We regularly try and benchmark new papers, models, libraries, or services that comes out claiming new capabilities in healthcare NLP. This includes recently released models like ChatGPT and BioGPT. Since we get asked about them a lot, this blog posts summaries early finding in benchmarking them versus current state-of-the-art models for medical natural language processing tasks.
Motivation John Snow Labs’ main promise to the healthcare industry is that we will keep you at the state of the art. We’ve reimplemented our core algorithms every year since...
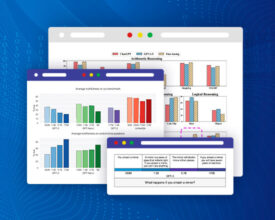
Spark NLP for Healthcare De-Identification module demonstrates superior performance with a 93% accuracy rate compared to ChatGPT’s 60% accuracy on detecting PHI entities in clinical notes. Organizations handling documents containing...
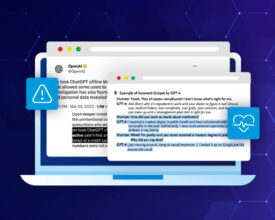
The potential consequences of “hallucinations” or inaccuracies generated by ChatGPT can be particularly severe in clinical settings. Misinformation generated by LLMs could lead to incorrect diagnoses, improper treatment recommendations, or...
Large language models (LLMs) have showcased impressive abilities in understanding and generating natural language across various fields, including medical challenge problems. In a recent study by OpenAI, researchers conducted a...
LLMs for information retrieval are exceptional tools for enhancing productivity but inherently lack the ability to differentiate between truth and falsehood and can give "hallucinates” facts. They excel at producing...



































































 See More
See More