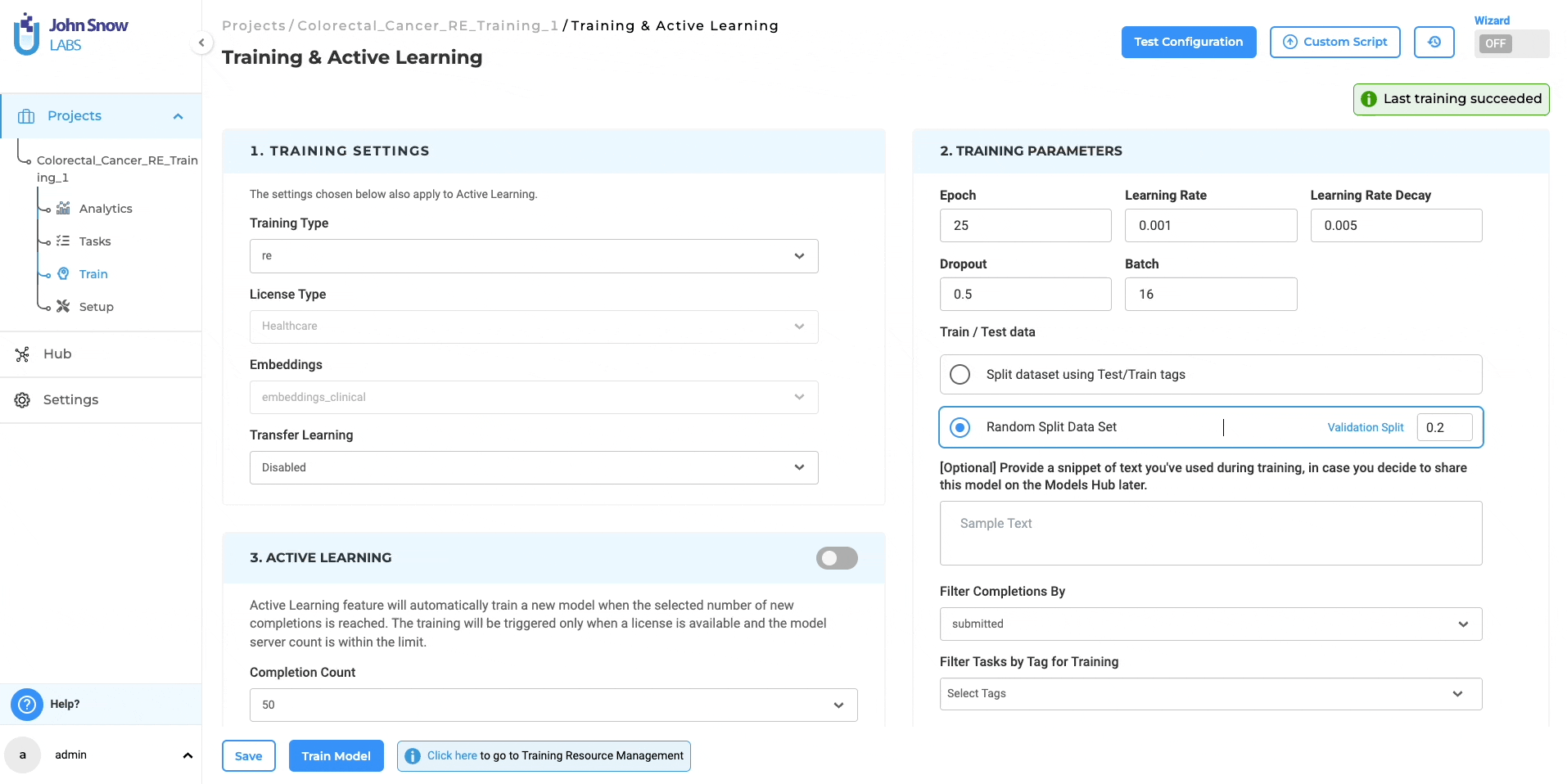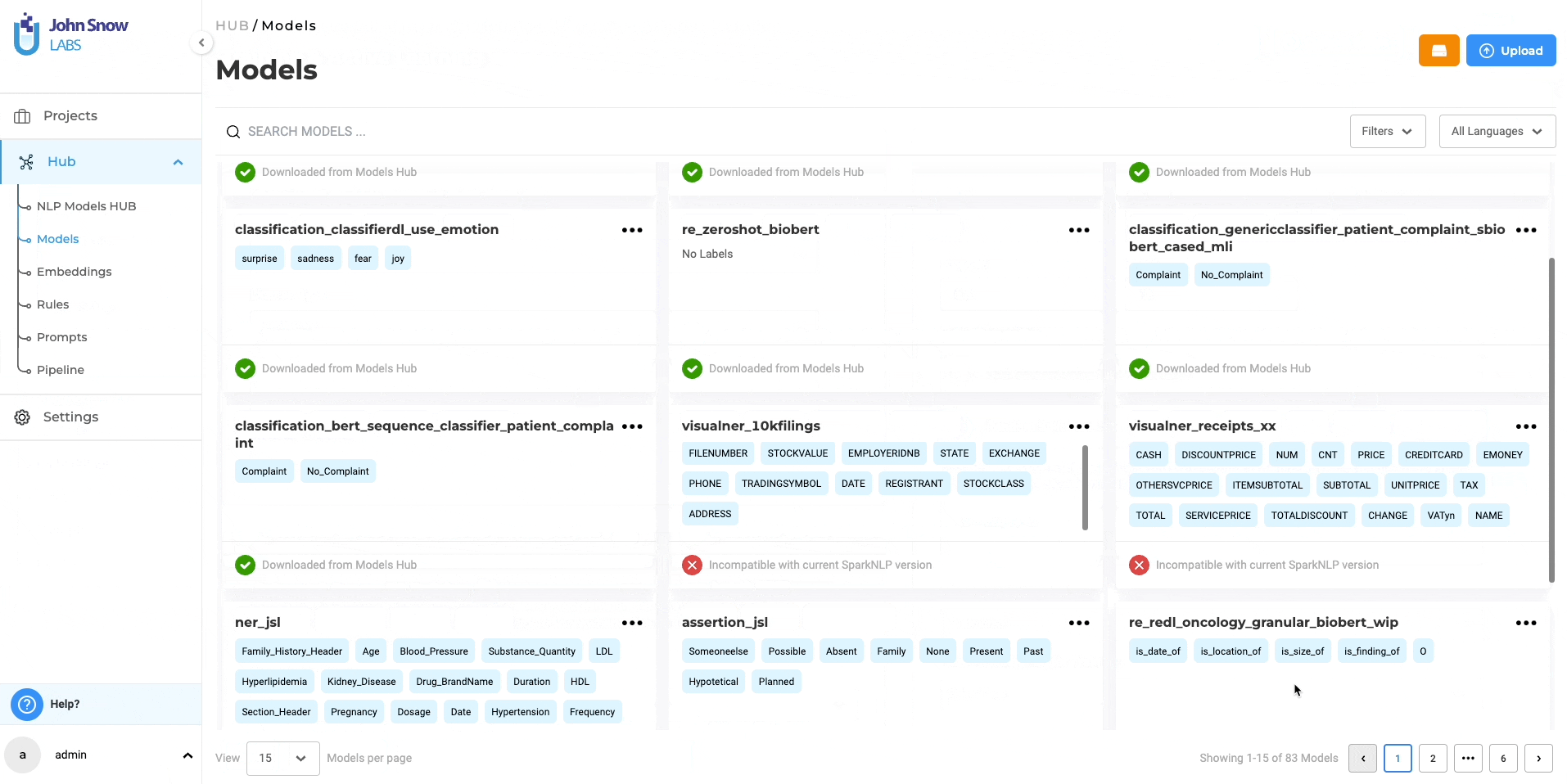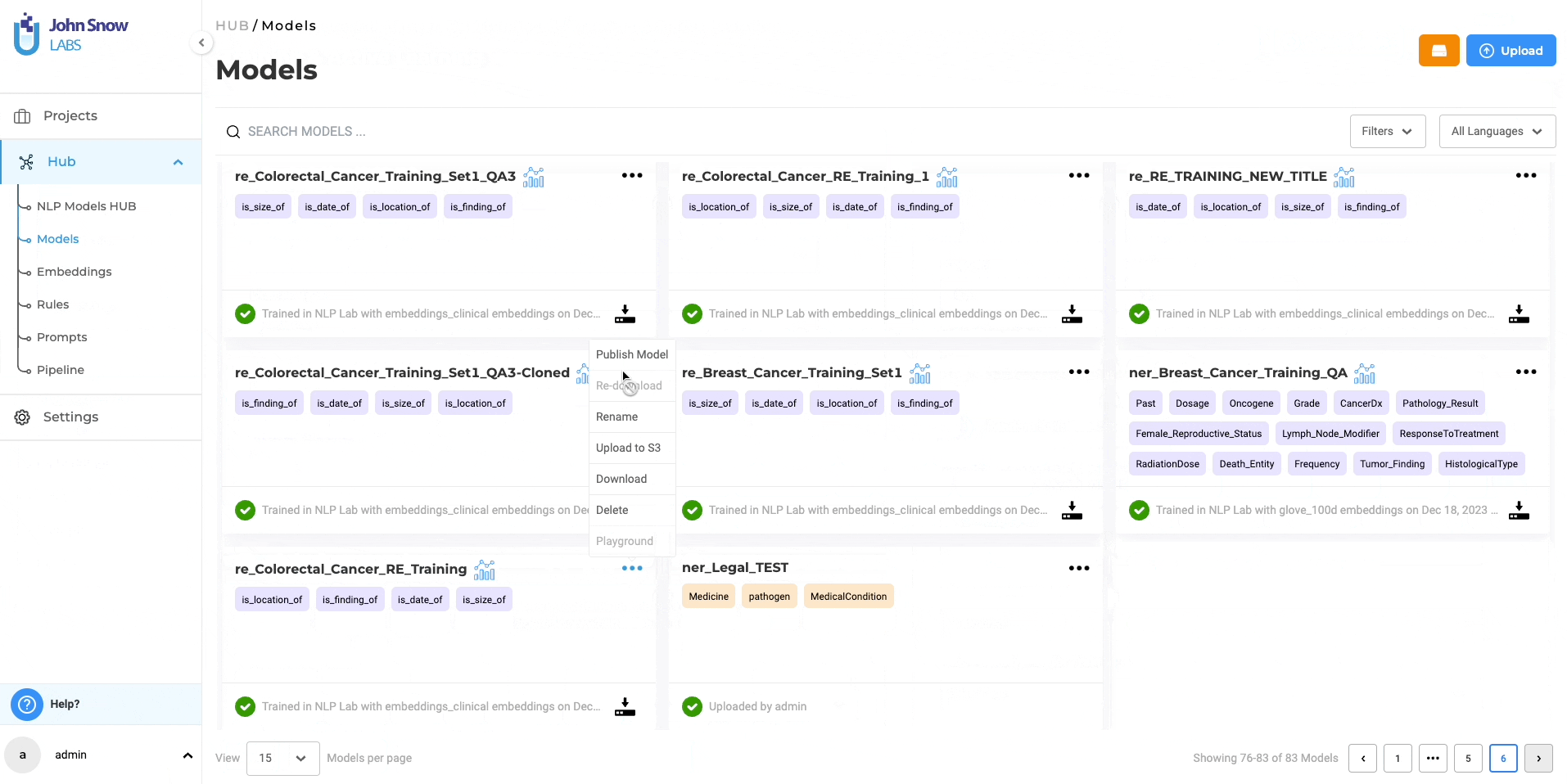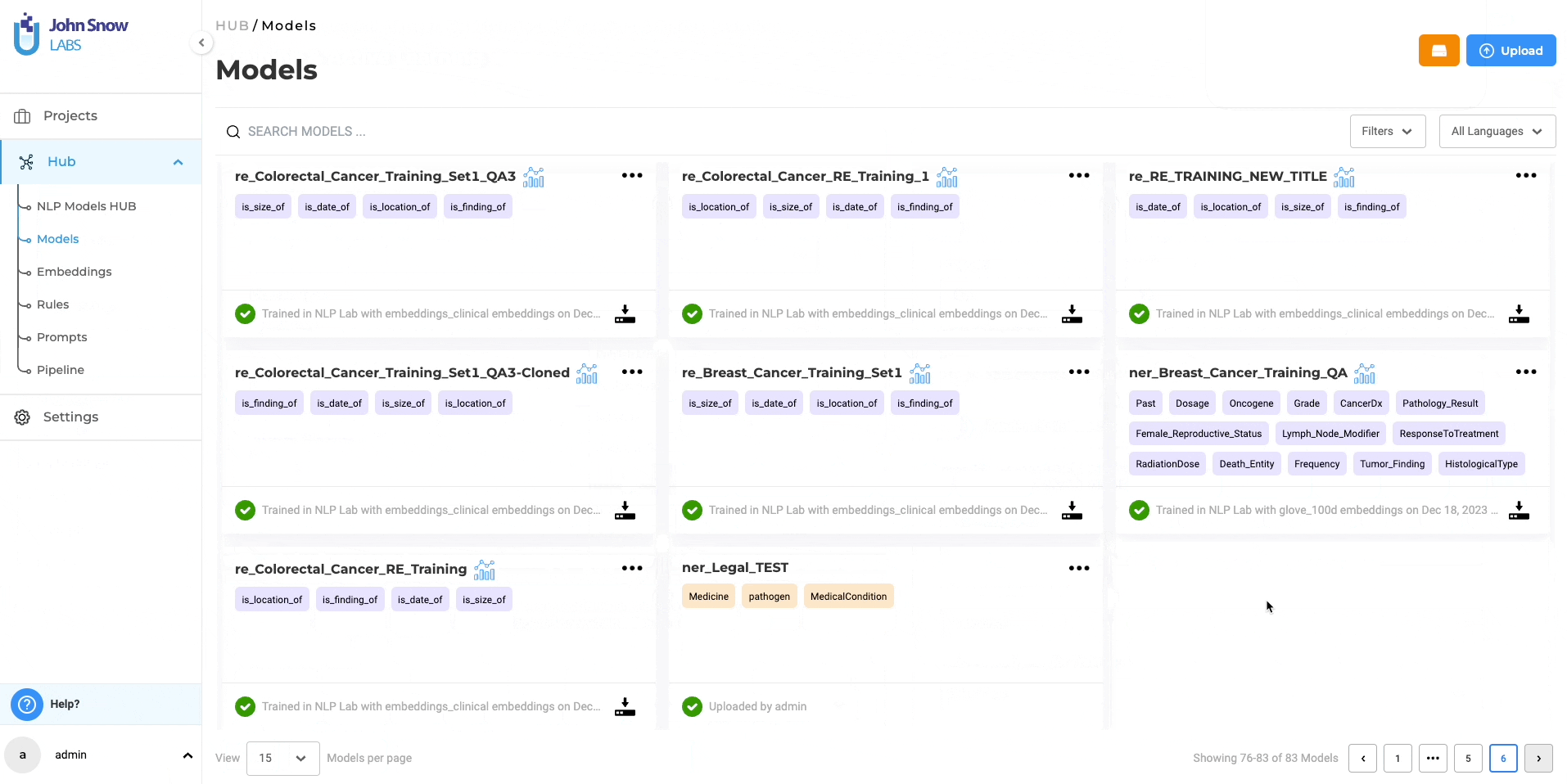
Initiating the Relations Extraction (RE) Training Job:
- Access Training Page: Navigate to the “Train” page within the Project Menu to set up and start model training jobs.
- Select Training Type: Choose “re” from “Training Type” for RE model training.
- Automated Configuration: Selecting “re” auto-configures “Embeddings Field” and “License Type” to “embeddings_clinical” and “Healthcare” respectively.
- Configuration Customization: Modify training parameters as needed and save your settings.
- Start Training: Initiate the training with a step-by-step wizard, allowing real-time monitoring of progress and logs.
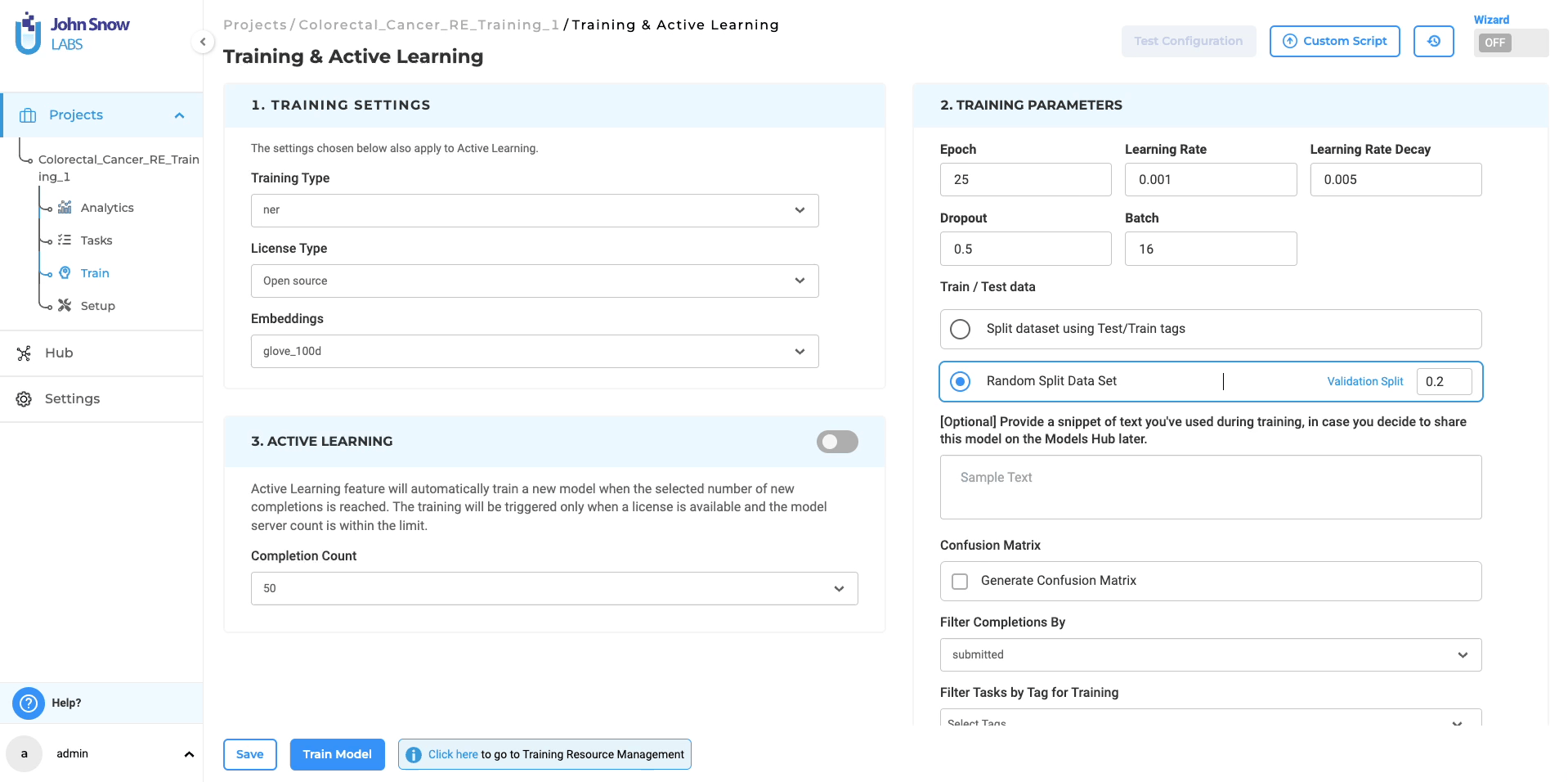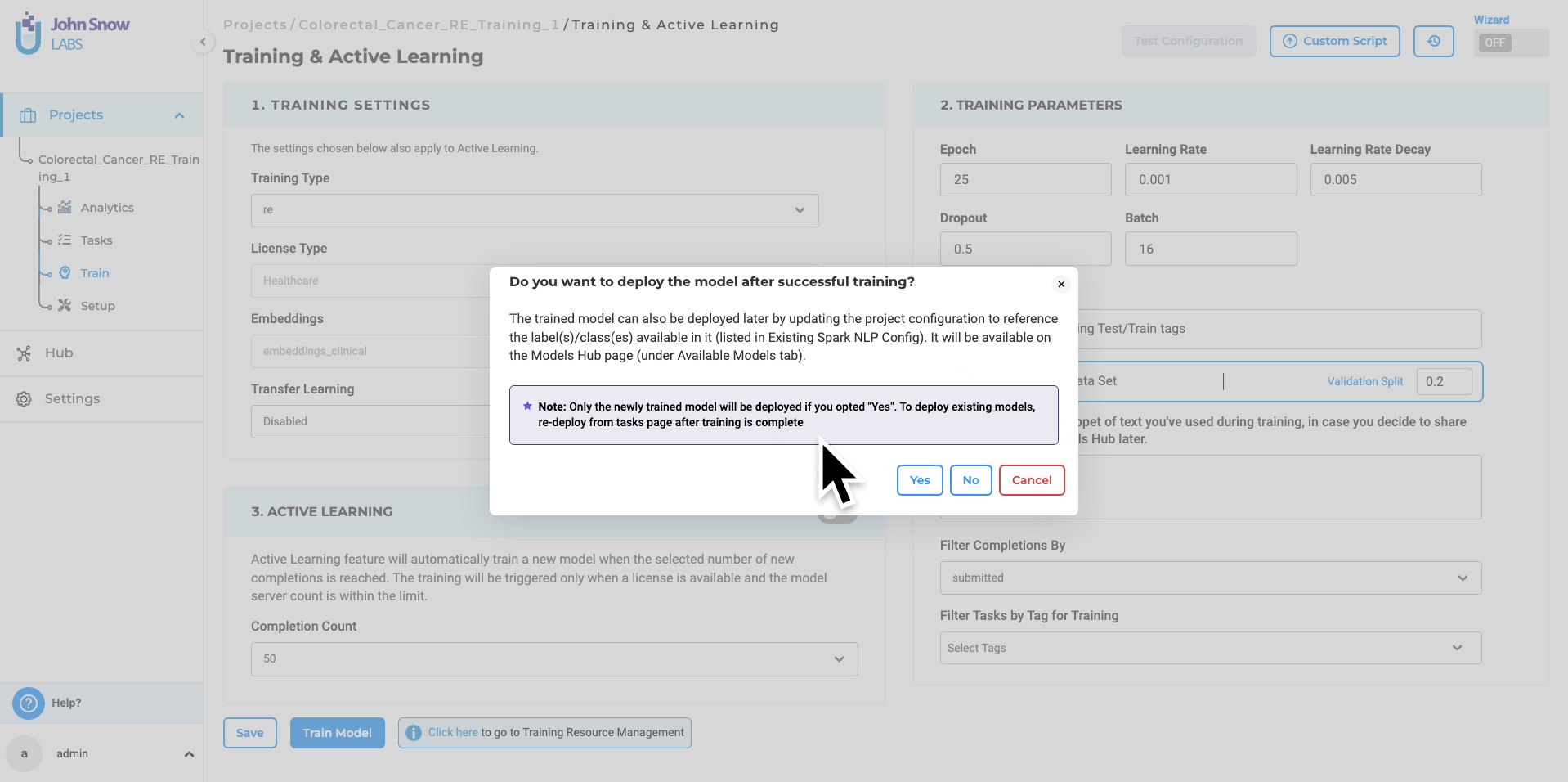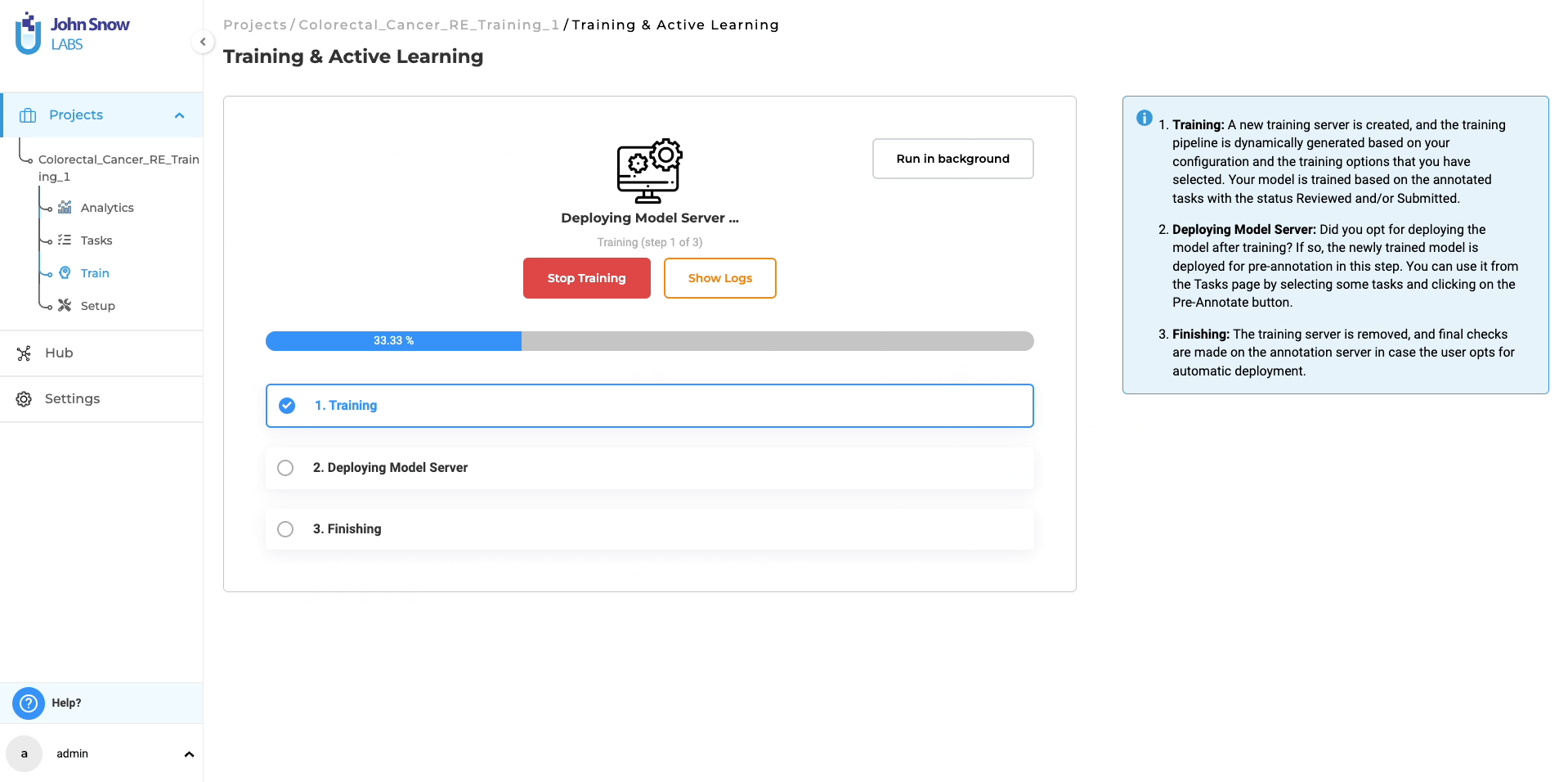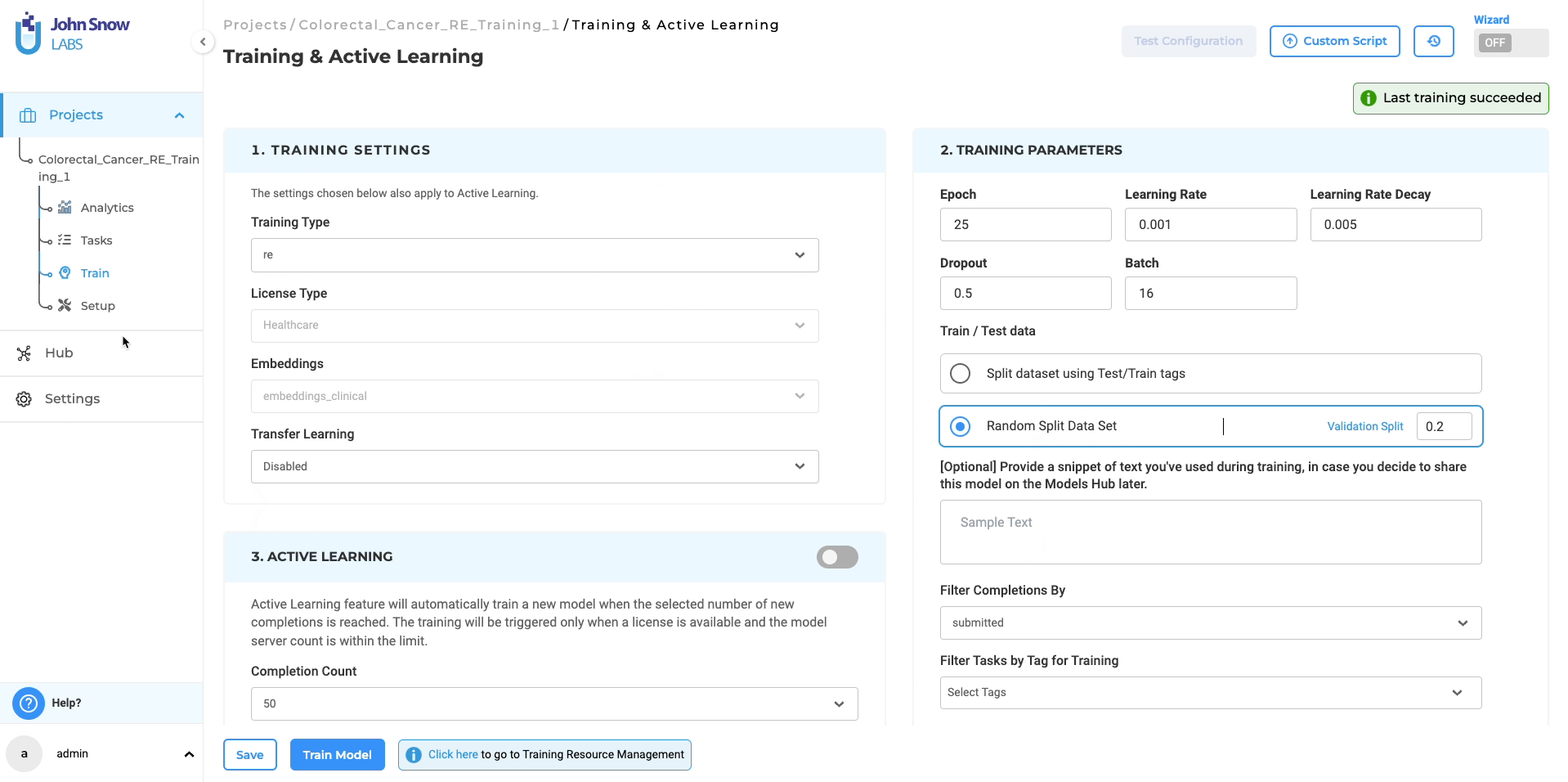
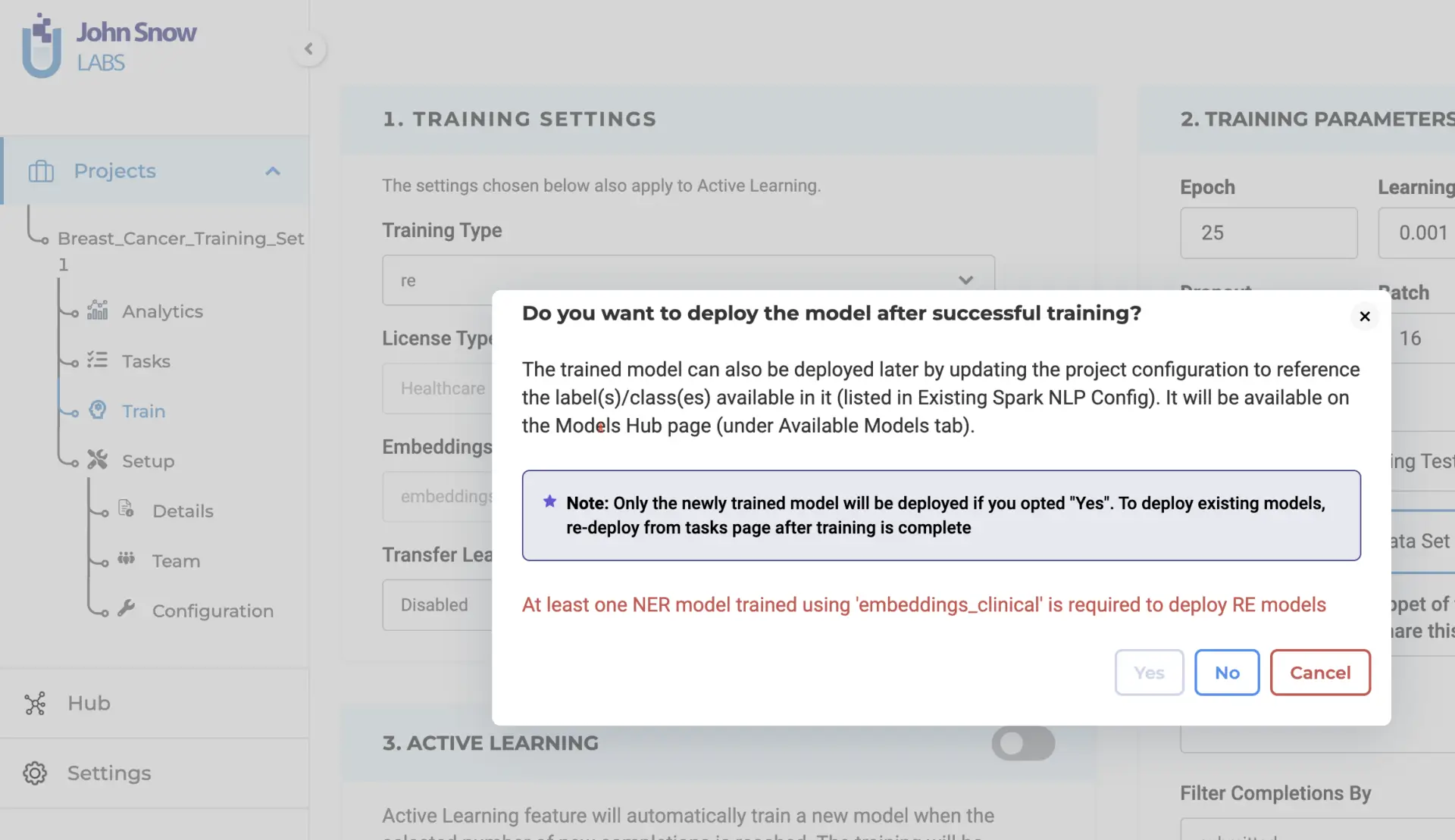
Deployment Choices: When triggering the training, users can opt for immediate model deployment post-training. This implies the automatic update of the project configuration with the new model’s name.
Prerequisite for RE Model Training:
To achieve successful training of an RE model, it is essential to have at least one Named Entity Recognition (NER) model trained using the “embeddings_clinical” type specified in the project configuration. This guarantees the best performance and compatibility of features. Users have the option to pre-train an NER model or utilize an existing pre-trained model available within the project. This approach ensures optimal results and maximizes efficiency during RE model training.
Upon verifying the adequacy of the project configuration and training parameters, the system will begin the RE model training process. Once the training is finished, the resulting trained RE model will be accessible on the “Models” page for further utilization. Furthermore, you have the option to retrieve comprehensive training logs by clicking on the download icon associated with the Trained RE model. These logs offer valuable information concerning the training parameters and evaluation metrics, allowing for deeper insights into the training process.
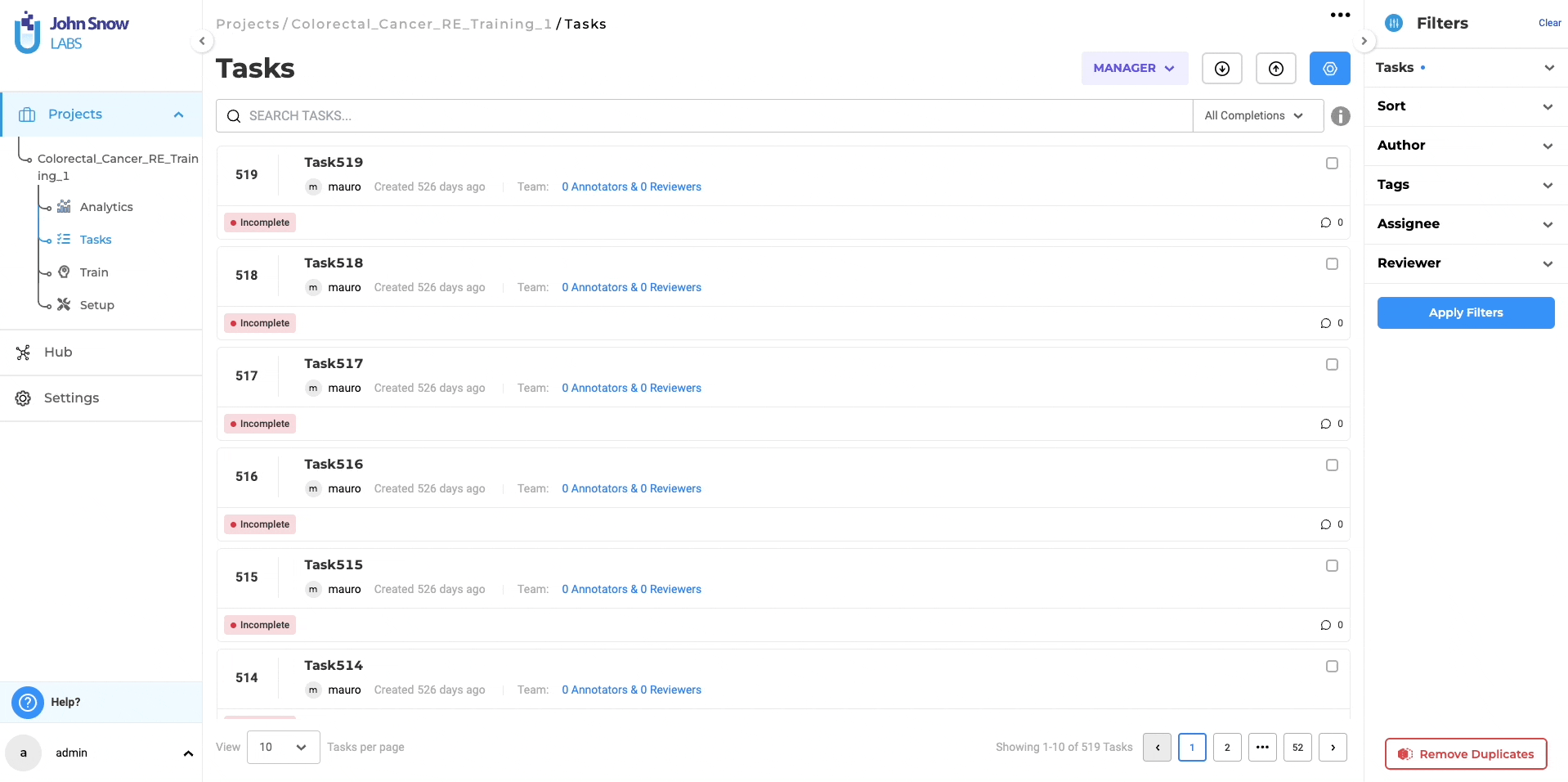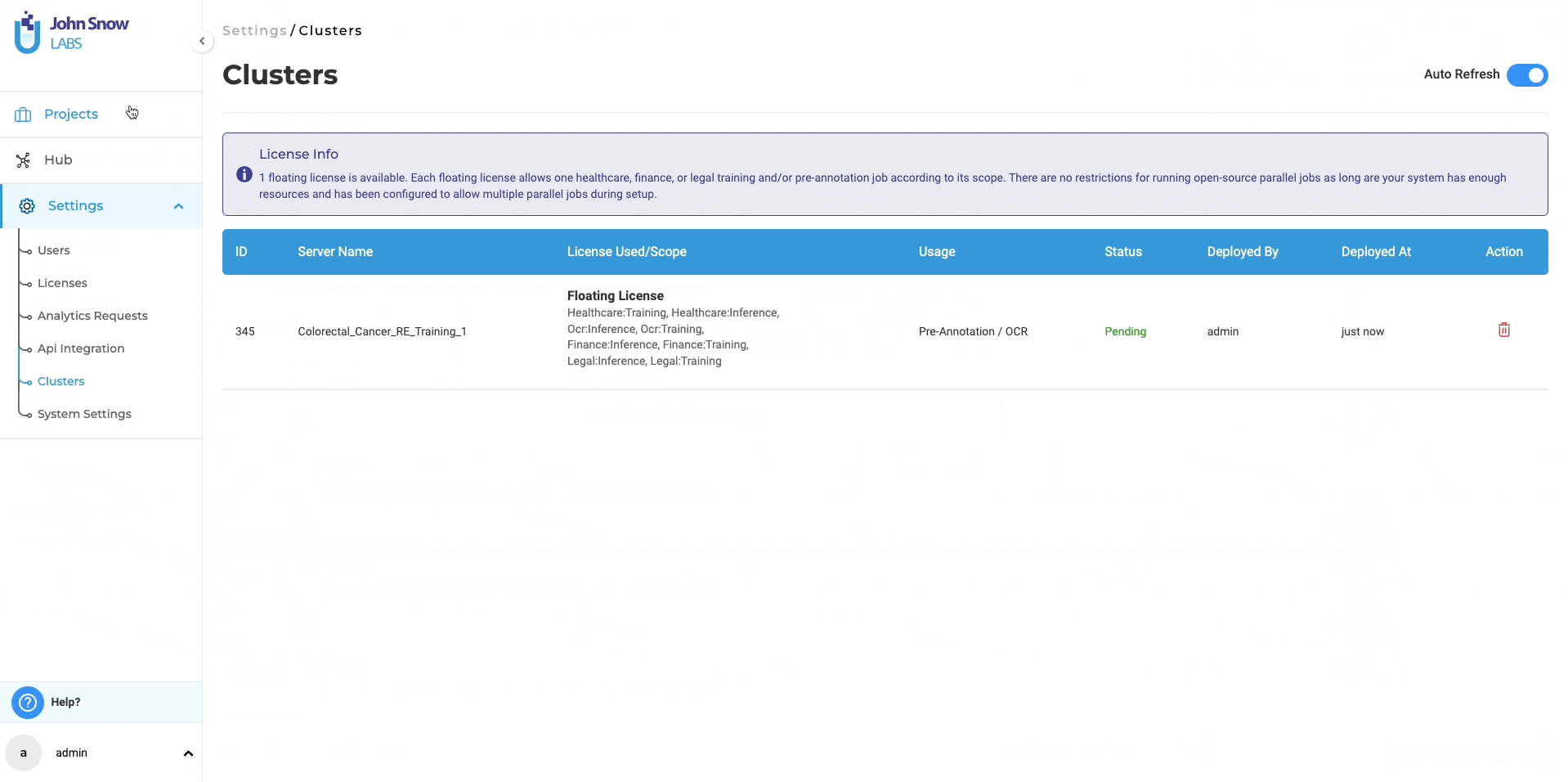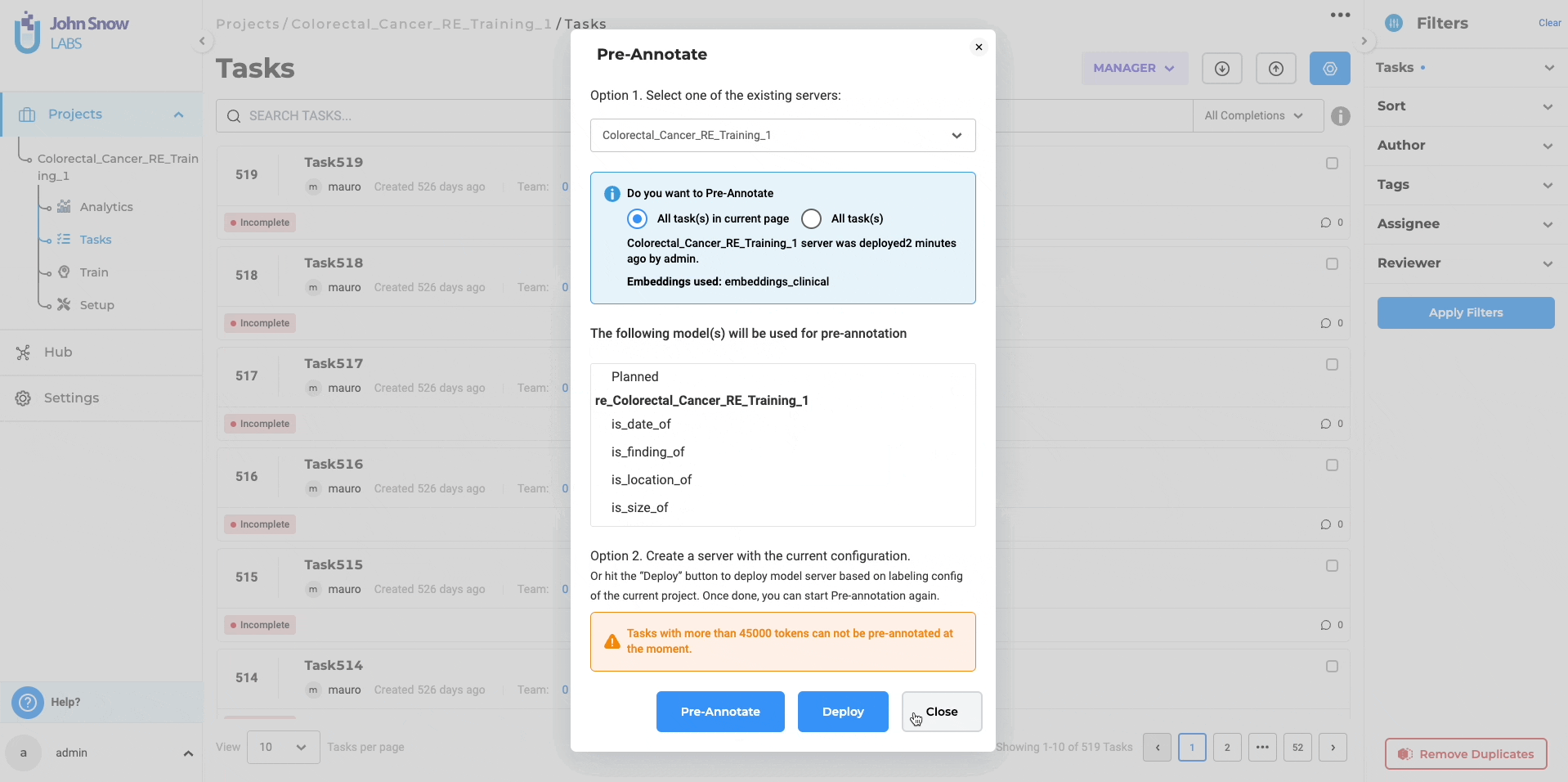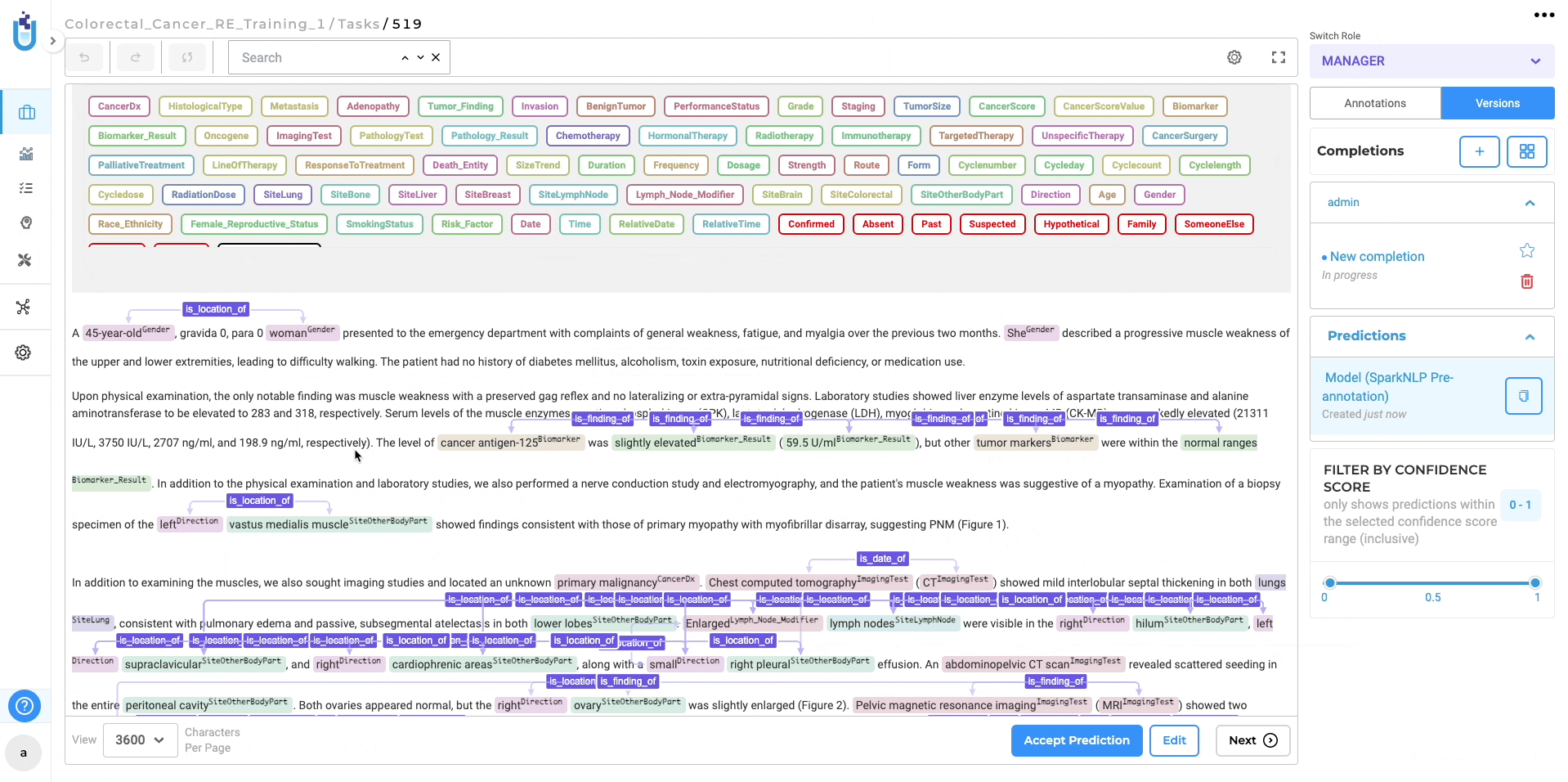
Pre-annotation with Trained Relations Extraction (RE) Models
If you opt for immediate deployment, the trained RE model automatically serves as a pre-annotation server for the tasks within your project once the training is complete. This significantly reduces the need for manual annotation, saving valuable time and effort. Additionally, you can utilize the trained RE models in other projects by accessing the “Re-Use Resources” section within the desired project’s configuration. It is essential to include the model and ensure that the target project has at least one “embeddings_clinical” NER model trained for compatibility. By saving the configuration, you can deploy the RE and NER models as a pre-annotation server. Alternatively, you can create a new server directly from the task list page using the “Pre-Annotate” button for immediate deployment.
RE Model Management and Sharing
The “Models” page, under the Hub of resources, serves as a centralized hub where you can conveniently access all pre-trained and trained models, including RE models. You can download the trained RE models for offline use and even upload them back to the NLP Lab using the Upload Model Feature. Furthermore, from the “Models” page, you can directly publish the trained RE models to the Models Hub, enabling broader sharing within the community. This facilitates collaboration and knowledge exchange among a wider audience.
Getting Started is Easy
The NLP Lab is a free text annotation tool that can be deployed in a couple of clicks on the AWS, Azure, or OCI Marketplaces or installed on-premise with a one-line Kubernetes script.
Get started here: https://nlp.johnsnowlabs.com/docs/en/alab/install
Start your journey with NLP Lab and experience the future of data analysis and model training today!





