The impact of Natural Language Processing in everyday life is hard to ignore as it is the main driver of emerging technologies like Robotics, Big Data, Internet of Things, etc. It enables machines to process massive amounts of data and make informed decisions.
In this article, we will discuss the use of Clinical NLP in understanding the rich meaning that lies behind the doctor’s written analysis (clinical documents/notes) of patients.

Clinical NLP
Clinical NLP systems have several requirements such as:
- Entity Extraction – Clinical Natural Language Processing engines surface relevant clinical concepts including acronyms, shorthand, and jargon from unstructured clinical data.
- Contextualization – It is very important for a clinical NLP system to understand the context of what a doctor is writing about. For instance, if a doctor discusses the patient’s history, his/her family history, etc., the clinical NLP system should be able to detect it.
- Knowledge Graph – It encodes clinical concepts (entities) and their relationship to one another.

Uses of Clinical NLP
Let’s discuss the top uses of Clinical NLP in improving patient care.
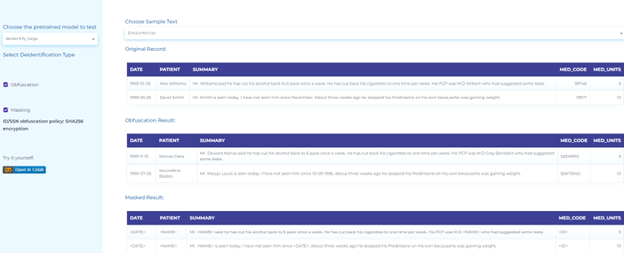
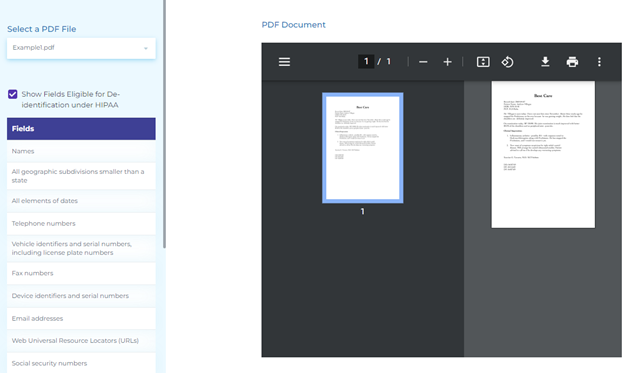
Deidentification
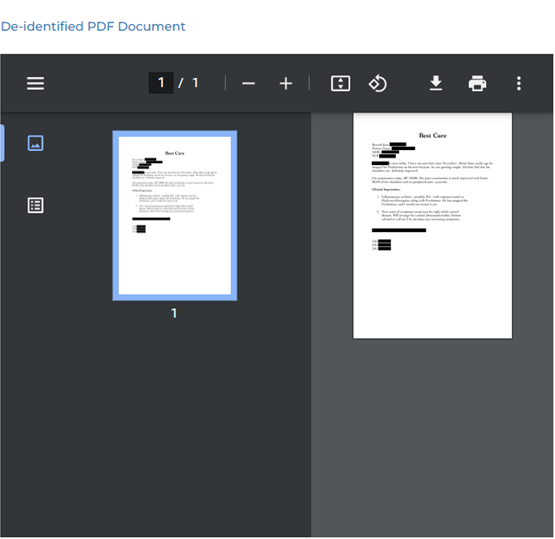
Deidentification safeguards the confidentiality of people. A document or record can’t be considered de-identified if it includes any personal data that allows the individual to be re-identified, i.e., personal identity can be inferred from the document.
Below are the notable uses of Natural Language Processing for clinical data de-identification.
- Identification of personal and clinical information such as date, doctor, hospital, ID number, medical record, patient name, age, profession, organization, state, city, country, street, username, zip code, phone number in clinical documents.

- De-identification of protected health information in English, Spanish, French, Italian, Portuguese, Romanian, and German texts.

- De-identification of protected health information in English, Spanish, French, Italian, Portuguese, Romanian, and German texts.
- PHI de-identification of information from structured datasets while ensuring GDPR and HIPAA compliance, and maintaining linkage of clinical data across files.

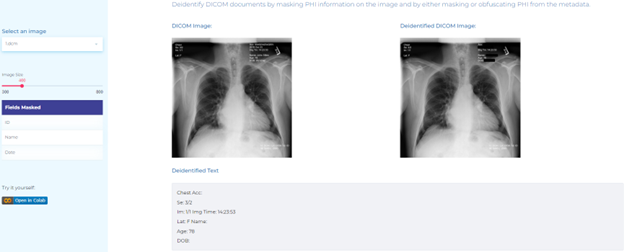
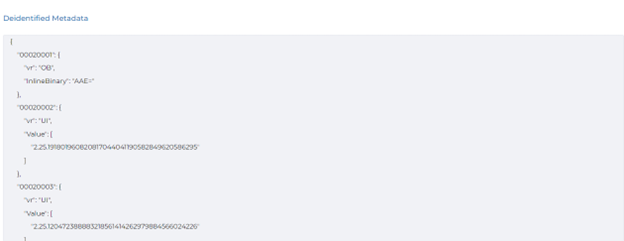
- De-identification of DICOM DICOM (Digital Imaging and Communications in Medicine) defines a set of protocols for formatting and exchanging medical images and associated data, including patient information, diagnostic information, and other metadata. DICOM documents are a standard format for medical imaging files, such as X-rays, MRIs, and CT scans. They store, transmit, and manage medical images along with other related information.


The benefit of deidentifying DICOM documents is to protect patients’ privacy and comply with regulations like HIPAA. Deidentification removes/replaces any identifiable patient information, such as name, address, and medical record number, from the DICOM documents before they are shared with other healthcare providers or researchers.
- De-identification software for PDF documents using HIPAA (HIPAA de-identification standards), Health Insurance Portability and Accountability Act, is a federal law in the United States that was enacted in 1996. It includes regulations that establish national standards for the privacy and security of Protected Health Information (PHI), which is any information that can be used to identify an individual and relates to their past, present, or future health condition, treatment, or payment for healthcare services. The privacy regulations require that covered entities (such as healthcare providers, health plans, and healthcare clearinghouses) implement reasonable and appropriate administrative, physical, and technical safeguards to protect the confidentiality, integrity, and availability of PHI, and to limit its use and disclosure.

Diagnoses and Procedures
The notable uses of NLP in diagnoses and procedures are:
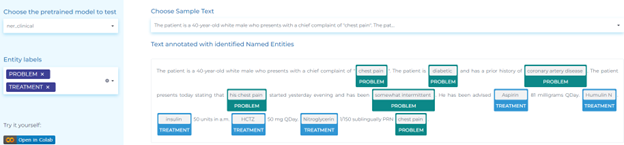
- Identifying diagnosis and symptoms – NLP automatically detects if a diagnosis or a symptom is present, absent, uncertain or associated with other persons (e.g. family members).

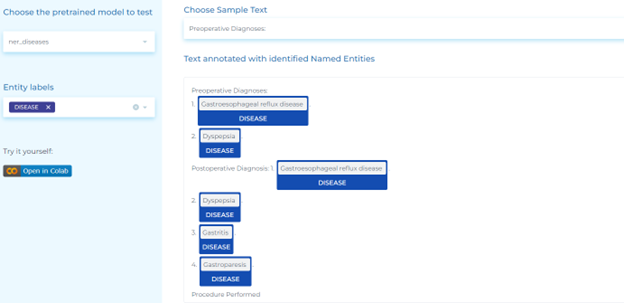
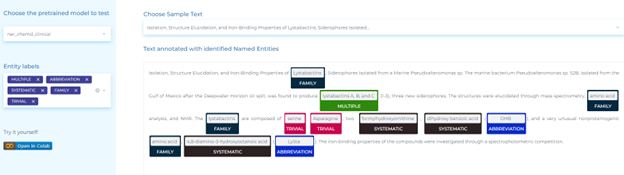
- Detecting clinical entities in text – Use the NER deep learning model to automatically detect more than 50 clinical entities in text.

- Detecting diagnosis and procedures – NLP automatically identifies diagnoses and procedures in clinical documents using various techniques. One common approach is use of NER algorithms that identify medical concepts, such as symptoms, diseases, and treatments in the text.

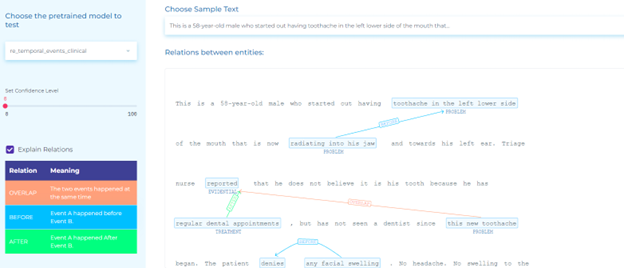
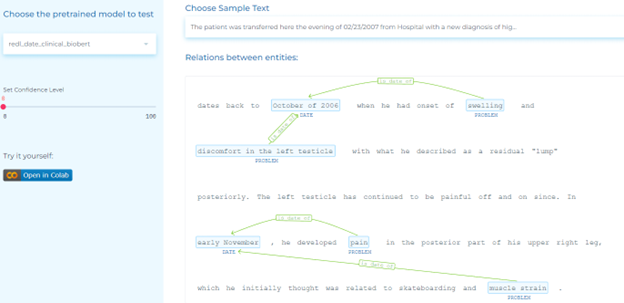
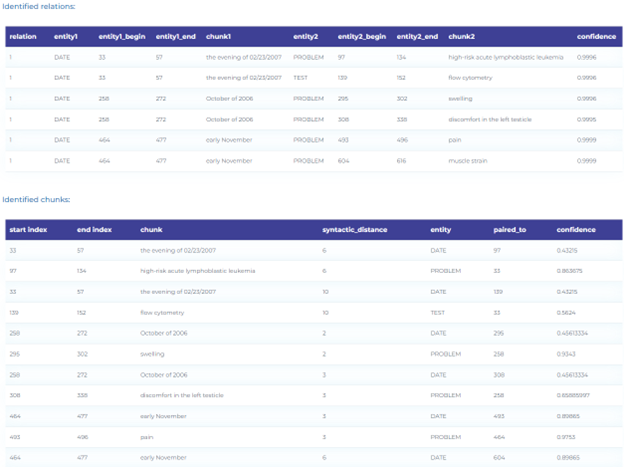
- Detecting temporal relations for clinical events – Automatically identify three types of relations between clinical events: After, Before and Overlap using the pre-trained clinical Relation Extraction (RE) model.


- Detecting causality between symptoms and treatment – Automatically identify relations between symptoms and treatment using the pre-trained clinical Relation Extraction (RE) model.


- Detecting relations between body parts and clinical entities using pre-trained relation extraction models.


- Detecting clinical entities such as problems, tests and treatments, and determining how they relate to specific dates.


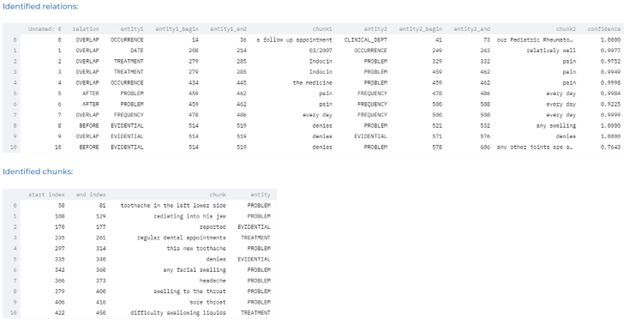

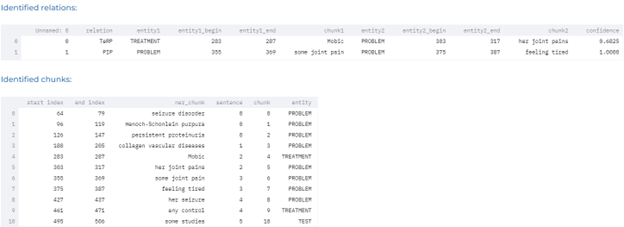
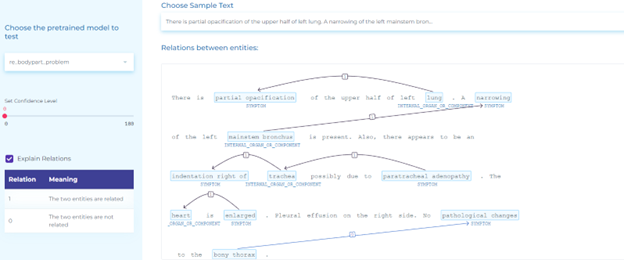
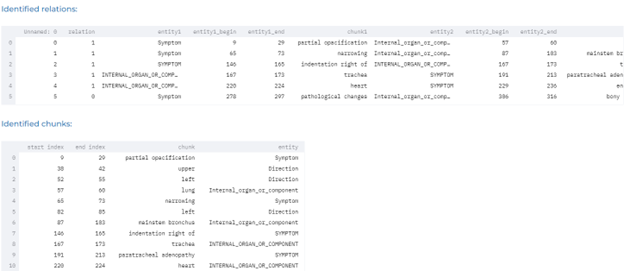
Drugs and Adverse Events
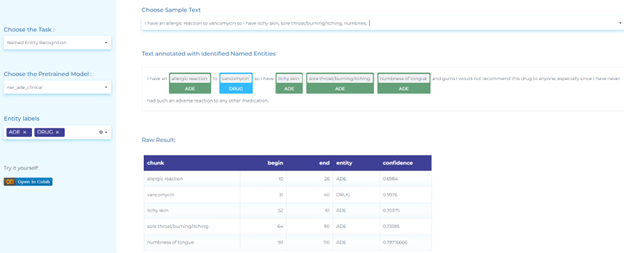
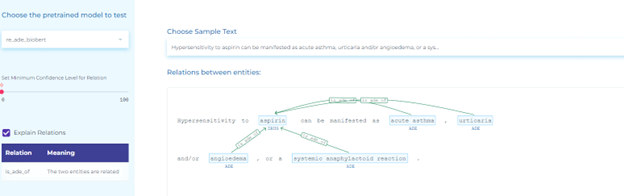
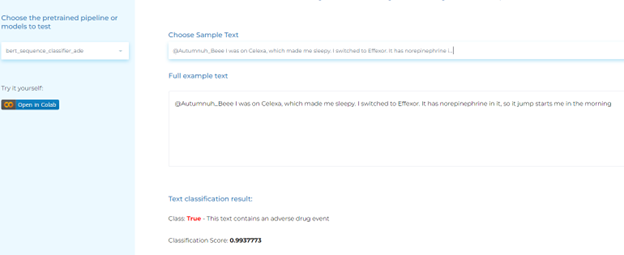
Healthcare companies use Natural Language Processing to automate the detection of Adverse Drug Reactions (ADR) or events (ADE) in unstructured text.
The top uses of NLP in detecting adverse drug events are:
-
- Detecting adverse reactions of drugs in reviews, tweets, and medical text using NLP tools such as Spark NLP, Healthcare NLP, Sequence Classification, Assertion Status, and Relation Extraction models.
- Detecting adverse reactions of drugs in reviews, tweets, and medical text using NLP tools such as Spark NLP, Healthcare NLP, Sequence Classification, Assertion Status, and Relation Extraction models.
-
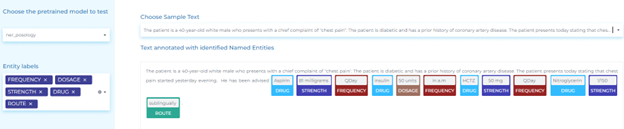
- Automatically identifying Drug, Dosage, Duration, Form, Frequency, Route, and Strength details in clinical documents.

- Automatically identifying relations between drugs, dosage, duration, frequency and strength using our pre-trained clinical Relation Extraction (RE) model.


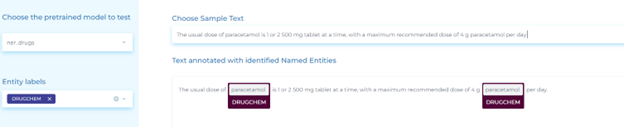
- Extracting drugs, chemicals and abbreviations.

- Detecting relations between drugs and adverse reactions caused by them.


- Extracting conditions and benefits from drug reviews using techniques such as NER.

- Automatically identifying Drug, Dosage, Duration, Form, Frequency, Route, and Strength details in clinical documents.
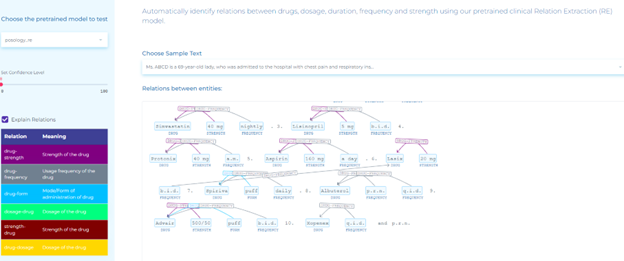
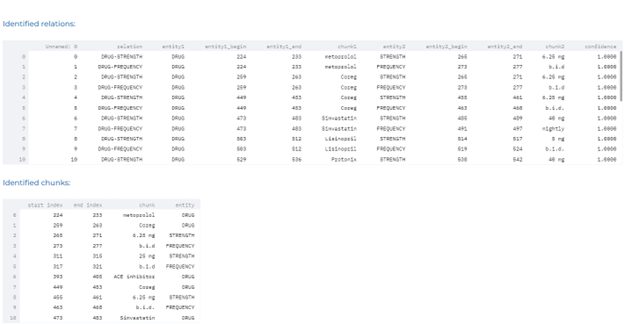
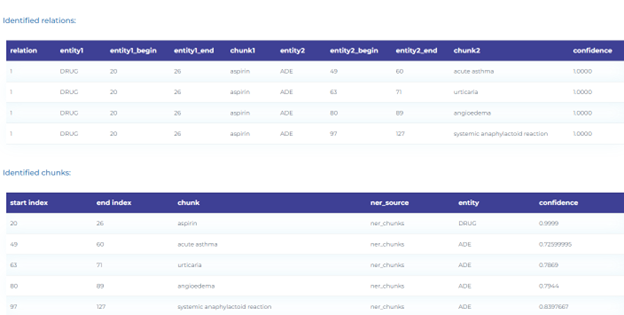

- Automatically identifying drug chemicals in clinical documents.

- Detecting ADE-related texts with a high degree of accuracy. A common approach is to train machine learning models on large datasets of annotated texts that indicate the presence of ADEs. The models can then be used to identify ADE-related texts by analyzing the language used and the context in which it appears.


- De-identification of PDF documents using GDPR guidelines by anonymizing PHI information.


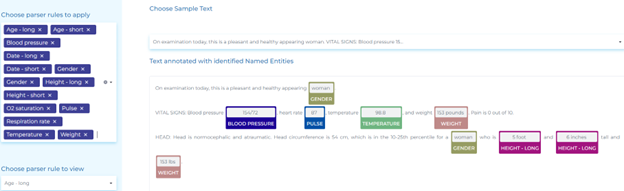
Labs, Tests, and Vitals
NLP automatically extracts key features from medical text records. Features include lab test results, symptoms, blood pressure data, patient height and weight, vitals, and much more.
The uses of NLP in extracting lab test results and vitals are:
- Automatically detecting demographic information as well as vital signs in medical text records.

- Identifying Lab test names and Lab results from clinical documents.

- Automatically identifying a variety of clinical events such as Problems, Tests, Treatments, Admissions or Discharges, in clinical documents.

- Identifying gender of a person by analyzing signs and symptoms.

- Extracting neurologic deficits related to NIH Stroke Scale (NIHSS).

- Identifying relations between scale items and measurements according to NIHSS.


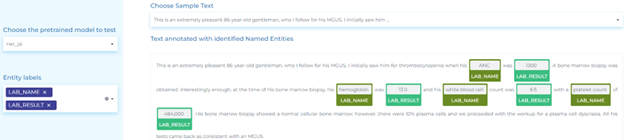
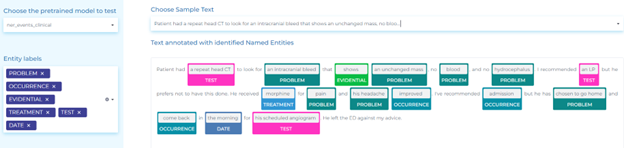
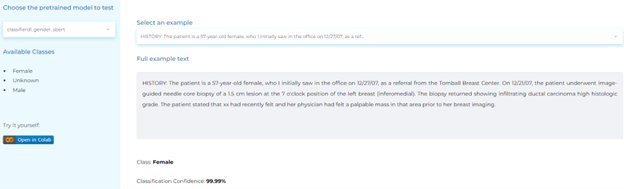
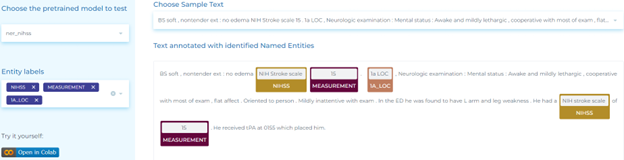

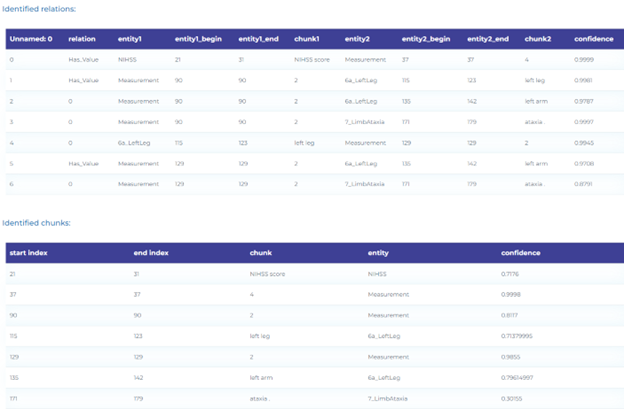
Analyze Clinical Notes
Clinical notes provide patient specific information including medication and procedures; and helps in predicting accurate scores. The top uses of NLP in analyzing clinical notes are:
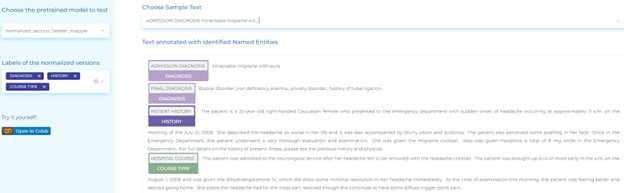
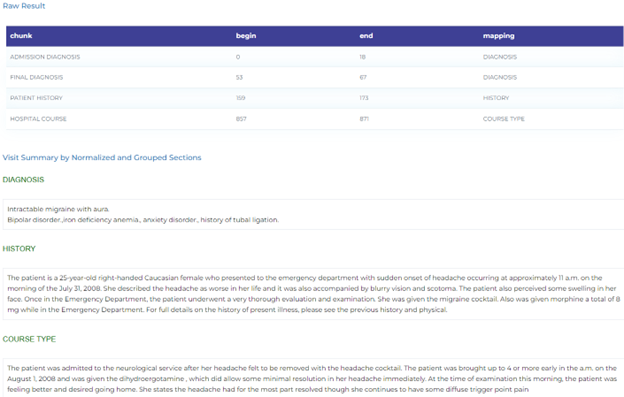
- Mapping section headers of the clinical visit data to their normalized versions.


- Mapping clinical abbreviations and acronyms to their meanings.

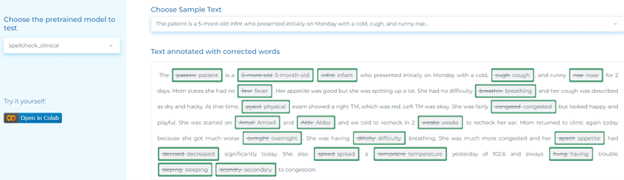
- Spell checking for clinical documents.

- Automatically detecting sentences in noisy healthcare documents with pretrained Sentence Splitter DL model.


- Finding available models for the clinical entities.

- Normalizing medication-related phrases such as dosage, form and strength, as well as abbreviations in text and named entities extracted by NER models.

- Automatically identifying anatomical system, cell, cellular component, anatomical structure, immaterial anatomical entity, multi-tissue structure, organ, organism subdivision, organism substance, pathological formation in clinical documents.

- Extracting chunk key phrases in medical texts.

- Recognizing clinical abbreviations and acronyms.

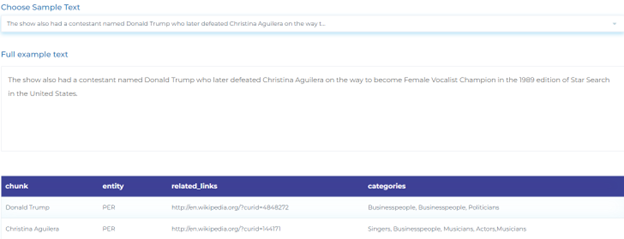
- Automatically disambiguating people’s names based on their context and linking them to corresponding Wikipedia pages.

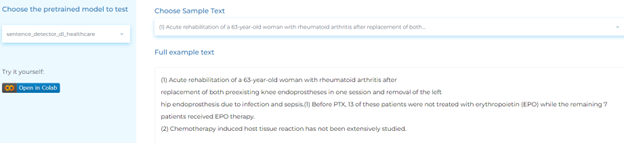

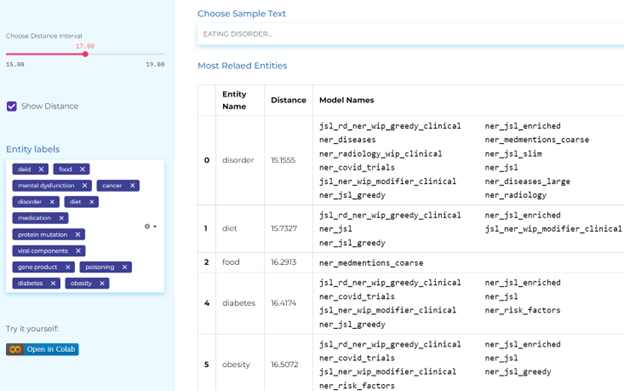
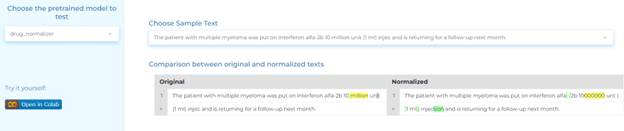
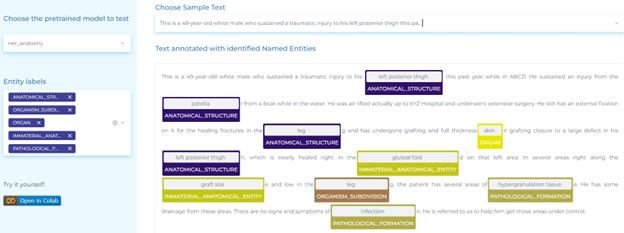
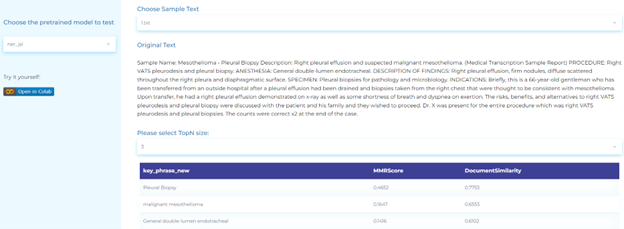

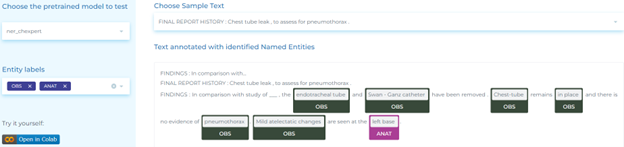
Radiology
NLP detects specific diagnoses within the context of radiology reports. It can be used to:
- Detect clinical entities in radiology reports.

- Detect anatomical and observation entities in chest radiology reports.

- Assign an assertion status (confirmed, suspected or negative) to image findings.

- Identify relations between problems, tests and findings.




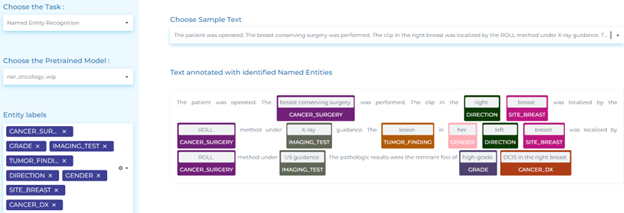
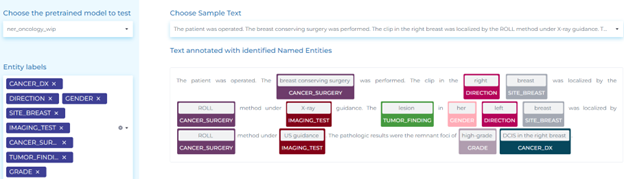
Oncology
Oncology records include various data points such as treatment information, clinical and pathological data, molecular profiling, and outcome.
NLP extracts meaningful outcomes from oncologist notes at scale. Its various uses are:
- Exploring oncology notes with Assertion Status, and Relation Extraction models.

- Identifying anatomical and oncology entities related to different treatments and diagnosis from clinical texts.

- Extracting entities from Pathology Tests, Imaging Tests, mentions of Biomarkers, and their results from clinical texts.

- Extracting demographic information, age, gender, and smoking status from oncology texts.

- Detecting the assertion status of entities related to oncology (including diagnoses, therapies, and tests).
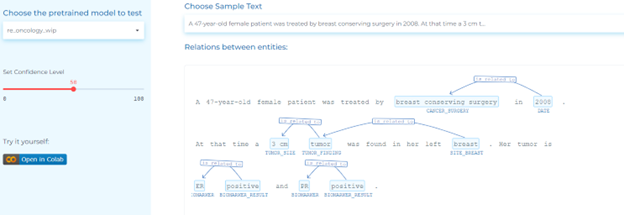
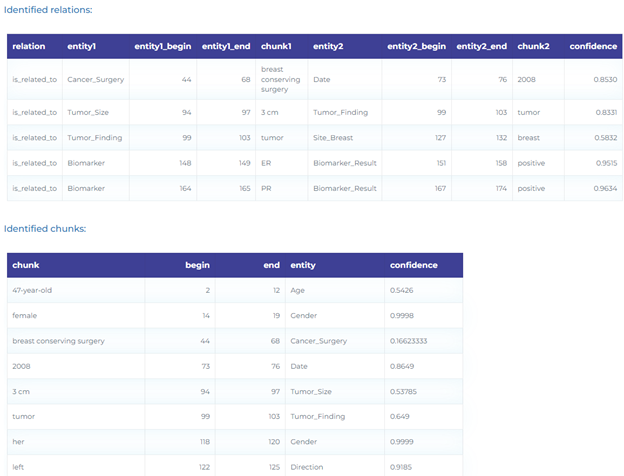
- Identifying relations between clinical entities, tumor mentions, anatomical entities, tests, biomarkers, anatomical entities, tumor size, tumor finding, date, and their corresponding using pre-trained oncology Relation Extraction models.


- Mapping oncology terminology to ICD-O codes using entity resolvers.




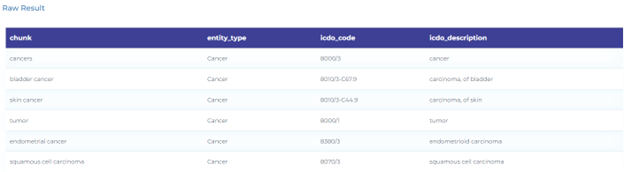
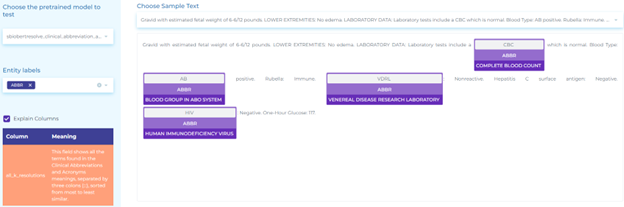
Resolve Entities to Terminology Codes
Below are the notable use cases of NLP in resolving entities to terminology codes.
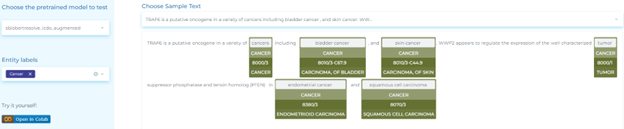
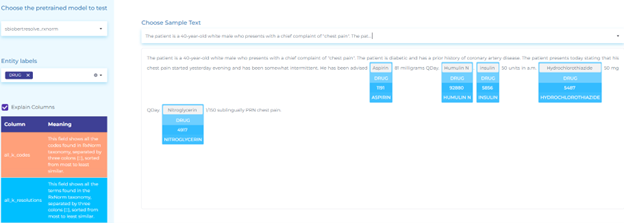
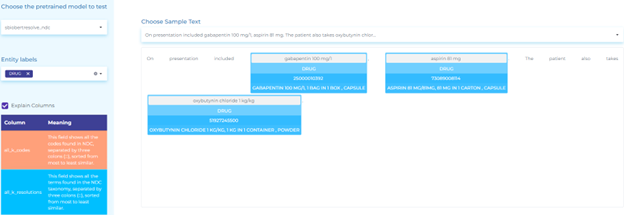
- Mapping clinical terminology to SNOMED (Systematized Nomenclature of Medicine) taxonomy. The figure below shows how healthcare information about procedures and measurements can be mapped to SNOMED codes using Entity Resolvers.


- Mapping clinical terminology to ICD-10-CM taxonomy. The figure below shows how to map clinical findings to ICD-10-CM codes using Entity Resolvers.


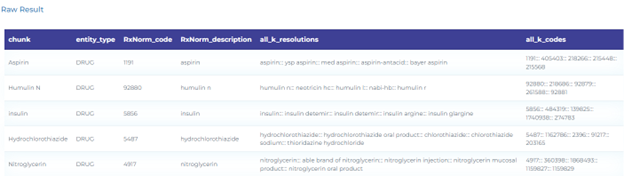
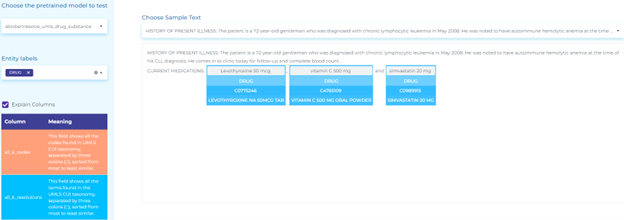
- Mapping drug terminology to RxNorm taxonomy.


- Mapping healthcare codes between taxonomies.

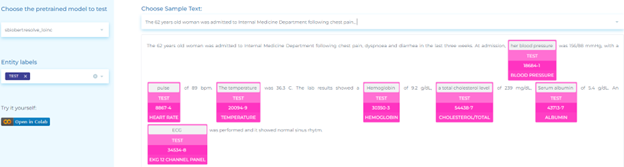
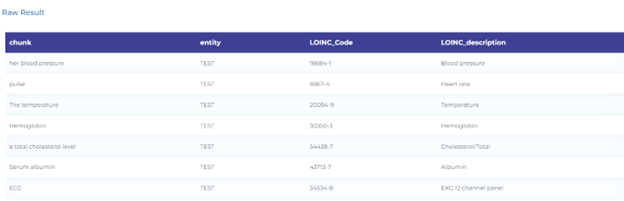
- Mapping laboratory terminology to LOINC taxonomy.


- Resolving Clinical Health Information using the HPO taxonomy.

- Resolving Clinical Health Information using the MeSH taxonomy.

- Resolving Clinical Findings using the UMLS CUI taxonomy.

- Resolving Clinical Health Information using the NDC taxonomy.
- Resolving Drug Class using RxNorm taxonomy.
- Resolving Drug and Substance using the UMLS CUI taxonomy.

- Resolving Clinical Procedures using CPT taxonomy.

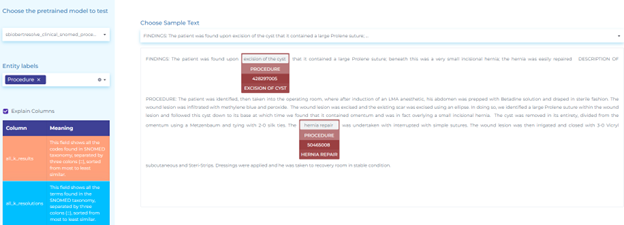

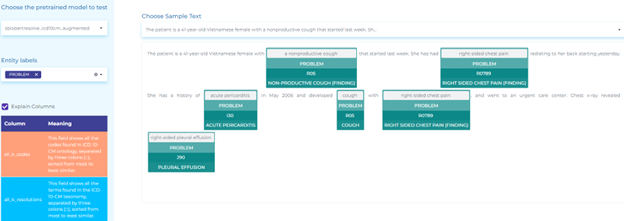
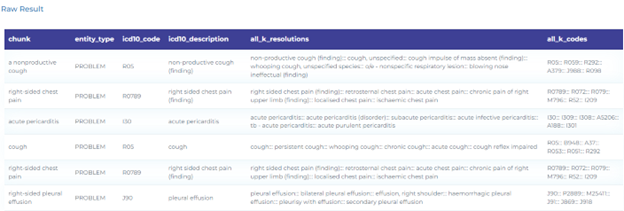


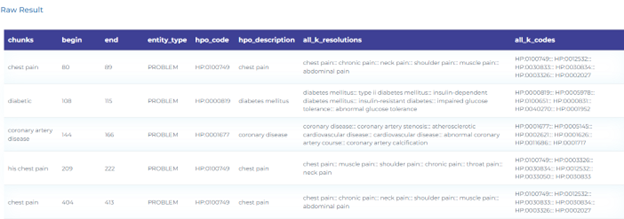
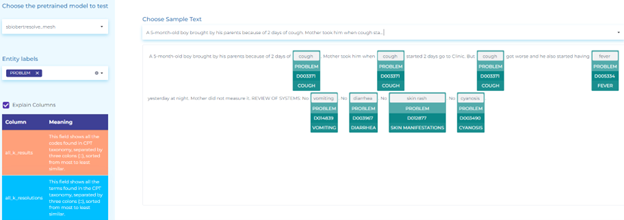

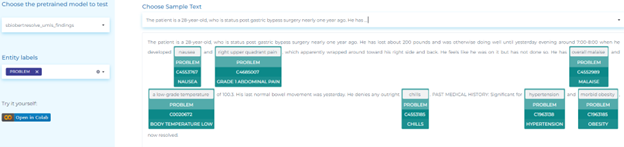
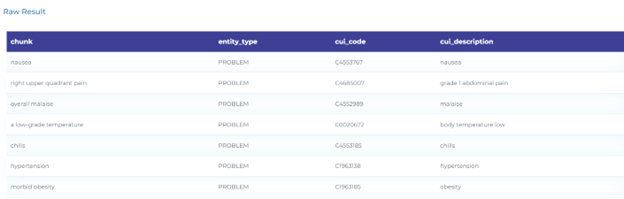






Vaccines and Public Health
NLP detects adverse drug events from clinical text, detects disease and classifies vaccination status from posts.
Following are its notable uses.
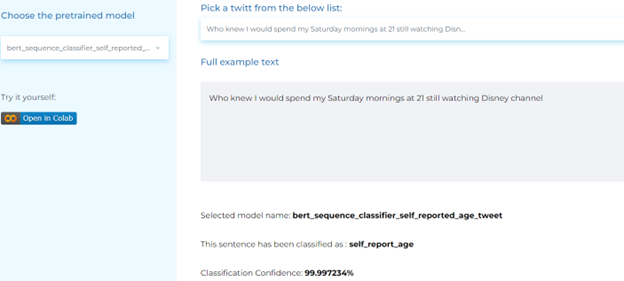
- Classifying self-reported age from posts.

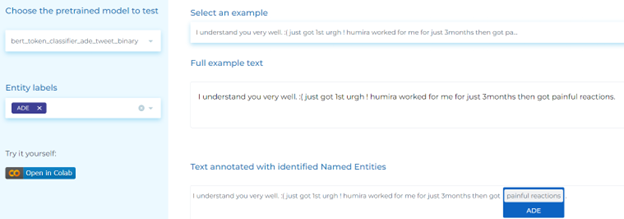
- Detecting adverse drug events from posts.
- Classifying self-reported COVID-19 symptoms from posts.

- Classifying stance about public health mandates from posts.
- Extracting disease entities in Spanish tweets.
- Classifying people non-adherent to their treatments and drugs on social media.

- Identifying self-reported COVID-19 vaccination status in English tweets.
- Classifying public health mentions in social media text.
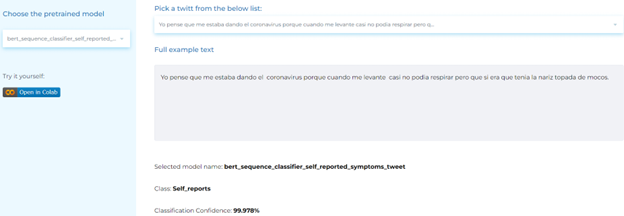
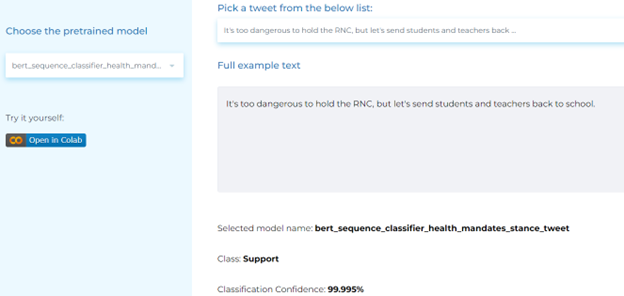
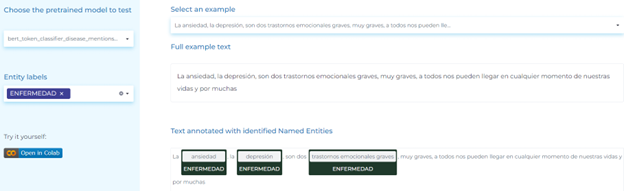
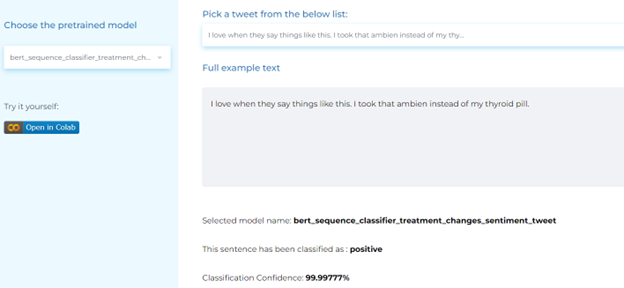
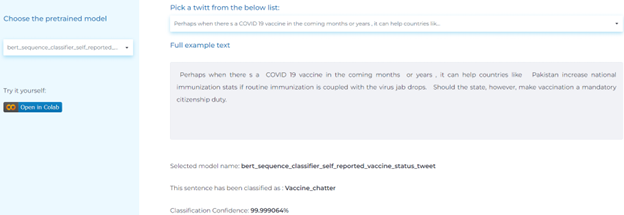
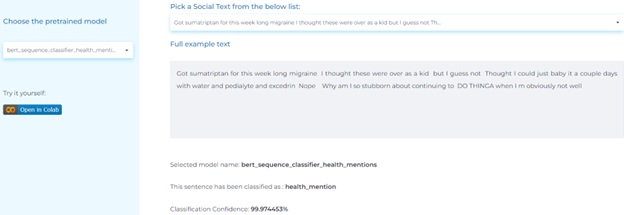
Mental Health
Below are the use cases of NLP in improving a patient’s mental health.
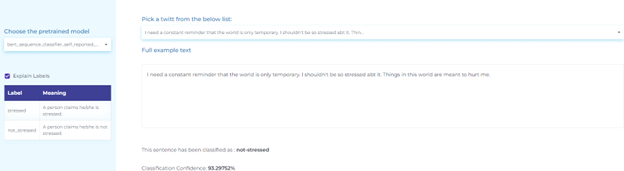
- Identifying depression from patient posts

- Identifying intimate partner violence from patient posts
- Identifying stress from patient posts

- Identifying the source of stress from patient posts

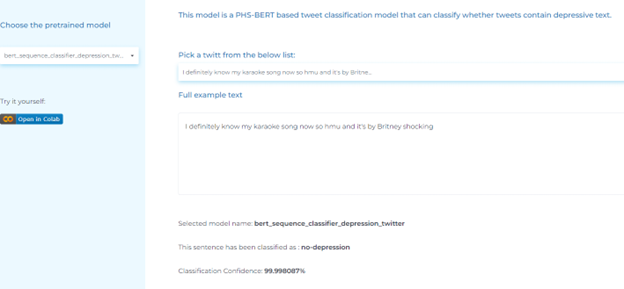
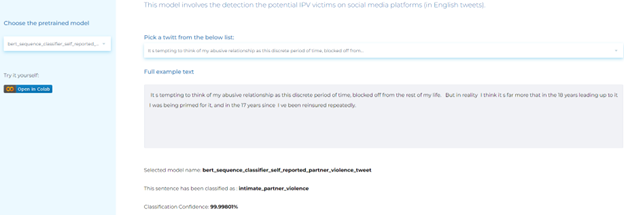
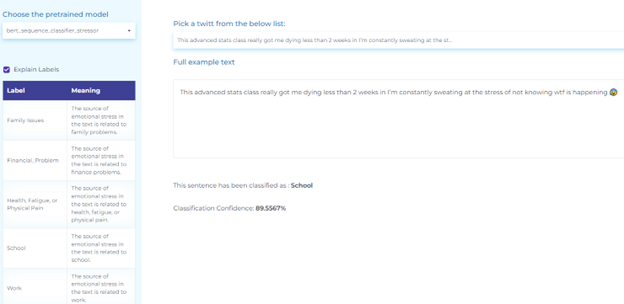
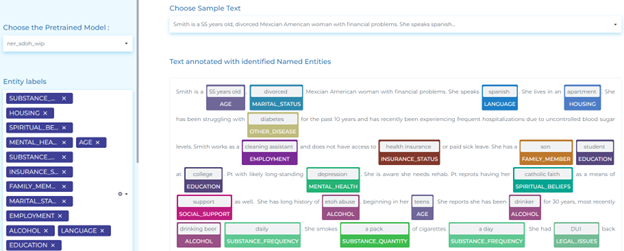
Social Determinant
The notable use cases of NLP in analyzing social determinants are given below.
- Detecting social determinants of health in medical text.

- Classifying social support in medical text.
- Detecting alcohol use in medical text.

- Classifying tobacco consumption in medical text.


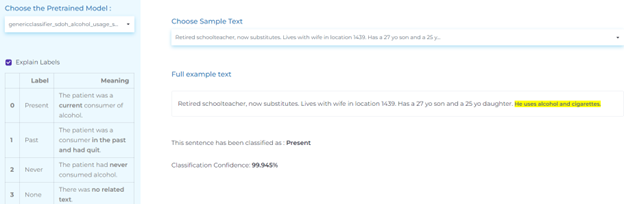
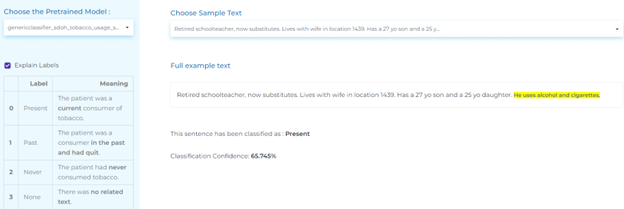
Risk Factors
The top uses of NLP in detecting risk factors are:
-
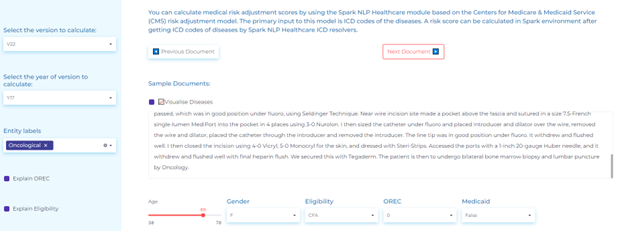
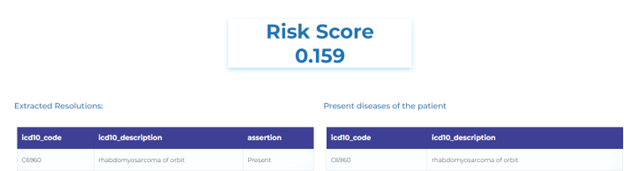
- Calculating medical risk adjustment scores automatically using icd codes of diseases.

- Automatically identifying risk factors such as coronary artery disease, diabetes, family history, hyperlipidemia, hypertension, medications, obesity, phi, smoking habits in clinical documents.
- Calculating medical risk adjustment scores automatically using icd codes of diseases.

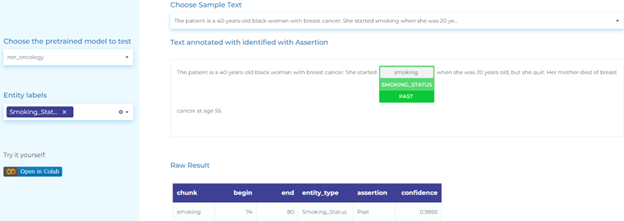
- Detecting smoking status entities from clinical text
Conclusion
Clinical NLP analyzes voluminous amounts of patient datasets and accurately gives voice to the unstructured data of the healthcare universe.
Without Healthcare Natural Language Processing, the unstructured data is of no use to modern computer-based algorithms. Clinical NLP saves the time and effort of physicians, and makes the information of use by:
- Using specialized engines that scrub large sets of unstructured data and discover improperly coded or previously missed patient conditions.
- Converting the data into a structured format so the health systems can classify patients and summarize their condition on arrival.
- Allowing physicians to extract critical insights rather than wasting time in reviewing complex EHRs.
John Snow Labs’ Healthcare NLP is an open source text processing NLP library for Python, Java, and Scala. It provides production-grade, scalable, and trainable versions of the latest research in Natural Language Processing.
It comes with 600+ pre-trained clinical pipelines and models out of the box and is performing way better than AWS, Azure and Google Cloud healthcare APIs on extracting medical named entities from clinical notes.
Get started here and see which Clinical NLP demo can be best applied to your use case.