
























































The proliferation of healthcare data has contributed to the widespread usage of the PICO paradigm for creating specific clinical questions from RCT. PICO is a mnemonic that stands for:
- Population/problem: Addresses the characteristics of populations involved and the specific characteristics of the disease or disorder.
- Intervention: Addresses the primary intervention (including treatments, procedures, or diagnostic tests) along with any risk factors.
- Comparison: Compares the efficacy of any new interventions with the primary intervention.
- Outcome: Measures the results of the intervention, including improvements or side effects.
PICO is an essential tool that aids evidence-based practitioners in creating precise clinical questions and searchable keywords to address those issues. It calls for a high level of technical competence and medical domain knowledge, but it’s also frequently very time-consuming.
Automatically identifying PICO elements from this large sea of data can be made easier with the aid of machine learning (ML) and natural language processing (NLP). This facilitates the development of precise research questions by evidence-based practitioners more quickly and precisely.
Empirical studies have shown that the use of PICO frames improves the specificity and conceptual clarity of clinical problems, elicits more information during pre-search reference interviews, leads to more complex search strategies, and yields more precise search results.
Information regarding the PICO classifier model in Spark NLP
Let’s have a look at how this model can accurately identify medical texts using the PICO framework as an example.
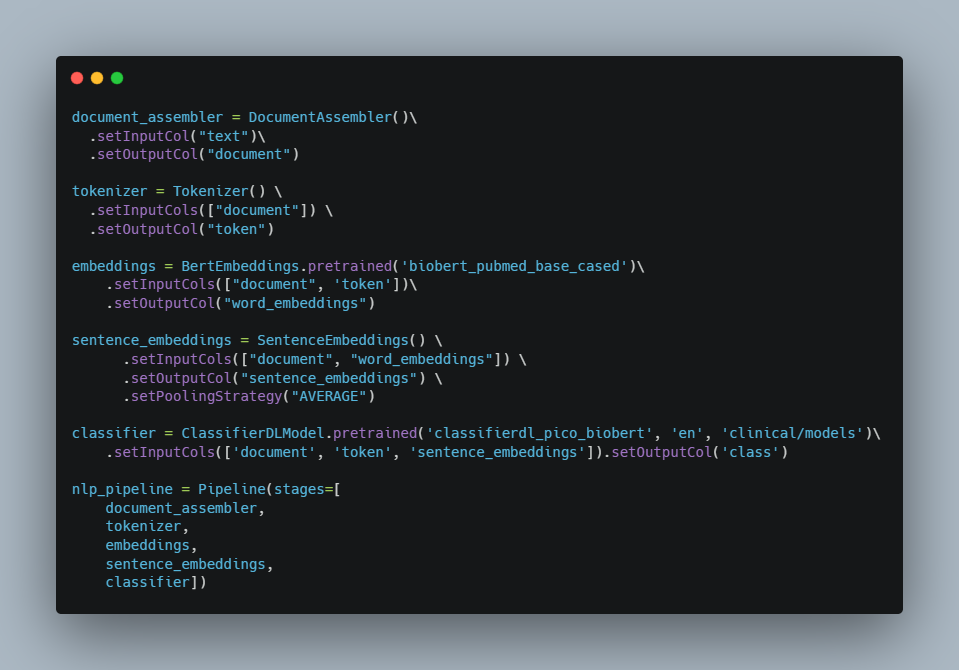
To get the word embeddings through BERT. We will use Spark NLP annotator called BertEmbeddings()
BertEmbeddings() annotator will take sentenceand token columns and populate Bert embeddings in bert column. In general, each token is translated into a 768-dimensional vector.
After that, we use SentenceEmbeddings which converts the results from WordEmbeddings, BertEmbeddings, or ElmoEmbeddings into a sentence or document embeddings by either summing up or averaging all the word embeddings in a sentence or a document (depending on the inputCols).
Now, let’s fit the pipeline and see the results.
Results:

Conclusion
We’ve discussed the significance of the PICO framework as well as how time-consuming, prone to human error, and requiring a lot of procedure and medical knowledge it can be. In addition, with the amount of pertinent health-care data being produced at an exponential rate, it has become more and more challenging to manually search for and identify PICO aspects. With far less human labour, practitioners can achieve good results by using Spark NLP to search the literature for PICO elements.
SparkNLP Resources
- Spark NLP documentation and Quick Start Guide
- Introducing Spark NLP: State of the art NLP Package
- Spark NLP 101: LightPipeline
- Text Classification in Spark NLP
- Spark NLP Named Entity Recognition (NER) with BERT




