A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/
Why annotate text documents?
Text annotation is a viral subject in the Machine Learning (ML) field as it represents one of the primary methods for obtaining training & testing data for NLP Deep Learning (DL) models.
It mainly consists in assigning labels to text chunks or to the entire text document according to whether we are interested in Named Entity Recognition (NER), document classification, relation extraction, or other NLP tasks. For instance, when the target is document classification, the entire document is assigned one or several classes (e.g. Food, Sport, Medicine, Finance,…). On the other hand, when the target is the identification of entities mentioned in the text, labels such as Person, Organization, Location, etc. are assigned to specific words or word chunks (sequence of words).
Manually annotated text data can then be used to train DL models that will be able to reproduce the target task for new and unseen documents with a specific accuracy. The accuracy of the predictions is highly dependent on the quality of the training data, which in turn depends on the coherence and completeness of the annotations and the level of agreement between annotators.
NLP DL model training usually requires an important amount of high-quality training data, which is usually not easy to obtain and involves manual annotation or, in the best of cases, manual annotation review.
To make things easier and to speed up the annotation process John Snow Labs offers a FREE Annotation Lab – a tool for human-in-the-loop annotation for all types of documents (text, image, PDF, video, audio), which supports a wide range of annotation tasks: classification, NER, relation extraction, assertion status detection, and summarization. If you work with pdf and other image types, try also image annotation tool from John Snow Labs.
In this blog post, I will illustrate how Annotation Lab can be used to prepare training data for a Food detection NER DL model.
Text pre-annotation using taxonomies and dictionaries
It is often the case that relevant domain knowledge is available in databases, taxonomies, lists, or dictionaries. For instance, in tourism, we can reference lists of places, restaurants, hotels, events, etc. In healthcare, taxonomies of diseases, symptoms, procedures are used extensively, while in the pharma domain, experts often refer to lists of drugs or active substances. In the Food area, many such resources exist and cover fruits, vegetables, spices, meat types, to name a few relevant entities.
How can one take advantage of all that data and use it for speeding up the manual annotation process for NER model training? That’s easy: using Annotation Lab Rules powered by Spark Healthcare NLP. All you need to do is create a new rule, name it to reflect the target entity, load a csv dictionary and save it. Now, this rule is available to use in any project and can be applied to pre-annotate your documents as shown below:

Food data
For this blog post, I used open data from Kaggle – Food Recipe, a dataset containing different salad recipes, and compiled several dictionaries from Wikipedia. The dictionaries used for this example are available on this Git repo. On the same repository, I have published the training datasets – 200 ready to import food recipes.
Environment setup
To deploy Annotation Lab on your infrastructure, please use the one-liner installer available here. The tool is FREE for both personal and commercial use; however, for defining and running Rules you will need a Spark NLP for Healthcare license. You can get a 30 days trial by registering here.
Models and Rules on the Annotation Lab Models Hub
The Models Hub page is the place where users can search for available models and rules and prepare those for use in new projects. All models published in the NLP Models Hub which are compatible with the current version of the Annotation Lab are visible and available for download on the Models Hub page.
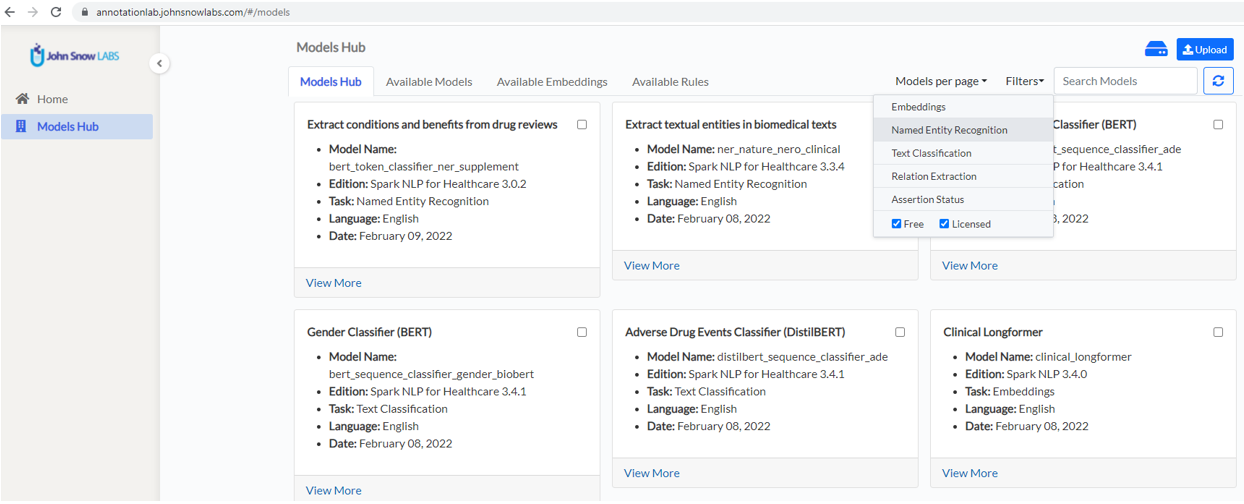
You can use the filtering, search and navigation features to identify the best model for your project, select it and click on the download button to download it on the Annotation Lab machine.
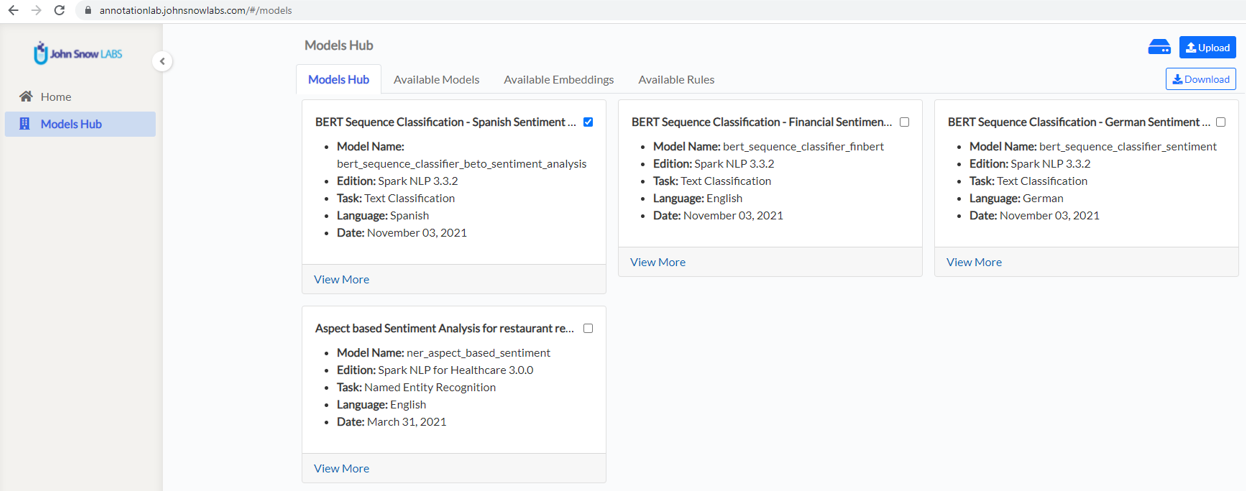
The model and all the labels it predicts will now be available on the Project Configuration àPredefined Labels tab and you can easily add them to your project.
A special page on the Models Hub hosts the available rules.
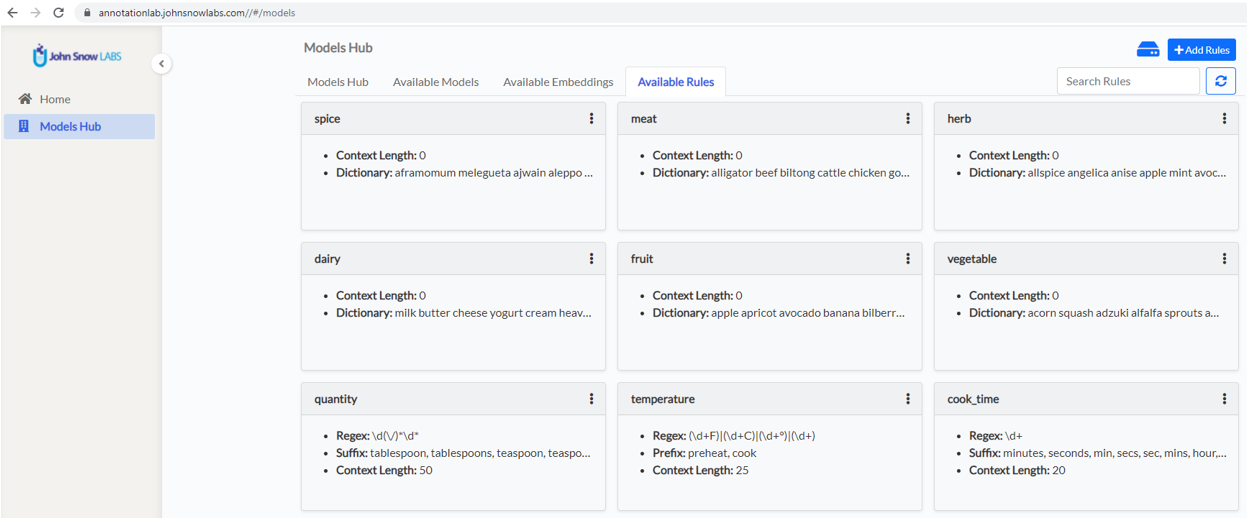
You can see here the rules I have defined for the Food Processing project.
Annotation Lab currently supports two types of rules: Dictionary Based and Regex Based, both of them powered by Spark NLP for Healthcare library via the ContextualParser Annotator. Having said that, using Rules in the Annotation Lab to pre-annotate your documents does not involve any coding whatsoever and does not require data science skills.
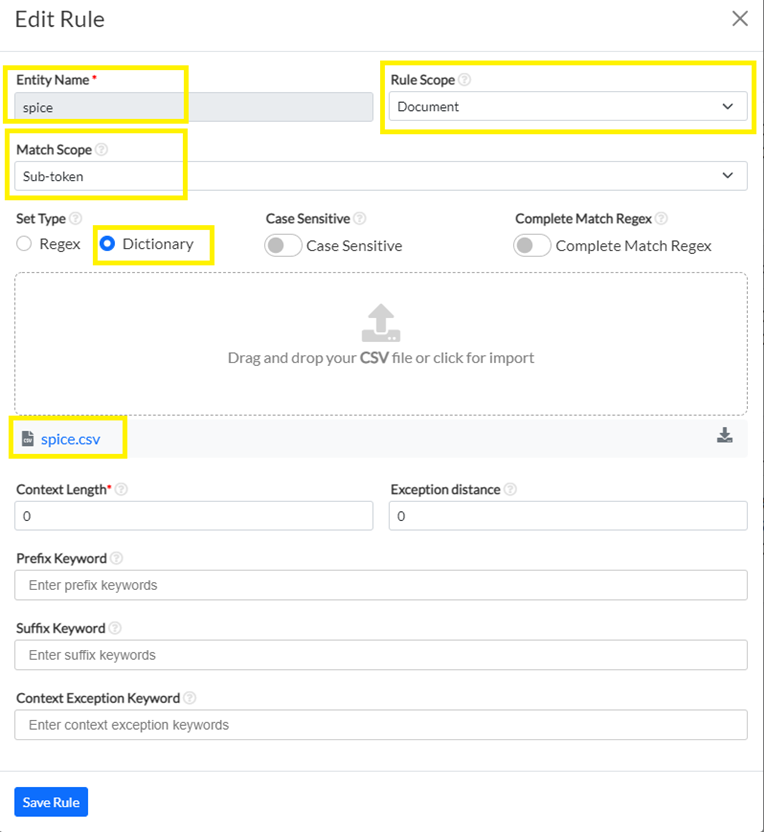
For creating a new rule, use the +Add Rule button, which will open the Rule editor. The first example is a simple dictionary-based rule. It has a name – spice. This will be the name of the label that you can add to your Project taxonomy. All chunks that will be identified using this rule will be labeled as spice.
There are a couple of parameters that define on what text to run the rule, and how to deal with the context for each potential hit.
Rule scope
This parameter can have 2 values: Document and Sentence. When option Sentence is selected, the match is verified for each token of a sentence. When changing it to Document, the match is verified at sentence level, for all sentences of a document/task.
Match Scope
This parameter also has 2 possible values: Token and Sub-token. When Token is selected, only individual token hits (single words) are returned. When Sub-token is selected in combination with Rule Scope: Document, the rule can identify chunks (multi-token texts) or sub-tokens. This is particularly useful when you have multi-word entities such as “black pepper” into your dictionary, or when you want to only extract a subpart of a token. Imagine for instance that you have a temperature expressed as 160F and you only want to extract 160. In this case, you define your number identification regex and select Sub-token Match Scope for your rule.
Case Sensitive
When Case Sensitive option is on, the matching for all rule elements except for regexes – dictionary values, prefix, and suffix keywords and exceptions keywords – will be case sensitive.
Complete Match Regex
When activated, this option will enforce a complete match for the given regex. In other words, if your regex only partially covers a token, that will not be considered a hit.
Examples: Spice and Quantity rules
For the spice rule, I am using a dictionary that also includes multi-word entries, so I chose Sub-token Match Scope and Document for Rule Scope.
I do not want to add any context for this simple rule, I do not care about uppercase words so I just save it and it will appear on my Rule page.
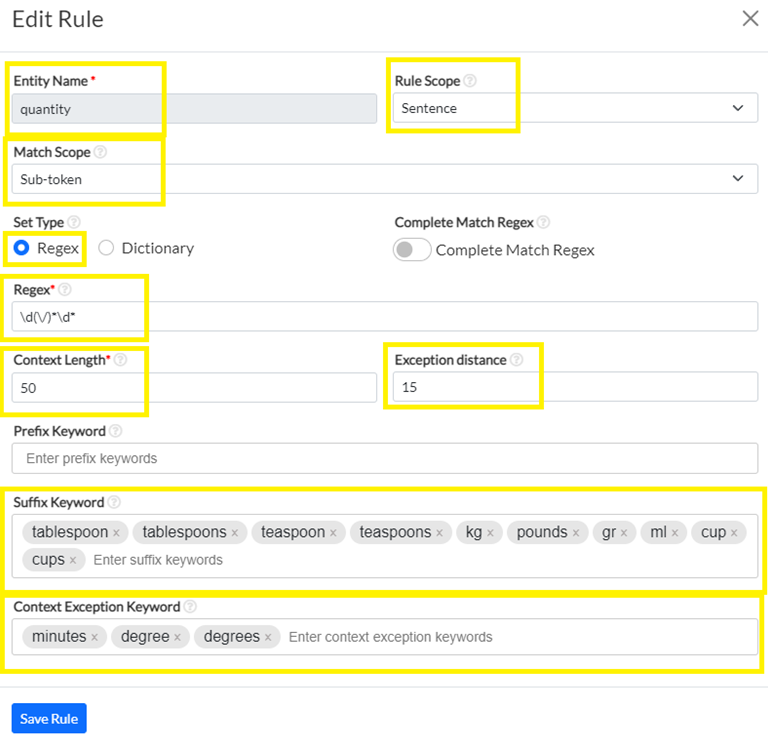
Another example of a rule for identifying quantities is shown below. For this, I used a regex-based rule, with a simple regex to detect a number and some context to refine the meaning of the identified number. The context is specified as a list of words to search for in the text section following the hit up to 50 characters (suffix). In this case, I have also defined a list of words that should not appear near the hit at a distance of max 15 characters before or after the hit candidate. This is for eliminating the chunks that express cooking temperature.
Following the same line of thinking I have defined in total 9 rules that cover meat, dairy, vegetables, fruits, herbs, spices, cooking time, cooking temperature, and quantities.
In general, defining those rules is an iterative process the same as for the definition of Annotation Guidelines. You start from a minimal set of conditions, contexts, exceptions and keep on adding as you run into new cases.
What’s next?
After preparing the first version of your rules, and downloading the models you want to reuse you can create your project and import the documents you want to annotate. This is covered in part 2 of this tutorial.