
























































TL;DR:
Spark NLP’s upgraded Llama.cpp backend now supports a wider range of modern LLM families, including quantized and multimodal models. The integration delivers faster, memory-efficient inference and seamless Spark pipeline integration, letting users run the latest open models with minimal setup while maintaining Spark-scale performance. Spark NLP will continue to follow Llama.cpp updates, ensuring pipelines support the latest models and architectures as they become available.
Llama.cpp is a popular open‐source engine (in C/C++) designed to run large language models (LLMs) efficiently on commodity hardware. Its goal is “to enable LLM inference with minimal setup and state-of-the-art performance”. Since it’s self-contained and highly optimized (with support for ARM, x86 vector instructions, GPU kernels, etc.), Llama.cpp makes it much easier to do LLM inference on CPUs or edge devices than heavier frameworks. For example, it includes advanced quantization (1.5–8-bit) and multi‐architecture optimizations to dramatically cut memory use and speed up inference. These lightweight inference backends matter because they let teams run powerful LLMs without needing massive servers or GPUs. In practice, this means companies can deploy LLM features “on-premises at Spark-native scale” (even on laptops or small cloud instances).
Spark NLP has built on this trend: its new AutoGGUFModel (and related annotators) use Llama.cpp under the hood to load and run GGUF quantized models.
Expanded model support
Recent updates have dramatically expanded which LLMs Llama.cpp (and thus Spark NLP) can run. In Spark NLP’s recent 6.3.1 release, the team upgraded the Llama.cpp backend to newer versions and added compatibility for the latest model families:
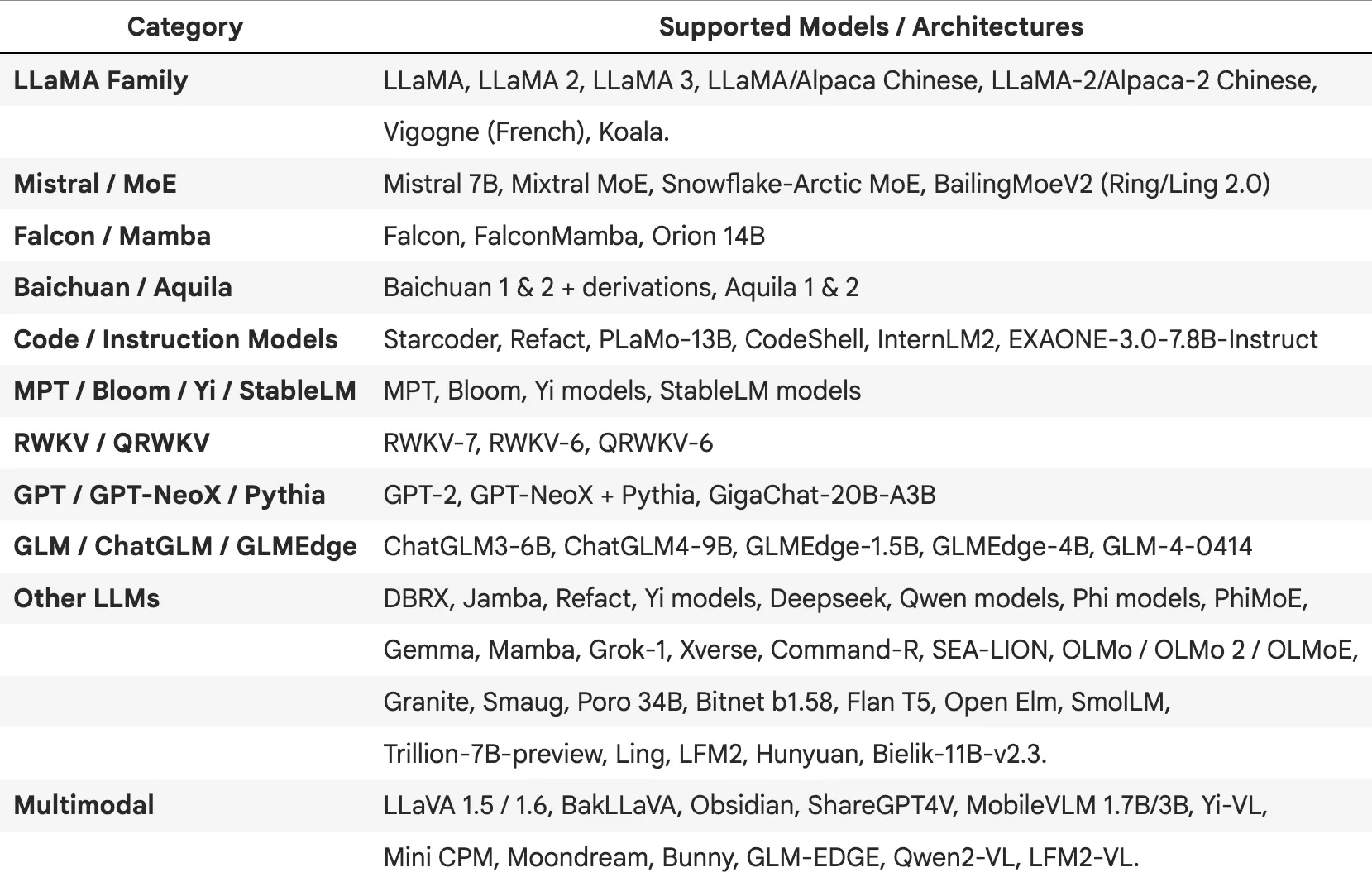
supported LLM architectures and multimodal models
Together, these additions mean that Spark NLP’s Llama.cpp backend now covers all the popular modern LLM families. By upgrading the Llama.cpp integration (to tag b7247 in Spark NLP 6.3.1), any new open model that Llama.cpp can run is immediately usable in Spark NLP.
Technical enhancements and performance gains
Several under-the-hood improvements deliver these capabilities. First, Spark NLP is keeping its Llama.cpp version up-to-date. As noted, version b7247 of Llama.cpp was adopted, which includes recent upstream support for models like gpt-oss, Qwen3/Qwen3-VL and embeddinggemma. This means Spark NLP inherits all Llama.cpp optimizations (from fast matrix math to tensor splitting).
Moreover, Llama.cpp itself is engineered for speed on various hardware. It uses CPU vector instructions (AVX/ARM NEON), hybrid CPU+GPU modes, and efficient memory layouts. This translates to significantly faster inference on CPUs for Spark NLP customers. While specific benchmarks vary by model, hardware, and quantization level, users generally report substantial speedups compared to full-precision models. In short, the Llama.cpp upgrades mean faster replies and lower RAM use for the same tasks.
Another technical enhancement is ease of model loading. Llama.cpp supports the GGUF model format and HuggingFace model downloads. Spark NLP’s AutoGGUFModel abstracts this: users can simply name a pretrained GGUF model and Spark NLP will invoke Llama.cpp to load it. For example, the default is a “Phi_4_mini_instruct_Q4” model, which Spark NLP will load with all optimized settings if no model is specified. The backend also now properly manages resources (like freeing GPU memory when done) and handles new decoding tricks (e.g. speculative top-k sampling).
Benefits for Spark NLP pipelines
High Performance: Smaller LLMs like Mistral or Gemma can match bigger models’ accuracy, so pipelines run faster. For instance, generating a summary or translation via a quantized LLM can be significantly quicker on a CPU than a full-precision model. Spark NLP also finds that moving from TensorFlow-based inference to Llama.cpp gives substantial speed gains. This means more throughput in data pipelines, less cloud cost, and the ability to run on cheaper machines.
Low Memory Footprint: Quantized GGUF models can be several times smaller than original checkpoints. The Llama.cpp integration ensures Spark NLP pipelines only load what’s needed. This allows running 7B and even 13B models on machines with 16–32GB RAM, whereas before you might have needed hundreds of GB. However, it’s important to understand the quantization tradeoff: while lower-bit quantization (e.g., 4-bit vs 8-bit) yields smaller models and faster inference, it can also lead to quality degradation in some tasks. The degree of impact depends on the model architecture and use case. Most users find that 4-bit or 8-bit quantization offers an excellent balance between performance and accuracy, though critical applications may warrant testing different quantization levels to ensure output quality meets requirements.
Seamless Integration: Spark NLP annotators like AutoGGUFModel plug directly into Spark ML pipelines. You can combine them with standard stages (tokenizers, embeddings, etc.) just like any Spark ML model. For example, inference with Qwen3 is as easy as:
from sparknlp.base import DocumentAssembler
from sparknlp.annotator import AutoGGUFModel
from pyspark.ml import Pipeline
document_assembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
llm = AutoGGUFModel.pretrained("qwen3_4b_q4_k_m_gguf", "en") \
.setInputCols(["document"]) \
.setOutputCol("qwen_output")
pipeline = Pipeline().setStages([document_assembler, llm])
data = spark.createDataFrame([
["A farmer has 17 sheep. All but 9 run away. How many sheep does the farmer have left?"]
]).toDF("text")
result = pipeline.fit(data).transform(data)
result.select("qwen_output.result").show(truncate=False)
# Output:
# The phrase "all but 9 run away" means that 9 sheep did not run away, while the remaining (17 - 9 = 8) did. Therefore, the farmer still has the 9 sheep that stayed behind.
# Answer: 9.
Import your own GGUF models into Spark NLP
You can also use your own .gguf models by calling .loadSavedModel() instead of .pretrained() on AutoGGUFModel.
# Download a GGUF model from Huggingface
!wget -c https://huggingface.co/MaziyarPanahi/gemma-2b-it-GGUF/resolve/main/gemma-2b-it.Q8_0.gguf \
-O gemma-2b-it.Q8_0.gguf
document_assembler = (
DocumentAssembler()
.setInputCol("text")
.setOutputCol("document")
)
auto_gguf_model_loaded = (
AutoGGUFModel.loadSavedModel("gemma-2b-it.Q8_0.gguf", spark) # this line is all you needed to change
.setInputCols(["document"])
.setOutputCol("llm_output")
.setSystemPrompt("You are a story writing assistant.")
.setNPredict(-1)
)
prompt = spark.createDataFrame([["Write a story about llamas"]]).toDF("text")
pipeline = Pipeline().setStages([document_assembler, auto_gguf_model_loaded])
result = pipeline.fit(data).transform(data)
print(result.select("llm_output.result").first().result[0])
# Output:
# In the high Andes mountains of Peru, there lived a herd of llamas known for their soft wool and gentle nature. Every morning, they would graze on the lush grass near the crystalline streams, their long necks swaying gracefully as they moved across the mountainside.
# Among them was Luna, a young llama with unusually bright eyes and a curious spirit. Unlike her companions who were content to stay near familiar paths, Luna loved to explore the hidden valleys and discover new grazing spots. Her adventurous nature often led the herd to the most beautiful meadows filled with wildflowers.
# One day, Luna discovered a lost traveler struggling in the mountain pass. Without hesitation, she guided him down the safe paths to her village, where the grateful farmers welcomed him. From that day on, Luna became known as the guardian llama of the mountains, watching over both her herd and any travelers who needed help finding their way home.
And if you cant find a pre converted GGUF model on Huggingface or Spark NLP use the following notebook to convert it:
Convert Huggingface → GGUF → Spark NLP
Use cases and alignment with Spark NLP goals
With these models, Spark NLP pipelines can tackle tasks that were hard before. For instance, Mistral’s efficiency and long-context attention make it great for document summarization. Gemma’s multimodal nature enables image+text Q&A or detailed image captioning at scale. Phi-2’s reasoning strengths suit it to knowledge-work pipelines (legal document analysis, medical Q&A, etc.). By supporting these LLMs on Spark, teams can build complex NLP pipelines to generative analytics entirely within their Spark workflows.
Spark NLP aims to democratize NLP and ML in big data. Upgrading Llama.cpp fits perfectly: it expands the open-model catalog and boosts performance at scale. As Spark NLP notes, its goal is “unlocking NLP at Spark scale”. The ability to run dozens of new open-source models (over 135,000+ are now available in the Spark NLP Hub) without extra infrastructure is key to that vision. Lightweight backends like Llama.cpp are an essential tool in this strategy.
Real-World examples
In practice, data teams are already using these models in pipelines. For example, a call center might build a pipeline that uses Mistral to auto-summarize transcripts: Spark NLP handles the document ingestion and tokenization, then an AutoGGUFModel stage loads Mistral to generate concise summaries of each call. Researchers have built medical dialog summarizers by fine-tuning Gemma or Phi models and running them with Llama.cpp. On the vision side, teams are combining image readers with Gemma3 multimodal annotators to do large-scale visual analysis (e.g. scanning documents, images, and generating reports all in one pass). In all cases, the Spark NLP integration means these models run distributed across a cluster, with no custom serving code needed.
Conclusion
The Spark NLP 6.3.1 release demonstrates the power of upgrading the Llama.cpp backend to the latest version. This update expands compatibility across all major modern LLM families, including quantized and multimodal models, while maintaining fast, memory-efficient inference on commodity hardware. By integrating these enhancements into AutoGGUFModel and related annotators, Spark NLP users can immediately leverage new open models with minimal setup. Looking ahead, Spark NLP will continue to track Llama.cpp developments, ensuring ongoing support for the latest models and architectures. This commitment guarantees that Spark NLP pipelines remain cutting-edge, scalable, and ready to run the newest LLM innovations as they emerge, keeping teams at the forefront of high-performance, Spark-native NLP.
Useful resources
- Spark NLP 6.3.1 Release Notes
- Colab Notebook Covering GGUF Annotators in Spark NLP: 23.1.Native_GGUF_Models_in_SparkNLP.ipynb
- Colab Notebook for Converting Models to GGUF: Convert Hugging Face models to GGUF for Spark NLP
- AutoGGUFModel Guide: Details on loading pretrained and custom GGUF models
- Spark NLP Hub: Browse available pretrained LLMs, including quantized and multimodal models
- Llama.cpp GitHub Repository: Official repository for Llama.cpp, including source code, releases, and supported models
- GitHub Repository: Spark NLP on GitHub: Source code, issue tracking, and community contributions.
Join the Community
- Slack: Join the Spark NLP community and team for live discussions.
- Discussions: Engage with community members, share ideas, and showcase how you use Spark NLP!
- Medium: Read Spark NLP articles on its official Medium page.
- YouTube: Watch Spark NLP video tutorials for in-depth guidance.




