The last blog (A Primer to EBM – Part [A]) introduced in brief the well-known healthcare research databases, their structure, and the steps followed to determine the best and most...
There is a continuous need for knowing the best and most recent line of treatment for every known medical condition. The cumulative experience over centuries and over different cultures yielded...
Although both Python and R are taking the lead as the best data science tools, we can still find a lot of blogs and articles discussing the eternal question "Python...
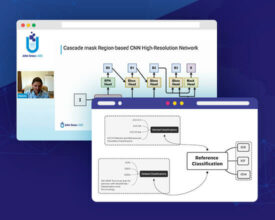
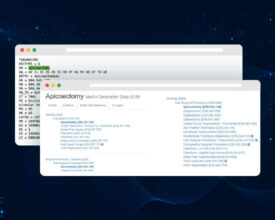
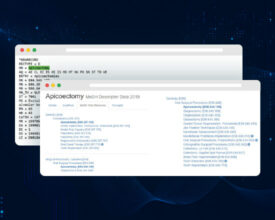
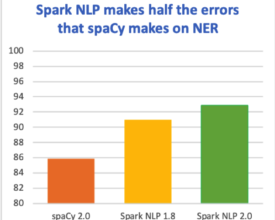
The latest major release merges 50 pull requests, improving accuracy and ease and use Release Highlights When we first introduced the natural language processing library for Apache Spark 18 months...







































































 See More
See More