
























































Extract Hidden Insights from Texts at Scale with Spark NLP

Information extraction in natural language processing (NLP) is the process of automatically extracting structured information from unstructured text data. Spark NLP has many solutions for identifying specific entities from large volumes of text data, and converting them into a structured format that can be analyzed and used for subsequent applications.
Information extraction is a subfield of NLP that involves the automated identification and extraction of structured information from unstructured or semi-structured text data. The goal of information extraction is to transform unstructured text data into structured data that can be easily analyzed, searched, and visualized.
2.5 quintillion bytes of data (10 to the power 18 or billion billion) are generated everyday, ranging from social media posts to scientific literature, so information extraction has become an essential tool for processing this data. As a result, many organizations rely on Information Extraction techniques to use solid NLP algorithms to automate manual tasks.
Information extraction involves identifying specific entities, relationships, and events of interest in text data, such as named entities like people, organizations, dates and locations, and converting them into a structured format that can be analyzed and used for various applications. Information extraction is a challenging task that requires the use of various techniques, including named entity recognition (NER), regular expressions, and text matching, among others. There is a wide range of applications involved, including search engines, chatbots, recommendation systems, and fraud detection, among others, making it a vital tool in the field of NLP.
TextMatcher and BigTextMatcher are annotators that are used to match and extract text patterns from a document. The difference between them is, BigTextMatcher is designed for large corpora.
TextMatcher works by defining a set of rules that specify the patterns to match and how to match them. Once the rules are defined, TextMatcher can be used to extract the matched text patterns from the dataset.
In this post, you will learn how to use Spark NLP to perform information extraction efficiently. We will discuss identifying keywords or phrases in text data that correspond to specific entities or events of interest by the TextMatcher or BigTextMatcher annotators of the Spark NLP library.
Let us start with a short Spark NLP introduction and then discuss the details of the information extraction techniques with some solid results.
Introduction to Spark NLP
Spark NLP is an open-source library maintained by John Snow Labs. It is built on top of Apache Spark and Spark ML and provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment.
Since its first release in July 2017, Spark NLP has grown in a full NLP tool, providing:
- A single unified solution for all your NLP needs (for Clinical needs or biomedicine, or as a financial tool, etc.)
- Transfer learning and implementing the latest and greatest SOTA algorithms and models in NLP research
- The most widely used NLP library for Java and Python in industry (5 years in a row)
- The most scalable, accurate and fastest library in NLP history
Spark NLP comes with 14,500+ pretrained pipelines and models in more than 250+ languages. It supports most of the NLP tasks and provides modules that can be used seamlessly in a cluster.
Spark NLP processes the data using Pipelines, structure that contains all the steps to be run on the input data:
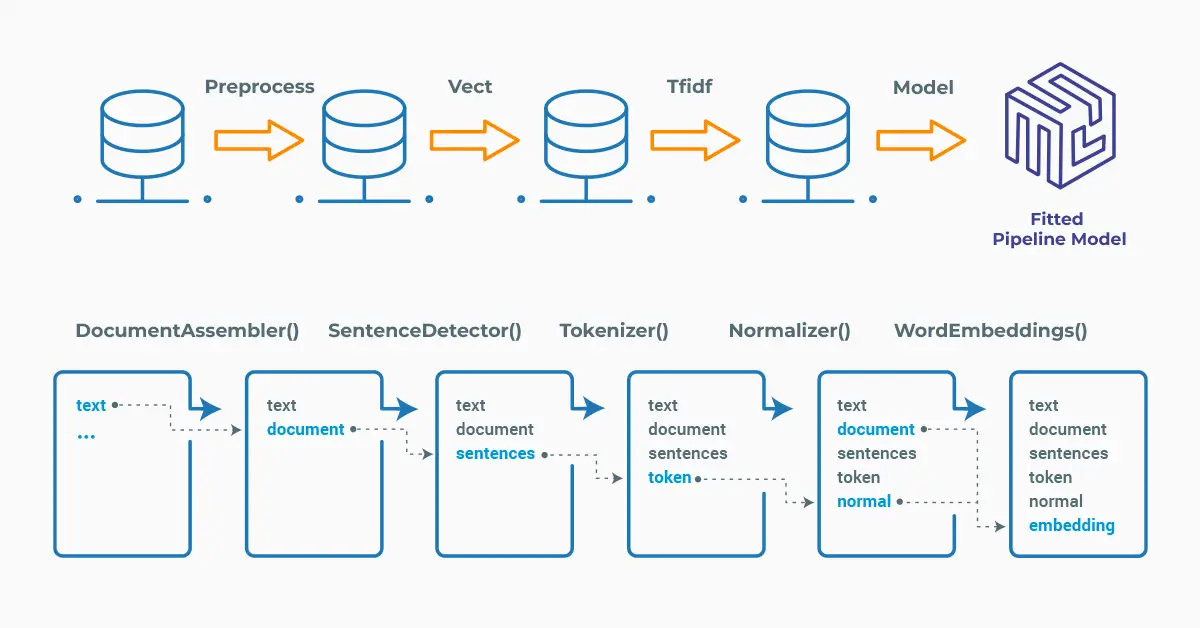
Each step contains an annotator that performs a specific task such as tokenization, normalization, and dependency parsing. Each annotator has input(s) annotation(s) and outputs new annotation.
An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. An annotator takes an input text document and produces an output document with additional metadata, which can be used for further processing or analysis. For example, a named entity recognizer annotator might identify and tag entities such as people, organizations, and locations in a text document, while a sentiment analysis annotator might classify the sentiment of the text as positive, negative, or neutral.
Setup
To install Spark NLP in Python, simply use your favorite package manager (conda, pip, etc.). For example:
!pip install spark-nlp !pip install pyspark
For other installation options for different environments and machines, please check the official documentation.
Then, simply import the library and start a Spark session:
import sparknlp # Start Spark Session spark = sparknlp.start()
TextMatcher
TextMatcher is an annotator of Spark NLP, which means that it operates by matching exact phrases (by token) provided in a file against a document.
TextMatcher expects DOCUMENT and TOKEN as input, and then will provide CHUNK as output. Here’s an example of how to use TextMatcher in Spark NLP to extract Person and Location entities from unstructured text. First, let’s create a dataframe of a sample text:
# Create a dataframe from the sample_text
data = spark.createDataFrame([
["As she traveled across the world, Emma visited many different places
and met many fascinating people. She walked the busy streets of Tokyo,
hiked the rugged mountains of Nepal, and swam in the crystal-clear waters
of the Caribbean. Along the way, she befriended locals like Akira, Rajesh,
and Maria, each with their own unique stories to tell. Emma's travels took her
to many cities, including New York, Paris, and Hong Kong, where she savored
delicious foods and explored vibrant cultures. No matter where she went,
Emma always found new wonders to discover and memories to cherish."]
]).toDF("text")
Let’s define the names and locations that we seek to match and save them as text files:
# PERSON
person_matches = """
Emma
Akira
Rajesh
Maria
"""
with open('person_matches.txt', 'w') as f:
f.write(person_matches)
# LOCATION
location_matches = """
Tokyo
Nepal
Caribbean
New York
Paris
Hong Kong
"""
with open('location_matches.txt', 'w') as f:
f.write(location_matches)
Spark NLP uses pipelines; below is the short pipeline that we will use to match the entities in the sample text. Notice that the setCaseSensitive parameter is set to False to allow matching of both uppercase and lowercase versions of the words:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, ReadAs
from sparknlp.annotator import (
Tokenizer,
TextMatcher
)
from pyspark.sql.types import StringType
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
# Step 2: Gets the tokens of the text
tokenizer = Tokenizer() \
.setInputCols("document") \
.setOutputCol("token")
# Step 3: PERSON matcher
person_extractor = TextMatcher() \
.setInputCols("document", "token") \
.setEntities("person_matches.txt", ReadAs.TEXT) \
.setEntityValue("PERSON") \
.setOutputCol("person_entity") \
.setCaseSensitive(False)
# Step 4: LOCATION matcher
location_extractor = TextMatcher() \
.setInputCols("document", "token") \
.setEntities("location_matches.txt", ReadAs.TEXT) \
.setEntityValue("LOCATION") \
.setOutputCol("location_entity") \
.setCaseSensitive(False)
pipeline = Pipeline().setStages([document_assembler,
tokenizer,
person_extractor,
location_extractor
])
We fit and transform the dataframe (data) to get the results for the Person entities:
# Fit and transform to get a prediction
results = pipeline.fit(data).transform(data)
# Display the results
results.selectExpr("person_entity.result").show(truncate=False)

Now, fit and transform the dataframe (data) to get the results for the Location entities:
results.selectExpr("location_entity.result").show(truncate=False)

In this example, we created two TextMatcher stages, one matches person names and the other stage matches locations. Once the Spark NLP pipeline is applied to the sample text, any words that match the specified words are extracted.
BigTextMatcher
BigTextMatcher is an extension of the TextMatcher component in Spark NLP that allows users to match and extract patterns of text in very large documents or corpora. It is designed to handle datasets that are too large to fit in memory and provides an efficient way to perform distributed pattern matching and text extraction using Spark NLP.
BigTextMatcher works by taking a set of words or phrases as input and building an efficient data structure to store them. This data structure allows the BigTextMatcher to quickly match the input text against the large set of words or phrases, making it much faster than the TextMatcher for large sets of data.
Let’s work on a similar example to TextMatcher, which extracts person entities from a text. First we have to create a dataframe from a sample text:
# Create a dataframe from the sample_text
data = spark.createDataFrame([
["Natural language processing (NLP) has been a hot topic in recent years,
with many prominent researchers and practitioners making significant
contributions to the field. For example, the work of Karen Smith and
John Johnson on sentiment analysis has helped businesses better understand
customer feedback and improve their products and services. Meanwhile,
the research of Dr. Jane Kim on neural machine translation has revolutionized
the way we approach language translation. Other notable figures in the field
include Michael Brown, who developed the popular Stanford NLP library, and
Prof. Emily Zhang, whose work on text summarization has been widely cited
in academic circles. With so many talented individuals pushing the boundaries
of what's possible with NLP, it's an exciting time to be involved in this
rapidly evolving field."]]).toDF("text")
Now define the names that we want to match and save them as a file:
# PERSON
person_matches = """
Karen Smith
John Johnson
Jane Kim
Michael Brown
Emily Zhang
"""
with open('person_matches.txt', 'w') as f:
f.write(person_matches)
We will use the following pipeline:
# Import the required modules and classes
from sparknlp.base import DocumentAssembler, Pipeline, ReadAs
from sparknlp.annotator import (
Tokenizer,
BigTextMatcher
)
from pyspark.sql.types import StringType
import pyspark.sql.functions as F
# Step 1: Transforms raw texts to `document` annotation
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
# Step 2: Gets the tokens of the text
tokenizer = Tokenizer() \
.setInputCols("document") \
.setOutputCol("token")
# Step 3: PERSON matcher
person_extractor = BigTextMatcher() \
.setInputCols("document", "token") \
.setStoragePath("person_matches.txt", ReadAs.TEXT) \
.setOutputCol("person_entity") \
.setCaseSensitive(False)
pipeline = Pipeline().setStages([document_assembler,
tokenizer,
person_extractor])
We fit and transform the dataframe (data) to get the results for the Person entities:
# Fit and transform to get a prediction
results = pipeline.fit(data).transform(data)
# Display the results
results.selectExpr("person_entity.result").show(truncate=False)

In this example, we created a BigTextMatcher stage, which matches previously defined person names from the text. Once the Spark NLP pipeline is applied to the sample text, those specified words are extracted.
For additional information, please consult the following references:
- Documentation : TextMatcher, BigTextMatcher
- Python Docs : TextMatcher, BigTextMatcher
- Scala Docs : TextMatcher, BigTextMatcher
- For extended examples of usage, see the TextMatcher, BigTextMatcher.
Emerging Trends
Building on these foundations, in 2025 advances in clinical NLP pipelines have shown that transformer-based models, when fine-tuned on biomedical corpora, significantly improve entity recognition for complex medical concepts such as rare diseases, adverse drug reactions, and multi-drug interactions. Hospitals using these models in production report measurable reductions in diagnostic coding errors and faster turnaround for clinical documentation, underscoring the practical value of integrating state-of-the-art NLP into healthcare workflows.
Another important trend is the rise of multimodal information extraction, where text is processed alongside medical images, genomic data, and patient monitoring streams. By combining these sources in a single pipeline, NLP systems can identify richer relationships between clinical notes and structured data, leading to more precise decision support tools. Pilot deployments in oncology and radiology departments have already demonstrated improved accuracy in treatment recommendations when multimodal extraction pipelines are applied at scale.
Finally, the field is rapidly moving toward explainable and compliant NLP systems. Beyond extracting entities and relationships, healthcare organizations now prioritize traceability and regulatory alignment to meet evolving standards for responsible AI. Spark NLP pipelines enhanced with explainability modules allow clinicians to review not only the extracted information but also the reasoning behind it. This ensures that models remain trustworthy, auditable, and adaptable as healthcare regulations expand and patient safety requirements grow stricter.
Conclusion
TextMatcher & BigTextMatcher of Spark NLP enable identifying and extracting previously defined words/phrases from texts. Text matching is particularly useful when there is no clear pattern in the text data that can be captured using regular expressions.
Overall, text matching is an essential tool for anyone working in the field of NLP, and its importance is only likely to grow as the field continues to evolve and expand. By using text matching tools like TextMatcher and BigTextMatcher, data scientists and developers can save time and effort and create more accurate and effective NLP pipelines.
FAQ
What is the main advantage of using Spark NLP for information extraction compared to other NLP libraries?
Spark NLP is designed to be both scalable and production-ready. Unlike many academic frameworks, it runs efficiently on large datasets using Apache Spark, offers over 14,500 pretrained models, and provides out-of-the-box pipelines for healthcare, finance, and other domains.
How is information extraction applied in healthcare today?
Healthcare organizations use information extraction to automatically identify medical terms, diagnoses, drug names, and clinical events from unstructured clinical notes. This improves diagnostic coding, accelerates research, and supports compliance with regulatory reporting requirements.
Can Spark NLP handle multimodal information extraction?
Yes. Spark NLP can be integrated into multimodal pipelines that combine text with medical images, genomic data, or IoT health device outputs. This allows healthcare systems to uncover more precise relationships and deliver better clinical decision support.
How does Spark NLP support explainability and compliance in NLP pipelines?
Spark NLP provides explainability features that allow developers and clinicians to trace model outputs back to their sources. This helps meet transparency requirements in regulated industries, ensuring that NLP-driven insights are auditable and aligned with responsible AI standards.
What are the current trends in information extraction to watch?
Key trends include transformer-based models fine-tuned on biomedical corpora, multimodal pipelines that unify diverse data types, and explainable NLP systems built for compliance. These advances are shaping the next generation of clinical and enterprise applications powered by Spark NLP.




