Stopwords removal in natural language processing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Removing stop words is useful...
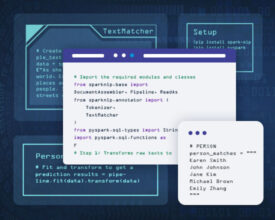
How to extract entities from text based in a list of desired entities or regex rules using Spark NLP at scale Named Entity recognition can be implemented with many approaches....
Become a master of text classification with Spark NLP’s comprehensive guide Text classification is the process of assigning a category or label to a piece of text, such as an...
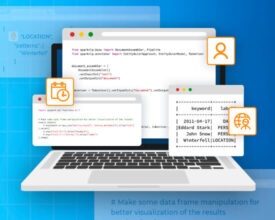
Extract Hidden Insights from Texts at Scale with Spark NLP Information extraction in natural language processing (NLP) is the process of automatically extracting structured information from unstructured text data. Spark...
Sentence detection in Spark NLP is the process of identifying and segmenting a piece of text into individual sentences using the Spark NLP library. Sentence detection is an essential component...

































































 See More
See More