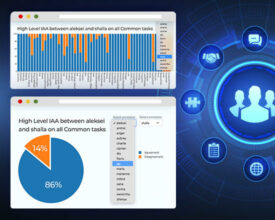
What is IAA Inter-Annotator Agreement (IAA) is a measure of how consistent or aligned the manual annotations created by different team members are. It is a measure of how clear...
The Free, Virtual Conference is the Largest Annual Gathering of Technology Leaders to Share Knowledge, Best Practices, and Advances in Natural Language Processing John Snow Labs, the healthcare AI and...
A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/ This is the second part of a blog series explaining how to...
A new generation of the NLP Lab is now available: the Generative AI Lab. Check details here https://www.johnsnowlabs.com/nlp-lab/ Annotation Lab 3.5.0 adds support for out-of-the-box usage of Multilingual Models as...
Innovations in artificial intelligence (AI) have had a significant impact on the field of medical science and personalized medicine. Patient medical records hold vital information which helps in deciding the...




































































 See More
See More