






















































Efficiently anonymize PHI directly within Cursor, VS Code, and Claude Code using the new Model Context Protocol integration in Healthcare NLP 6.3.0.
TL;DR: John Snow Labs Healthcare NLP Release 6.3.0 introduces Model Context Protocol (MCP) servers for clinical de-identification. These servers allow AI agents (like Cursor and VS Code Copilot) to access state-of-the-art de-identification pipelines directly as tools. Instead of context switching to run scripts, you can now sanitize clinical text instantly within your IDE, maintaining strict privacy/HIPAA compliance with a local, secure execution environment.
AI coding assistants have fundamentally changed how we write code. However, for healthcare data scientists and engineers, there remains a significant friction point: accessing specialized clinical NLP capabilities.
General-purpose LLMs handling your code context often lack the specific training, regulatory compliance, and accuracy required to safely handle Protected Health Information (PHI). Typically, processing a clinical note means leaving the IDE, running a separate PySpark script or REST API call, and manually handling the results.
With Healthcare NLP Release 6.3.0, we are closing this gap. We have released official De-identification MCP Servers. These servers enable your favorite IDE to validly interact with industry-standard Spark NLP Healthcare de-identification pipelines, allowing developers to build safer healthcare applications faster.
What is MCP?
The Model Context Protocol (MCP) is an open standard that connects AI assistants to external systems. Instead of just pasting text into a chat window, MCP allowing the AI to “call” specialized tools that run locally or on your secure infrastructure.
For healthcare, this is a game-changer. It means your AI assistant can now “see” a clinical note and say, “I need to de-identify this before we proceed,” and then actually do it using a certified, locally running Healthcare NLP pipeline — without the data ever leaving your secure environment to go to a third-party model training API.
Two architectures for your workflow
We designed two architectures to fit different deployment needs: a lightweight client for speed and a monolithic server for simplicity.
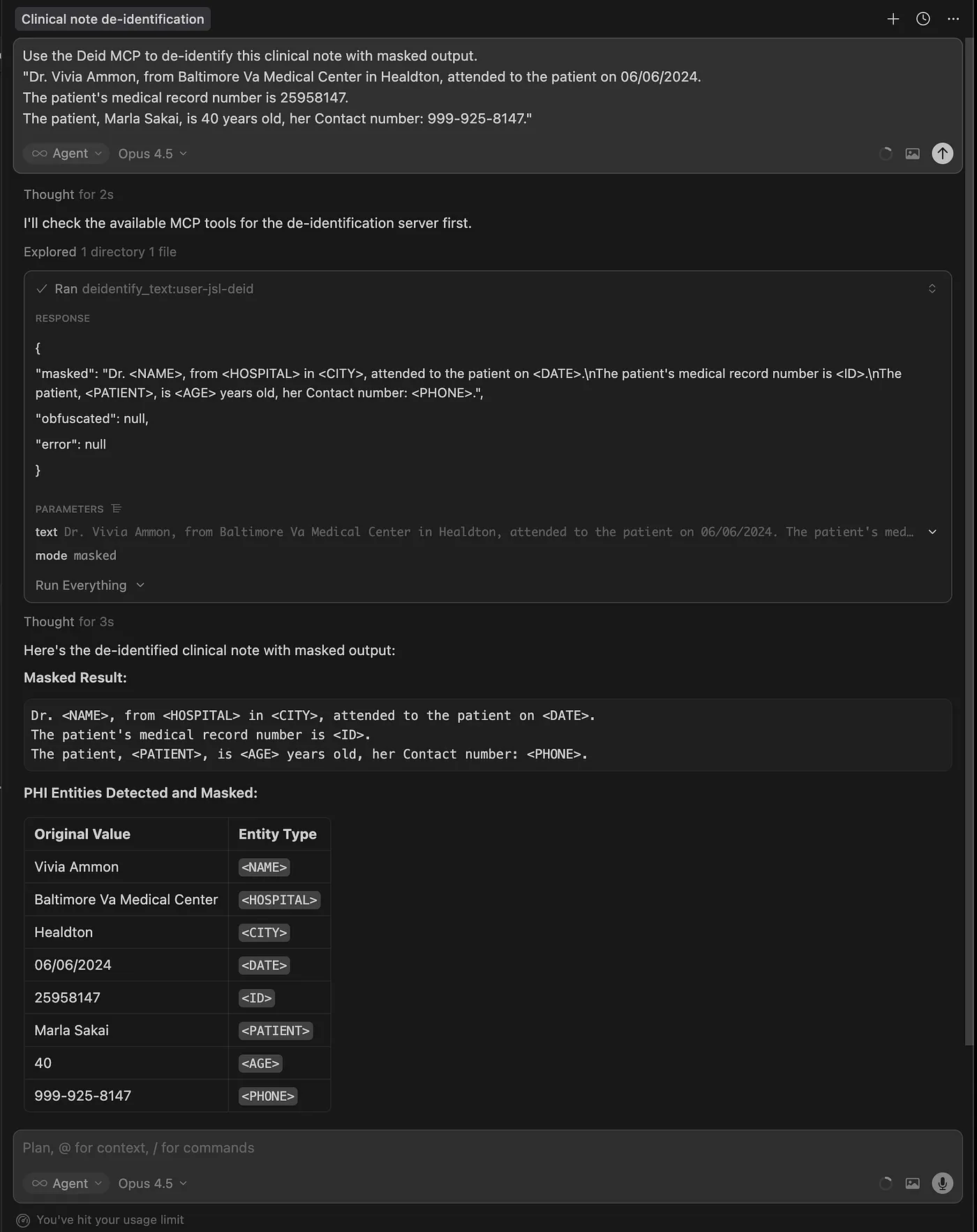
Cursor AI demo: De-identifying clinical text via MCP
Using in VS Code Copilot
In VS Code Copilot Chat, invoke the MCP tool:
Utilize the Deid MCP to anonymize this clinical note, employing both masked and obfuscated output modes. “Dr. John Lee, from Royal Medical Clinic in Chicago, attended to the patient on 11/05/2024…
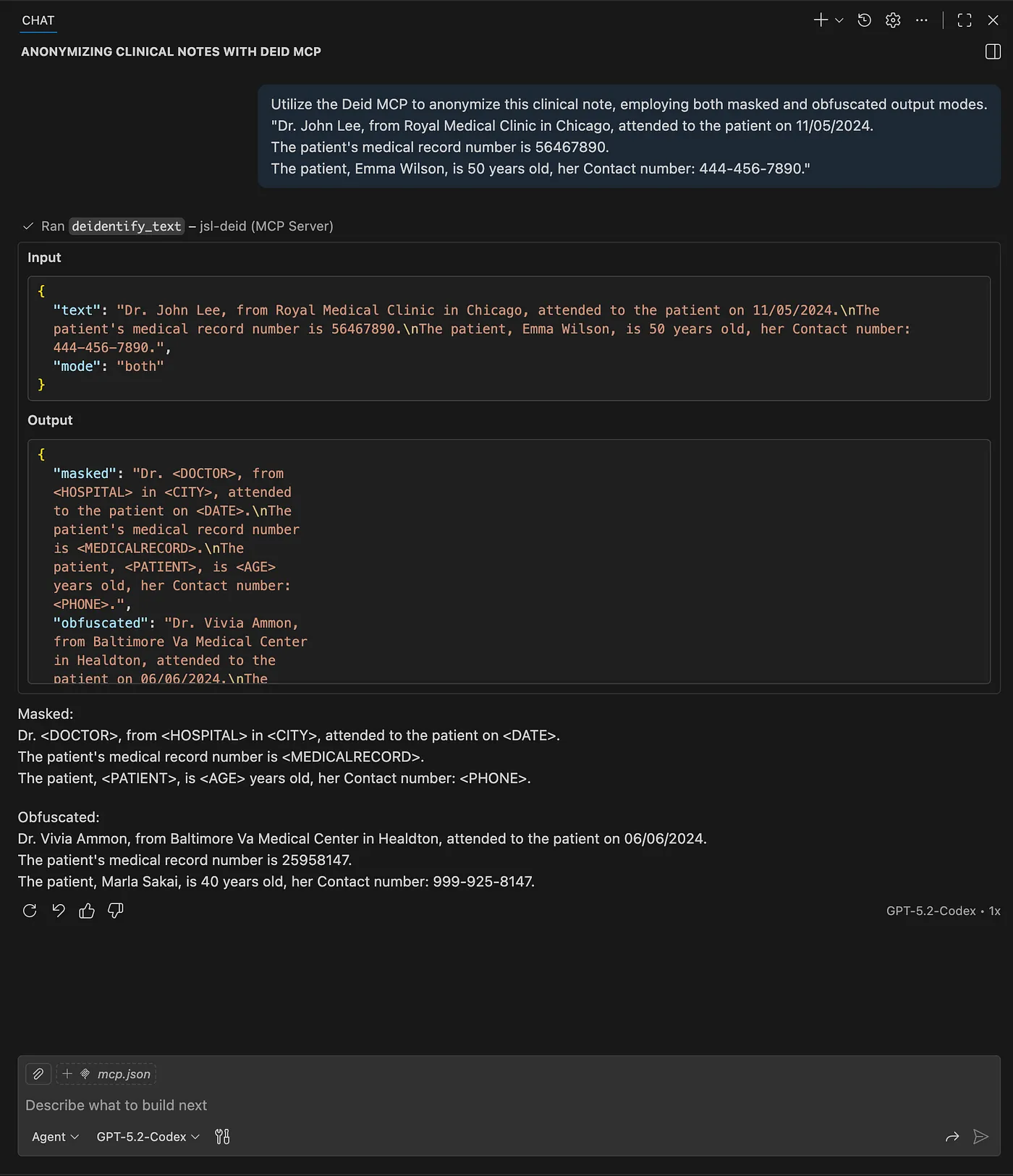
VS Code Copilot demo: De-identifying clinical text with both masked and obfuscated output
Supported PHI Entity Types
The pipeline detects and processes 30+ PHI entity types:
Personal Identifiers:
PATIENT,DOCTOR,USERNAMEAGE,DATESSN,DLN(Driver’s License),LICENSE
Contact Information:
PHONE,FAX,EMAIL,URL
Location Data:
HOSPITAL,CITY,STATE,COUNTRY,ZIPSTREET,LOCATION
Medical Identifiers:
MEDICALRECORD,HEALTHPLAN,ACCOUNTIDNUM,BIOID
Organization:
ORGANIZATION,PROFESSION
Vehicle/Device:
DEVICE,PLATE,VIN
The underlying pipeline is clinical_deidentification from Spark NLP Healthcare, which combines NER models, rule-based matchers, and contextual parsers for high-accuracy PHI detection.
Key design decisions
Privacy by Design: No PHI Logging
The servers log request metadata (text size, mode, latency) but never log clinical content:
# What we log
logger.info(f"Deidentify request: {len(text)} chars, mode={mode}")
logger.info(f"Deidentify completed: {elapsed_ms:.0f}ms")
# What we never log
# logger.info(f"Processing: {text}") # NEVER
Streamable HTTP Transport
We use FastMCP’s streamable_http_app() with uvicorn for IDE compatibility. This provides the HTTP-based transport that Cursor and VS Code Copilot expect.
Pipeline Warmup
On startup, the pipeline processes a sample text to trigger JVM JIT compilation and lazy initialization. This ensures consistent latency for actual requests. Without warmup, the first request can take 10–30 seconds. With warmup, typical latency is 100–500ms depending on text length.
What’s next
This de-identification MCP server is the first in a planned series of healthcare NLP tools for AI assistants. Future additions include:
- Data Curation MCP Server — Clinical entity extraction and structuring
- Medical Coding MCP Server — ICD-10, CPT code assignment
Resources
- GitHub Repository: https://github.com/JohnSnowLabs/spark-nlp-workshop/tree/master/agents/mcp_servers/deidentification
- Spark NLP Healthcare Documentation: nlp.johnsnowlabs.com
- JSL Deid Model Used: https://nlp.johnsnowlabs.com/2025/07/03/clinical_deidentification_docwise_benchmark_optimized_en.html
- MCP Protocol Specification: modelcontextprotocol.io
Try it
Clone the repository or simply download the folder containing the relevant code base,configure your license, and bring clinical de-identification to your IDE. The v2 architecture gets you started in under 10 minutes (with post-installation responses in less than a second). Alternatively, you can experiment with the same approach on any healthcare NLP model of your choice.
Healthcare NLP Models 6.3.0 — John Snow Labs




